Spark RDD编程:大学成绩分析
需积分: 50 140 浏览量
更新于2024-09-01
2
收藏 642KB DOC 举报
"Spark实验5涉及RDD编程,主要任务是对一个包含大学计算机系成绩的数据集data1.txt进行分析。数据集中的每一行记录了一个学生的姓名、所选课程和成绩。实验要求实现以下功能:计算学生总数、课程总数、Tom同学的平均成绩、每个学生的选课门数、DataBase课程的选课人数以及所有课程的平均分。实验通过在Spark Shell中运行Scala代码来完成。"
在Spark中,RDD(Resilient Distributed Datasets)是其核心数据结构,它是弹性分布式数据集,能够并行处理大量数据。在这个实验中,首先通过`sc.textFile()`方法读取数据文件,并对数据进行一系列的转换和操作。
(1)计算学生总数:
使用`map()`函数将每行数据分割成字段,提取出学生姓名,然后使用`distinct()`去除重复,最后用`count()`统计不重复的学生数量。
(2)计算课程总数:
同样使用`map()`获取每行数据的课程名,然后应用`distinct()`和`count()`来得到课程总数。
(3)计算Tom同学的总成绩平均分:
首先使用`filter()`找出所有Tom的成绩记录,接着使用`map()`提取成绩和计数,通过`reduceByKey()`对Tom的所有成绩进行求和与计数,最后计算平均分。
(4)计算每名同学的选修课程门数:
利用`map()`提取学生姓名和课程名,`reduceByKey()`合并相同学生的所有课程,计算每个学生选修的课程门数。
(5)计算DataBase课程的选修人数:
通过`filter()`筛选出所有DataBase课程的记录,然后用`count()`得到选修人数。
(6)计算各门课程的平均分:
将每条记录的课程名和成绩提取出来,使用`reduceByKey()`对每个课程的所有成绩进行求和与计数,然后计算平均分。
(7)使用累加器计算选修DataBase课程的人数:
累加器在Spark中是一种可以跨节点共享和更新的变量。可以创建一个累加器,每当遇到DataBase课程时,累加器的值就加一,从而得到选修该课程的总人数。
这个实验不仅展示了Spark RDD的基本操作,如`map()`, `filter()`, `reduceByKey()`, `distinct()`, `count()`, 还演示了如何使用累加器来处理全局计数问题。通过这种方式,Spark能够高效地并行处理大量数据,实现分布式计算。
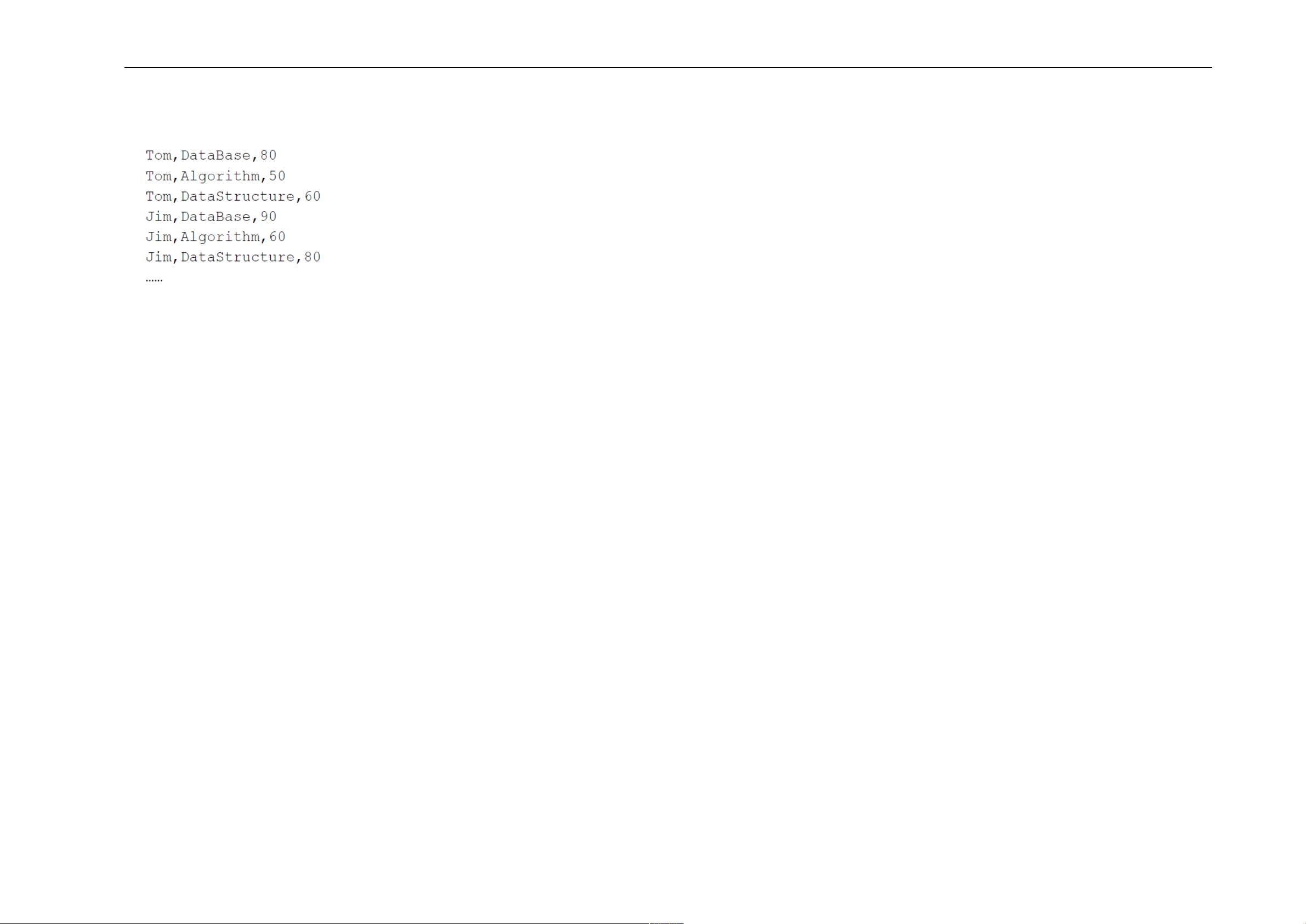
数据集 data1.txt 包含了某大学计算机系的成绩,数据格式如下所示:
请根据给定的实验数据,编写独立的应用程序来计算以下内容:
(1)该系总共有多少学生;
(2)该系共开设来多少门课程;
(3)Tom同学的总成绩平均分是多少;
(4)求每名同学的选修的课程门数;
(5)该系DataBase课程共有多少人选修;
(6)各门课程的平均分是多少;
(7)使用累加器计算共有多少人选了 DataBase 这门课。
三、实验步骤
1.打开 spark :cd /usr/local/spark
bin/spark-shell
2. 连接 yarn : spark-shell --master yarn
3. 导入文件:val input =sc.textFile(“file:///home/hadoop/ymq.txt”)
(1)该系总共有多少学生;
input.map(line=>line.split(",")(0)).distinct().count()
(2)该系共开设来多少门课程;
input.map(line=>line.split(",")(1)).distinct().count()
(3)Tom同学的总成绩平均分是多少;
valTom=input.lter(t=>t.split(",")(0)=="Tom")
valTom_1=Tom.map(t=>(t.split(",")(0),(t.split(",")(2).toInt,1)))
valTom_2=Tom_1.reduceByKey((a,b)=>(a._1+b._1,a._2+b._2))
Tom_2.mapValues(a=>a._1/a._2).rst()
(4)求每名同学的选修的课程门数;
input.map(t=>(t.split(",")(0),(t.split(",")
(1),1))).reduceByKey((a,b)=>(a._1,a._2+b._2)).mapValues(a=>a._2).foreac
h(println)
(5)该系DataBase课程共有多少人选修;
input.lter(t=>t.split(",")(1)=="DataBase").count()
(6)各门课程的平均分是多少;
input.map(t=>(t.split(",")(1),(t.split(",")
(2).toInt,1))).reduceByKey((a,b)=>(a._1+b._1,a._2+b._2)).mapValues(a=>a
._1/a._2).foreach(println)
(7)使用累加器计算共有多少人选了 DataBase 这门课。
valdatabase=input.lter(t=>t.split(",")
(1)=="DataBase").map(t=>(t.split(",")(1),1))
valcounter=sc.longAccumulator("database_counter")
database.values.foreach(a=>counter.add(a))
counter.value
四、实验结果
下载后可阅读完整内容,剩余3页未读,立即下载
2017-10-19 上传
2022-07-15 上传
2023-12-20 上传
2021-12-15 上传
2024-11-02 上传
2019-08-19 上传
2019-05-27 上传
2022-12-25 上传

Improssible
- 粉丝: 0
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- AJAX开发简略.pdf
- PowerBuilder8.0中文参考手册.pdf
- struts2.0+hibernate3.1+spring2.0的使用.doc
- VB中与串口通讯需要用到的控件介绍
- cpu卡基础知识与入门方法
- c++ TR1 文档
- 虚拟键盘的驱动程序 制作虚拟键盘的过程和
- MRPII-最经典的教材
- GRAILS中文开发PDF文档
- c++ 小游戏 程序
- 深入浅出Struts2.pdf
- 网络工程师英词典 网工英语词汇表.pdf
- Ubuntu实用学习教程
- Linux.C++.Programming.HOWTO
- QTP初级使用手册QTP8_Tutorial_oldsidney_cn
- 注册表概述精华及普遍误区
