改进的图神经网络:Gated Graph Sequence Networks在多领域应用与程序验证中的性能
需积分: 23 79 浏览量
更新于2024-07-16
收藏 741KB PDF 举报
GATED GRAPH SEQUENCE NEURAL NETWORKS (GGNNs) 是一篇在2016年国际计算机视觉与模式识别会议(ICLR)上发表的研究论文。论文关注于图结构数据的学习,这种数据在诸如化学、自然语言处理、社交网络和知识库等多个领域中非常常见。作者们对Graph Neural Networks(GNNs)进行了深入研究,这些网络最初由Scarselli等人在2009年提出,但本工作在此基础上进行了创新。
GNNs的核心改进在于引入了门控循环单元(Gated Recurrent Units, GRUs),这是一种在序列建模中广泛应用的自回归单元,它有助于更好地处理图的动态性和时序信息。同时,作者还采用了现代优化技术来提升模型的训练效率和性能。通过这些改进,GGNNs提供了一种更为灵活且具有针对性的模型,特别是在处理图结构问题时,相较于纯序列模型(如长短时记忆网络,LSTM),它拥有更优的归纳偏差,即对输入数据的潜在结构模式有更好的捕捉能力。
论文作者首先展示了GGNNs在简单人工智能任务(如bAbI)和图算法学习任务中的应用,证明其在处理此类问题时能够有效地提取和学习特征。随后,他们进一步证明了GGNNs在程序验证领域的显著优势,该领域需要模型能理解并描述子图作为抽象数据结构,这对于程序理解和调试至关重要。在这个特定的程序验证问题上,GGNNs达到了当时最先进的性能,显示了其在实际应用中的强大能力。
GATED GRAPH SEQUENCE NEURAL NETWORKS通过结合GNN的图结构理解和GRU的时序处理,构建了一种强大的模型框架,不仅适用于传统的序列数据,也适用于复杂图数据的学习和预测。这对于推进图神经网络的发展和在更广泛的领域中解决实际问题具有重要意义。
Published as a conference paper at ICLR 2016
3
4
1
2
h
(t1)
2
h
(t1)
1
h
(t1)
3
h
(t1)
4
h
(t)
4
h
(t)
3
h
(t)
2
h
(t)
1
B
C
C
B
1
2
3
4
1 2 3 4
Outgoing Edges
B’ C’
C’
B’
1 2 3 4
Incoming Edges
| {z }
| {z }
(a) (b) (c) A =
A
(out)
, A
(in)
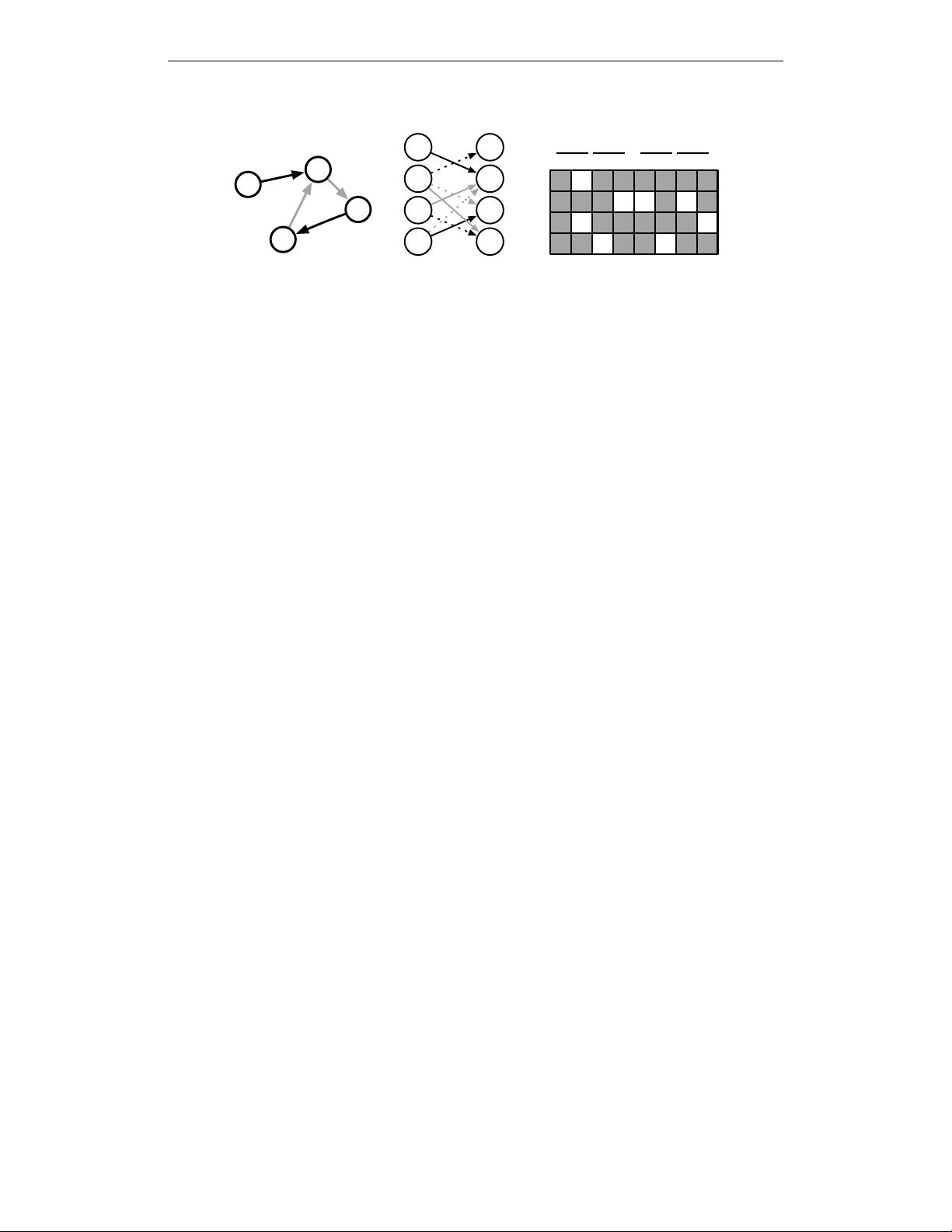
Figure 1: (a) Example graph. Color denotes edge types. (b) Unrolled one timestep. (c) Parameter
tying and sparsity in recurrent matrix. Letters denote edge types with
B
0
corresponding to the reverse
edge of type B. B and B
0
denote distinct parameters.
The matrix
A ∈ R
D|V|×2D|V|
determines how nodes in the graph communicate with each other. The
sparsity structure and parameter tying in
A
is illustrated in Fig. 1. The sparsity structure corresponds
to the edges of the graph, and the parameters in each submatrix are determined by the edge type
and direction.
A
v:
∈ R
D×2D|V|
is the submatrix of
A
containing the rows corresponding to node
v
. Eq. 1 is the initialization step, which copies node annotations into the first components of the
hidden state and pads the rest with zeros. Eq. 2 is the step that passes information between different
nodes of the graph via incoming and outgoing edges with parameters dependent on the edge type
and direction.
a
(t)
v
∈ R
2D
contains activations from edges in both directions. The remaining are
GRU-like updates that incorporate information from the other nodes and from the previous timestep
to update each node’s hidden state.
z
and
r
are the update and reset gates,
σ(x) = 1/(1 + e
−x
)
is the
logistic sigmoid function, and
is element-wise multiplication. We initially experimented with a
vanilla recurrent neural network-style update, but in preliminary experiments we found this GRU-like
propagation step to be more effective.
3.3 OUTPUT MODELS
There are several types of one-step outputs that we would like to produce in different situations. First,
GG-NNs support node selection tasks by making
o
v
= g(h
(T )
v
, x
v
)
for each node
v ∈ V
output node
scores and applying a softmax over node scores. Second, for graph-level outputs, we define a graph
level representation vector as
h
G
= tanh
X
v∈V
σ
i(h
(T )
v
, x
v
)
tanh
j(h
(T )
v
, x
v
)
!
, (7)
where
σ(i(h
(T )
v
, x
v
))
acts as a soft attention mechanism that decides which nodes are relevant to the
current graph-level task.
i
and
j
are neural networks that take the concatenation of
h
(T )
v
and
x
v
as
input and outputs real-valued vectors. The tanh functions can also be replaced with the identity.
4 GATED GRAPH SEQUENCE NEURAL NETWORKS
Here we describe Gated Graph Sequence Neural Networks (GGS-NNs), in which several GG-NNs
operate in sequence to produce an output sequence o
(1)
. . . o
(K)
.
For the
k
th
output step, we denote the matrix of node annotations as
X
(k)
= [x
(k)
1
; . . . ; x
(k)
|V|
]
>
∈
R
|V|×L
V
. We use two GG-NNs
F
(k)
o
and
F
(k)
X
:
F
(k)
o
for predicting
o
(k)
from
X
(k)
, and
F
(k)
X
for
predicting
X
(k+1)
from
X
(k)
.
X
(k+1)
can be seen as the states carried over from step
k
to
k + 1
.
Both
F
(k)
o
and
F
(k)
X
contain a propagation model and an output model. In the propagation models,
we denote the matrix of node vectors at the
t
th
propagation step of the
k
th
output step as
H
(k,t)
=
[h
(k,t)
1
; . . . ; h
(k,t)
|V|
]
>
∈ R
|V|×D
. As before, in step
k
, we set
H
(k,1)
by
0
-extending
X
(k)
per node. An
overview of the model is shown in Fig. 2. Alternatively,
F
(k)
o
and
F
(k)
X
can share a single propagation
model, and just have separate output models. This simpler variant is faster to train and evaluate, and
4
剩余19页未读,继续阅读
点击了解资源详情
2024-12-21 上传
2024-12-21 上传
2024-12-21 上传
2024-12-21 上传
2024-12-21 上传
2024-12-21 上传
2024-12-21 上传
2024-12-21 上传

sidfj
- 粉丝: 0
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- tmux-networkspeed:用于生成网络速度的 bash 脚本,用于 tmux 状态行
- 易语言简易注册收费系统源码
- Laravel
- Live Learning Screenshare-crx插件
- Code--Salaire:TP POO
- 易语言-易语言GDI+例程 学习画笔应用
- genesis-boxed:我基于Genesis Sample的入门主题的盒装版本
- 新冠肺炎
- Evaluation-Metrics-Package-Tensorflow-PyTorch-Keras
- promykowa_apka
- code-challenges:谈话很便宜,请告诉我代码! 用Java,Ruby和JavaScript完成的编码挑战
- trapifier.py:使音频真棒
- 亚马逊简单
- cuda_wrapper-开源
- php-check:检查您的代码是否存在语法错误和错误
- firmware_vault:所有Apple EFI固件文件的存储库
