Logistic回归模型与分类
需积分: 9 140 浏览量
更新于2024-09-12
收藏 678KB PDF 举报
"M_logistic分界线由来——Logistic回归模型及其应用"
Logistic回归是一种统计分析方法,主要用于处理因变量为分类数据的情况,特别是二分类问题。它的起源在于解决当因变量的概率分布呈现S型曲线(sigmoid函数)时,如何通过线性模型来描述自变量与因变量之间的关系。这种曲线形状使得Logistic回归能够预测一个事件发生的概率,而不是连续的数值。
1.1 Logistic回归介绍
Logistic回归模型的核心在于它能够将线性组合(β0 + β1x1 + β2x2 + ... + βkxk)转换为介于0和1之间的概率值。这个转换过程通过sigmoid函数完成,即:
Pr(G=1|X=x) = 1 / (1 + e^(-f(x)))
其中,f(x) = β0 + β1x1 + β2x2 + ... + βkxk 是线性部分,β0、β1、...、βk是待估计的参数。Sigmoid函数的特性使得输出始终在0到1之间,这正好对应了概率的取值范围。
1.2 Logit变换与最大似然估计
Logistic回归中的分界线,或者说决策边界,是由logit变换定义的:
z = log[Pr(G=1|X=x) / Pr(G=2|X=x)] = β0 + β1x
这里的z是log odds,即两个类别的对数优势比。通过最大化似然函数,我们可以估计出参数β0、β1、...、βk的值。这种方法称为最大似然估计,它在许多统计模型中都是一种常用的参数估计方法。
1.3 LDA与Logistic回归的对比
线性判别分析(LDA)在处理分类问题时,假设因变量服从正态分布,并且不同类别间的协方差矩阵相同。LDA的决策边界是基于后验概率的logit转换等于0。然而,Logistic回归不依赖于这些假设,它可以处理非正态分布的数据,因此具有更广泛的应用场景。
1.4 应用场景
Logistic回归在很多领域都有应用,比如医学研究中的疾病预测、市场分析中的购买行为预测、社会科学中的态度调查分析等。它能够捕捉自变量与因变量之间的非线性关系,同时提供概率预测,这对于理解变量间的影响和做出决策非常有用。
M_logistic分界线是Logistic回归模型中的一个重要概念,它通过非线性的logit变换,为分类问题提供了有效的解决方案。通过对参数的最大似然估计,Logistic回归能够适应各种复杂的数据分布,成为处理分类问题的一种强大工具。
度可能是和緩的, 也有些是比較陡峭的。 例如生物細胞受電壓的激發, 其電壓大小與激
發與否的關係也是如此, 不 過中間轉換曲線比較直聳, 有點像 step function, 一般也
叫做 sigmoid function。 式 (2) 亦稱為 log odds ratio(對數優勢比)。 將優勢比取對
數後對 x 作多項式迴歸稱為 Logistic Regression。 當 k = 1 時,x 與 z 的關係變成
簡單的線性模式。 這種透過變數的轉換將較複雜的模式 (1), 變為簡單的模式是迴歸分
析常見的手段, 所謂 「山不轉, 路轉。」 不管對因變數或自變數都可以。
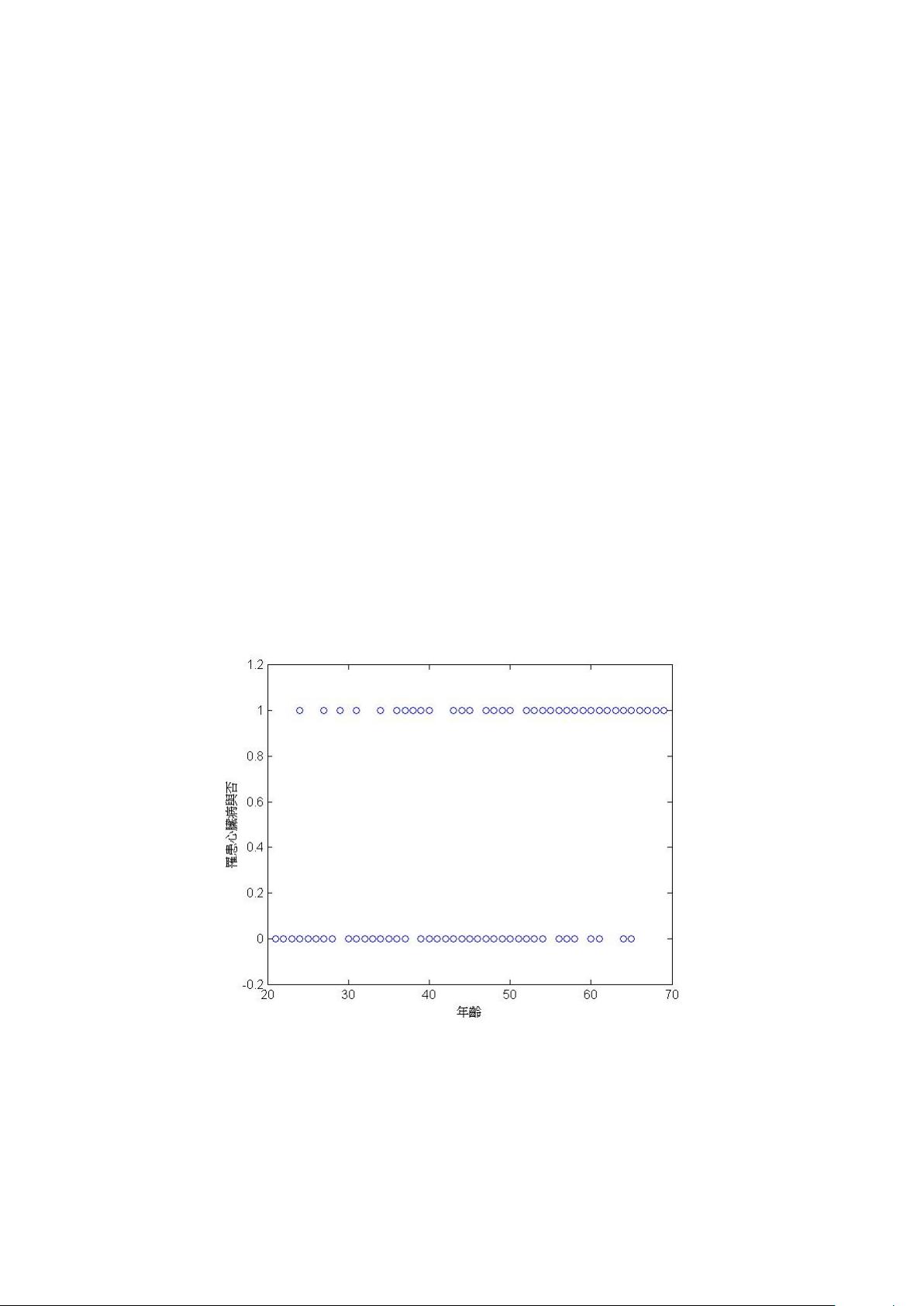
式 (1) 的後驗機率也可以解讀 為 「成功的比例,」 是一個遞增函數, 兩端是近乎穩 定
平緩 的水平線, 中間部分變化較大。 譬如 x 與 P r(G = 1|X = x) 代表年 齡與罹
患心臟病比例, 雖兩者的關係是一平滑連續的漸增曲線, 即年齡越大罹患心 臟病的比
例越高, 不過當進行實際資料的蒐集時, 原始資料僅呈現年齡 (X) 與罹患心臟病與否
(Y) 的二元性數據 (0或 1), 如圖 2所示, Y可視為伯努力分配的 變數, 其成功比例為
P r(G = 1|X = x) 。
圖 2: 年齡與罹患心臟病的調查結果
當拿 X 與二元性資料 Y 作 Logistic Regression 時, 一般採 maximum likelihood
3
剩余12页未读,继续阅读
1902 浏览量
127 浏览量
180 浏览量
127 浏览量
2022-07-15 上传
2022-09-14 上传
2022-07-14 上传
2022-07-15 上传
147 浏览量

Tinaty
- 粉丝: 0
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 访问摄像头源码20210328.zip
- 饮水公司ISO900体系审核——不合格品统计分析表
- mysql-plugin-proc-vars:mysql信息插件显示每个进程的所有变量
- MonopolyDealBot:这是一个不受欢迎的机器人,可以玩流行的纸牌游戏“ Monopoly Deal”。 这是我的第一个不和谐机器人
- ips-lang-polish-axen-advanced-serverlist
- final_dbms_project
- 服务WEB_CRUD
- 供应商如何对抗大卖场的霸王合同DOC
- 中国智能手机市场一月数据分析:手机销量享春节红利,苹果手机份额回升.zip
- skicie
- python设置樱花教程-用来学习很好.zip
- 中国分类信息网站超强版
- Connect-4:这是著名游戏“ Connect 4”的实现
- python-review:遵循FreeCodeCamp的Youtube教程对基本python语法的回顾
- xssValidatorTestCases:xssValidator Burp 扩展的一组测试用例脚本
- 工厂生产及质量培训——中文工管培训教案
