




基于SVMDTW的语音识别技术及DSP实现
版权申诉
"该文档主要探讨了基于支持向量机动态时间规整(SVMDTW)算法的语音识别技术,并介绍了其在数字信号处理器(DSP)上的实现。文档首先概述了语音识别的重要性以及在多个领域的广泛应用,然后分析了国内外语音识别的发展现状,提出了相应的语音识别算法,并强调了改进算法在语音识别系统中的核心地位。接下来,详细阐述了语音识别系统中的关键步骤,包括预加重、窗口截取、端点检测、特征提取等,重点介绍了DTW算法及其优化,以及支持向量机(SVM)算法。此外,还提到了参数优化算法,如网格搜索方法和遗传算法(GA),以及这些算法如何提升语音识别的性能。最后,文档可能涉及了在硬件和软件层面的系统仿真。"
这篇文档深入探讨了人工智能领域中的语音识别技术,特别是基于SVMDTW算法的实现。语音识别作为模式识别的一个分支,经过数十年的发展,已经在工业、军事、交通、医疗等多个领域取得了显著突破,特别是在信息处理和电子通信系统中的应用日益广泛。随着技术的进步,语音识别产品层出不穷,应用场景也更加广泛。
在技术层面,文档首先介绍了语音信号处理的基本步骤,包括预加重以消除低频噪声、使用窗口函数对语音信号进行分帧处理,以便于分析,以及端点检测来确定语音的起始和结束位置。这些步骤为后续的特征提取奠定了基础。特征提取是语音识别的关键,它通常涉及梅尔频率倒谱系数(MFCC)等特征参数的计算。
接着,文档详细讨论了动态时间规整(DTW)算法,这是一种用于比较不同长度序列的匹配算法,特别适合处理语音这种非线性变化的数据。通过DTW,可以找到两个序列的最佳匹配路径,从而实现语音模板的比对。为了提高识别效率和准确性,文档还提到了对DTW的改进策略。
支持向量机(SVM)作为一种强大的分类工具,在语音识别中也有广泛应用。SVM通过构建超平面将不同类别的样本分开,能够处理高维特征空间,且具有较好的泛化能力。文档中提到了参数优化,包括网格搜索和遗传算法,这些方法用于寻找最佳的SVM模型参数,以提升识别性能。
最后,文档还讨论了系统在硬件和软件层面的实现,这通常涉及到DSP的利用,因为DSP具有高效处理数字信号的能力,适合执行复杂的语音识别算法。通过仿真,可以评估和优化整个系统的性能。
这篇文档为读者提供了一个全面的理解,关于如何利用SVMDTW算法进行语音识别,并在实际硬件平台上实现这一技术的详细过程。这对于从事相关领域的研究人员和工程师来说,是一份宝贵的参考资料。
基于 SVM/DTW 算法的语音识别研究及其 DSP 实现
9
预加重处理一般是在语音信号数字化之后,用预加重数字滤波器来实现,该滤
波器具有6dB/ 倍频的高频特性提升能力,将语音信号输入一个一阶的高通滤波器:
H(z)=1−μz
−1
(2-2-1)
式中μ 值(预加重系数)接近于1,取值范围在0.9到1之间。
经过预加重处理后的语音信号,其高频部分可与中频部分(1-2kHZ)的幅度相
当,这个过程可以用公式表示:
y(n)=x(n)-0.975x(n-1) (2-2-2)
其中y(n)和x(n)分别为预加重前后的信号
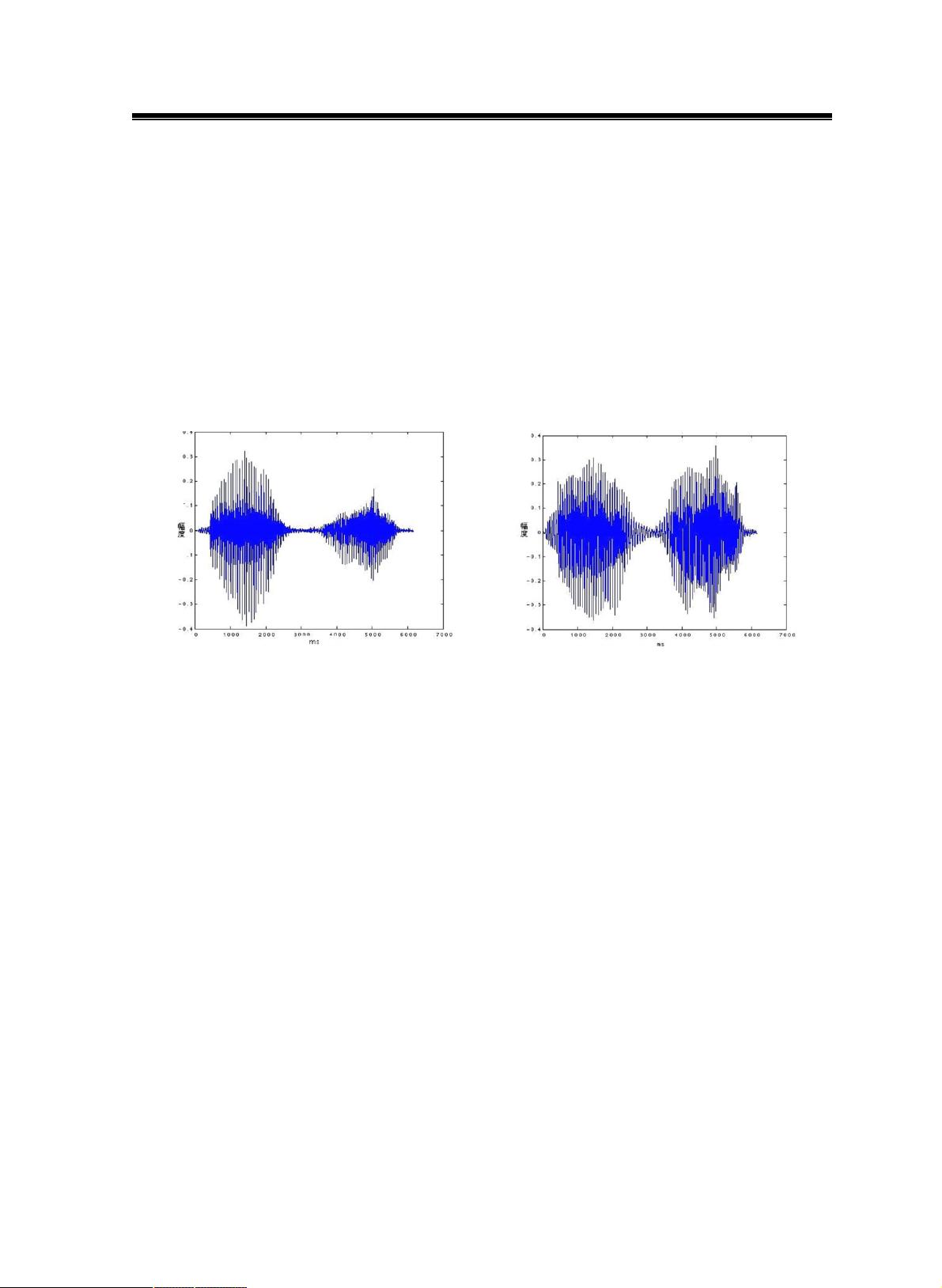
图2.2为语音信号预加重前后的时域波形图。
图2.2 预加重前后的信号比较
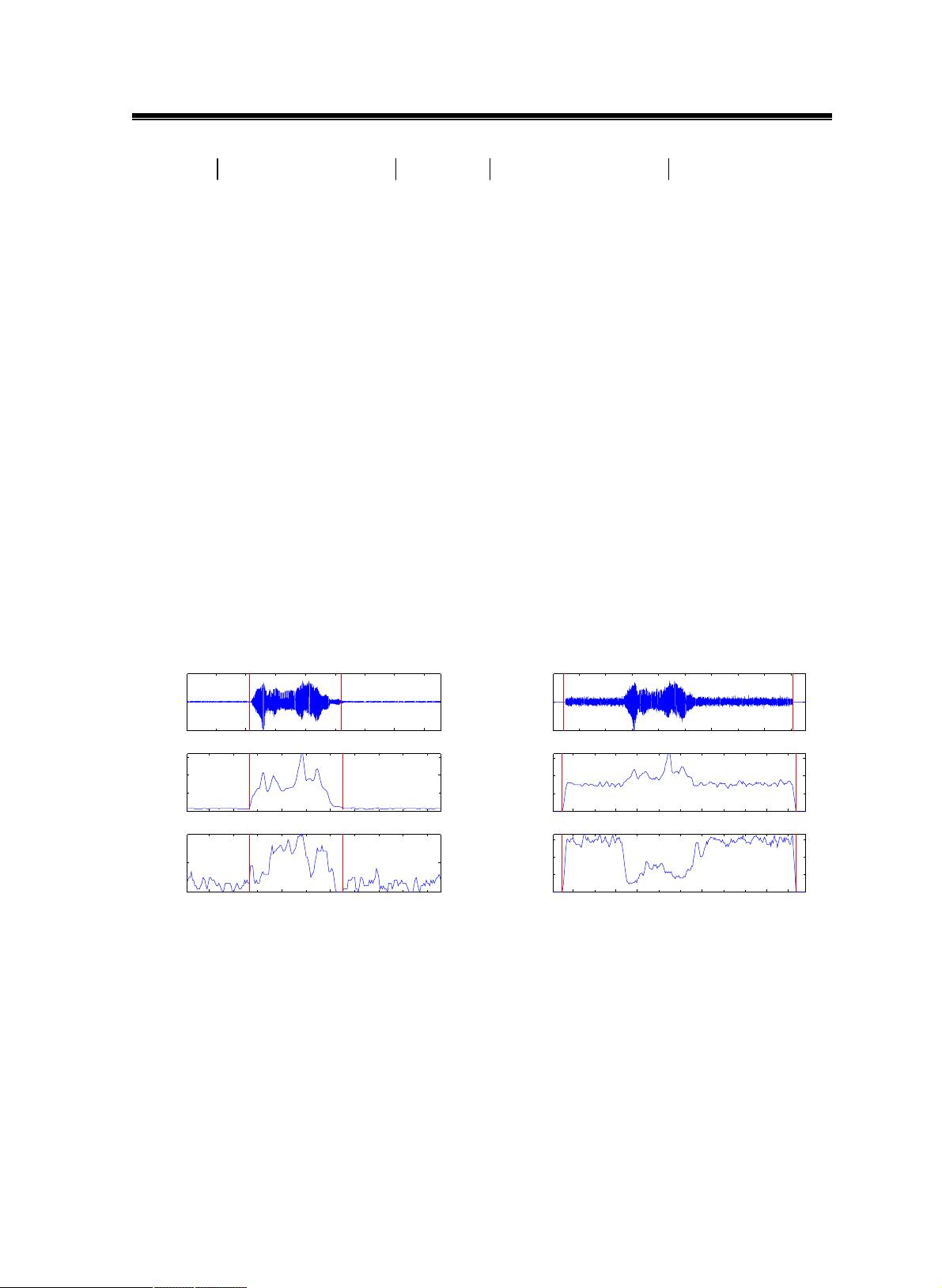
§2.2.2 加窗分帧
一般采用有限长度的窗函数来截取语音信号形成分帧,在区域之外,窗函数w(n)
将待处理的样本点全部置零,以获得当前语音帧。对已取出的一帧语音s(n)进行加窗
处理,就是用一定的窗函数w(n)来乘以s(n),得到加窗后的语音s
w
(n):
( ) ( ) ( ) 0 1
w
s n s n w n n N
(2-2-3)
在语音信号数字处理中常用的窗函数是矩形窗和汉明窗
[23]
,它们的定义如下
(N为帧长):
矩形窗:
1 0 ( 1)
( )
0
n N
n
,
, 其他
(2-2-4)
汉明窗:
0.54 0.46cos[2 /( 1)], 0 1
( )
0,
n N n N
n
其他
(2-2-5)
用一个窗函数对采集数据进行滑动截断,每个短时的语音段称为一个分析帧。
分析帧一般采用如图2.3所示的交叠分段的方法,这是为了使帧与帧之间平滑过渡,


剩余72页未读,继续阅读
130 浏览量
121 浏览量
104 浏览量
2023-07-11 上传
313 浏览量
192 浏览量
195 浏览量
225 浏览量
219 浏览量

programhh
- 粉丝: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索压缩包子技术的核心:qymkwgup
- 使用AWS SAM部署无服务器RESTful API实例
- STC89C51单片机电子密码锁设计及串行通信应用
- 水晶风格PPT图表素材下载 - 流程图和说明图集锦
- 蔡起水Java代码实例解析及应用
- 实现duilib列表头拉伸与项动态移动的RichList Demo
- 使用Kotlin开发的ComposeMoviesApp项目
- Calmery-chan相机项目指南与开发环境搭建
- Blazeblue Crosstag Battle壁纸增强Chrome新标签页体验
- 室内农业机器人AgroBot:自主导航与2D SLAM映射技术
- 利用艾宾浩斯曲线计算Excel内插值方法
- 掌握易语言:API获取磁盘信息及格式化大小方法
- EmailExtractor:从HTML中提取电子邮件地址的工具
- Java大厂面试必备:技术要点与常见问题详解
- 创新箭头穿透PowerPoint关系图设计模板下载
- JavaScript开发的太空相位器游戏解析





















