支持向量机:分类与回归的实用方法
需积分: 9 73 浏览量
更新于2024-07-26
收藏 444KB PDF 举报
本文档深入探讨了支持向量机(Support Vector Machines, SVM)在分类(Support Vector Classification, SVC)和回归(Support Vector Regression, SVR)任务中的应用。作者Steve Gunn于1998年5月14日撰写,针对ImageSpeechandIntelligentSystemsGroup,旨在介绍和支持向量机的基本理论和实践。
在第1章中,介绍了统计学习理论(Statistical Learning Theory),其中着重讨论了维数复杂度(VCDimension)的概念,以及结构风险最小化(Structural Risk Minimisation)原则,这是SVM选择模型的关键指导原则。维数复杂度解释了在高维度特征空间中,如何通过找到最优决策边界来控制模型的泛化能力。
第2章详细讨论了支持向量分类,包括找到最优分隔超平面的过程。通过线性可分和非线性可分示例,阐述了如何处理不同情况。特别地,通过多项式映射(Polynomial Mapping)展示了如何将低维数据转换到高维空间以实现非线性分类。此外,讨论了高维特征空间的泛化优势和不同的核函数(如多项式、高斯径向基函数、指数径向基函数等)的应用。
第3章进一步探讨了特征空间的构建和选择。这里介绍了各种常用的核函数及其作用,比如多层感知器(Multi-Layer Perceptron)、傅立叶级数、样条和B-splines等,这些都可以作为内核函数的实例。同时,区分了隐式偏置(Implicit Bias)和显式偏置(Explicit Bias),并强调了数据标准化(Data Normalisation)对性能的影响。选择合适的核函数是优化SVM性能的重要步骤。
第4章以鸢尾花(IRIS)数据集为例,展示了支持向量机在实际分类问题中的应用,展示了其在多种场景下的实用性和有效性。
第5章转向支持向量回归(SVR),介绍了线性回归的基本概念,以及如何通过SVM扩展到回归问题,以便进行连续变量的预测。
这份报告为理解和支持向量机在分类和回归任务中的核心原理,提供了全面且深入的讲解,适合对机器学习有兴趣的读者深入研究。通过理解这些内容,可以更好地设计和优化SVM模型以适应不同领域的实际问题。
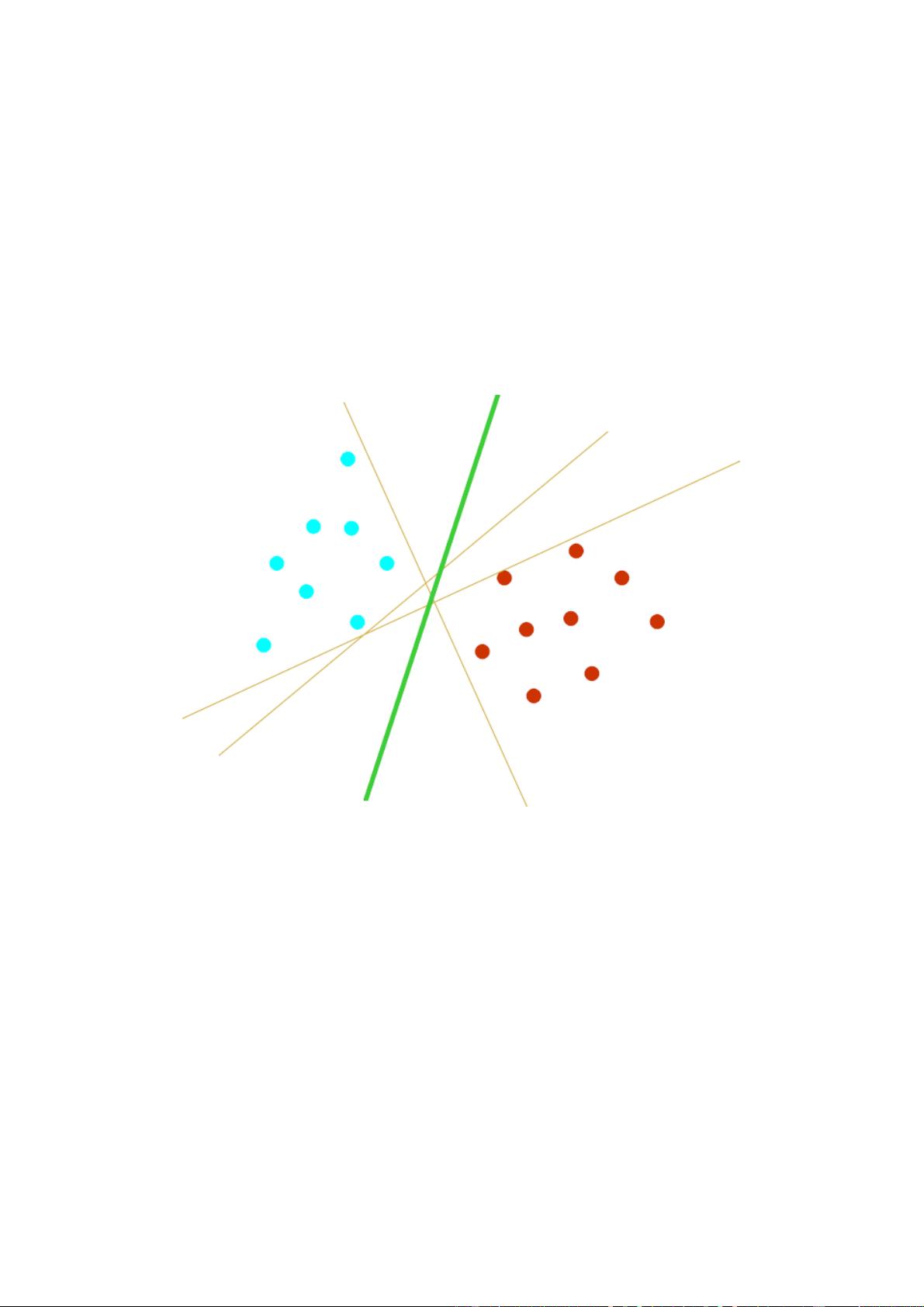
Image Speech and Intelligent Systems Group
2 Support Vector Classification
The classification problem can be restricted to consideration of the two-class problem
without loss of generality. In this problem the goal is to separate the two classes by a
function which is induced from available examples. The goal is to produce a classifier
that will work well on unseen examples, i.e. it generalises well. Consider the example
in Figure 2. Here there are many possible linear classifiers that can separate the data,
but there is only one that maximises the margin (maximises the distance between it
and the nearest data point of each class). This linear classifier is termed the optimal
separating hyperplane. Intuitively, we would expect this boundary to generalise well
as opposed to the other possible boundaries.
Figure 2 Optimal Separating Hyperplane
2.1 The Optimal Separating Hyperplane
Consider the problem of separating the set of training vectors belonging to two
separate classes,
()()
{}
yyxRy
ll
n
11
11,,,,, , ,xxK ∈∈−+,(4)
with a hyperplane
()
wx
⋅+=
b 0.(5)
The set of vectors is said to be optimally separated by the hyperplane if it is separated
without error and the distance between the closest vector to the hyperplane is
maximal. There is some redundancy in Equation (5), and without loss of generality it
is appropriate to consider a canonical hyperplane [21], where the parameters w, b are
constrained by,
剩余51页未读,继续阅读
153 浏览量
2024-08-24 上传
2015-05-10 上传
186 浏览量
2022-09-23 上传
2022-07-14 上传
112 浏览量
2018-03-07 上传
2021-04-17 上传

wli16
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- Verilog实现的Xilinx序列检测器设计教程
- 九度智能SEO优化软件新版发布,提升搜索引擎排名
- EssentialPIM Pro v11.0 便携修改版:全面个人信息管理与同步
- C#源代码的恶作剧外表答题器程序教程
- Weblogic集群配置与优化及常见问题解决方案
- Harvard Dataverse数据的Python Flask API教程
- DNS域名批量解析工具v1.31:功能提升与日志更新
- JavaScript前台表单验证技巧与实例解析
- FLAC二次开发实用论文资料汇总
- JavaScript项目开发实践:Front-Projeto-Final-PS-2019.2解析
- 76云保姆:迅雷云点播免费自动升级体验
- Android SQLite数据库增删改查操作详解
- HTML/CSS/JS基础模板:经典篮球学习项目
- 粒子群算法优化GARVER-6直流配网规划
- Windows版jemalloc内存分配器发布
- 实用强大QQ机器人,你值得拥有
