




Python爬虫实践:数据抓取、清洗与可视化
PDF格式 | 951KB |
更新于2024-08-26
| 159 浏览量 | 举报
本篇资源主要讲述了Python爬虫技术在获取并分析前程无忧网站上的大数据职位信息的过程,同时结合了数据可视化的重要性。首先,通过Python爬虫技术,作者使用`requests`库模拟浏览器访问,利用`RequestHeaders`来复制浏览器发送的请求头信息,避免IP被封禁,尽管前程无忧通常不会对爬虫采取措施。爬虫功能设计为交互式,允许用户输入想了解的职位,从而获取相关职位详情,包括职位链接和公司链接。
数据抓取阶段,作者使用了Excel作为数据存储工具,通过双层循环实现多页数据的爬取和整洁的输出。在数据预处理阶段,作者强调了清洗数据的重要性,包括处理空值、错误职位信息、错误格式和统一薪资单位等。例如,对于单位不一致的问题,需要进行相应的转换。
数据可视化部分则是文章的重点,通过`pyecharts`库,作者构建了一系列图表来呈现数据。具体操作包括:
1. 利用`pyecharts`中的不同图表类型,如薪资与工作经验的关系图、学历要求的圆环图,以及大数据在各城市的分布情况(地理位置图)。
2. 通过`matplotlib`生成工作经验漏斗图,展示职位需求的层级结构。
3. 鼓励读者探索更多的pyecharts图表功能,以便深入分析数据。
此外,作者提到由于网站规则的变化可能导致数据抓取过程中出现乱码问题,他们已经进行了代码更新以解决这个问题。
这篇文章不仅涵盖了Python爬虫技术的基本操作,还展示了如何通过数据清洗和可视化提升数据分析的价值,适合对数据挖掘和Python爬虫有兴趣的读者学习和实践。
Python爬虫与数据可视化爬虫与数据可视化
1.数据挖掘
代码所需包
进入前程无忧官网
我这里以搜索大数据职位信息
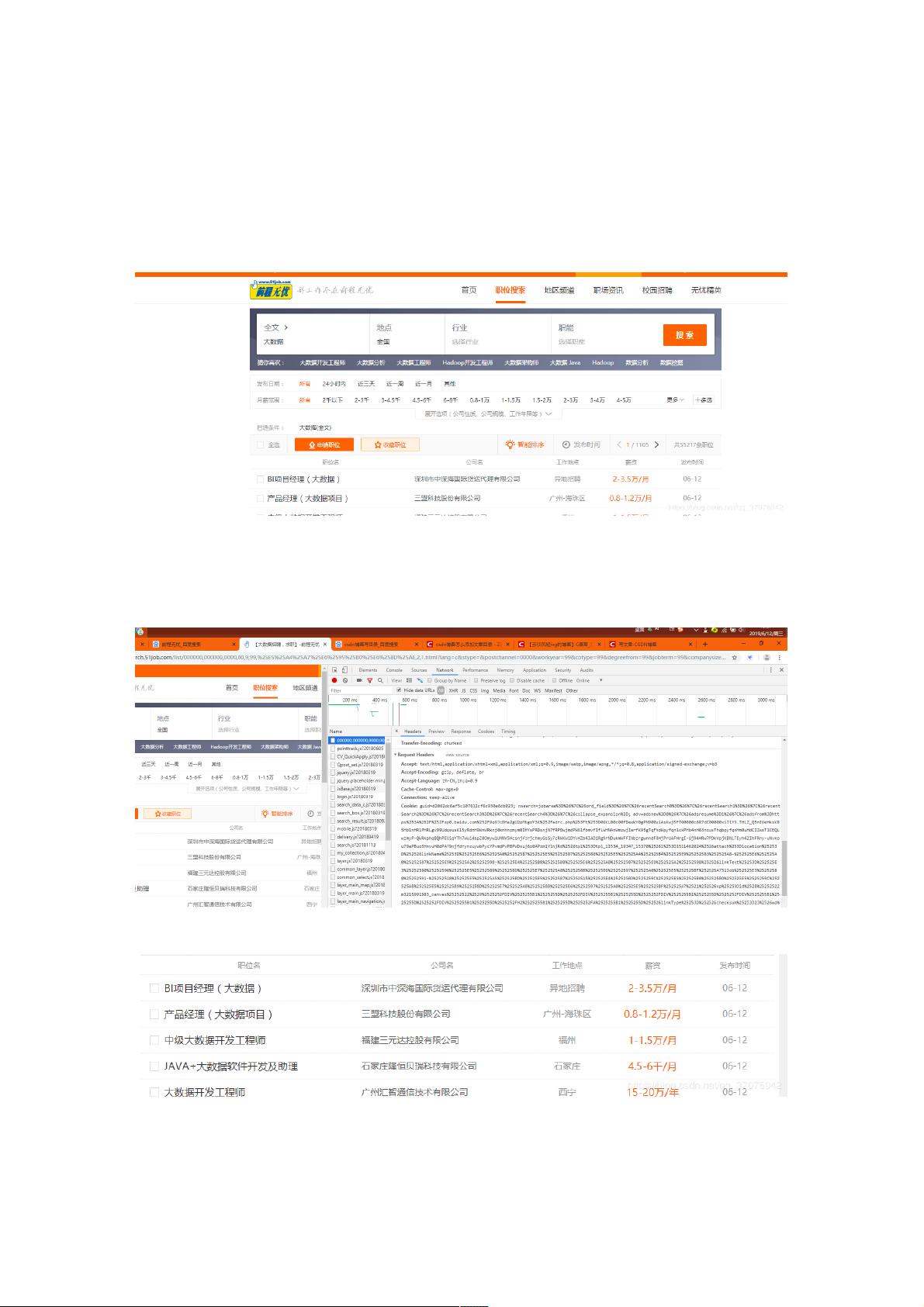
打开开发者模式
Request Headers 里面是我们用浏览器访问网站的信息,有了信息后就能模拟浏览器访问
这也是为了防止网站封禁IP,不过前程无忧一般是不会封IP的。
模拟浏览器
这些基本数据都可以爬取:
为了实现交互型爬取,我写了一个能够实现输入想了解的职位就能爬取相关内容的函数
这里我除了爬取图上信息外,还把职位超链接后的网址,以及公司超链接的网址爬取下来了。
这里先不讲,后面后面会说到,
下载后可阅读完整内容,剩余7页未读,立即下载
相关推荐

235 浏览量






weixin_38690149
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- C# 三层架构代码自动生成工具及UI简化指南
- 艾讯科技ED系列以太网交换机参数详细介绍
- 深入解析比较器电路设计与应用
- SSH Secure Shell Client 3.2.9:服务器文件上传下载解决方案
- 虚拟机环境下FastDFS安装包部署指南
- STM32F107系列中文参考手册及以太网模块设计
- 利用jQuery Ajax实现ASP.NET文件上传功能
- OneBusAway-GTFS模块合并工具开源项目介绍
- 淘宝电商客服流程图解与培训手册
- 基于VC和MFC的远程控制程序实现教程
- 10K小工具实现精确的定时关机功能
- Linux系统下的软件配置安装指南
- 深入解析半桥式电路设计技术资料
- ThinkAjax技术实现Ajax的简易指南
- 艾讯科技EX交换机选型参数详细介绍
- DIE:英文版高级PE壳检测工具评测










