利用神经网络实现低成本高精度PM2.5预测
需积分: 5 179 浏览量
更新于2024-08-26
收藏 833KB PDF 举报
"本文提出了一种基于人工神经网络(Artificial Neural Network,ANN)的精确且低成本的PM2.5估算方法,通过监测其他易于获取的污染物和气象因素,来实现对PM2.5浓度的高效估算。针对数据分布导致的过拟合问题,提出了熵最大化步骤,并将输入属性选择抽象为优化问题,采用迭代贪婪算法进行解决,以降低成本并提高估算精度。"
基于人工神经网络的精确低成本PM2.5估算方法是当前环保领域中的一个重要研究课题。PM2.5,即直径小于或等于2.5微米的颗粒物,是一种对人体健康造成严重影响的空气污染物,尤其在许多中国城市中,已经成为主要的空气污染源,可能导致多种肺部疾病。然而,现有的高精度监测方法由于成本高昂,普及率较低,限制了对PM2.5的深入研究。
该研究论文提出了一种创新的解决方案,利用ANN技术,结合易于监测的其他污染物数据和气象因素,如二氧化硫、二氧化氮、温度、湿度等,来估算PM2.5的浓度。这种方法旨在降低监测成本,同时保持高估算精度,以促进PM2.5监测的广泛实施。
为了防止由于污染物数据分布不均导致的过拟合问题,论文中引入了一个熵最大化步骤。过拟合是机器学习模型中常见的问题,它发生在模型过于复杂,对训练数据过度拟合,导致在新数据上的预测性能下降。熵最大化通过调整模型复杂度,使得模型在保留信息的同时避免对特定数据点的过度依赖,从而提高泛化能力。
此外,如何选择输入属性对于模型的性能至关重要。论文将这个问题抽象为一个优化问题,旨在找到最能影响PM2.5浓度的特征组合。为了解决这个优化问题,论文提出了一种迭代贪婪算法。这种算法通过逐步添加对模型性能提升最大的特征,逐步构建最优的输入集合,同时控制了计算成本,确保了模型的运行效率。
通过上述方法,该研究实现了在降低成本的同时提高PM2.5估算的准确性,这对于环境保护和公众健康具有重要意义。这种方法的应用不仅有助于实时监控空气质量,还可以为政策制定者提供科学依据,制定更有效的空气污染防控策略。未来的研究可以进一步探索不同类型的神经网络结构,以及如何结合大数据和物联网技术,实现更智能、更实时的PM2.5估算。
An Accurate and Low-cost PM
2.5
Estimation
Method Based on Artificial Neural Network
Lixue Xia, Rong Luo, Bin Zhao, Yu Wang, Huazhong Yang
Dept. of E.E., Tsinghua National Laboratory for Information Science and Technology (TNList),
Tsinghua University, Beijing, China
e-mail: xialx13@mails.tsinghua.edu.cn
Abstract—PM
2.5
has already been a major pollutant in many
cities in China. It is a kind of harmful pollutant which may cause
several kinds of lung diseases. However, the existing methods to
monitor PM
2.5
with high accuracy are too expensive to popular-
ize. The high cost also limits the further researches about PM
2.5
.
This paper implements a method to estimate PM
2.5
with low cost
and high accuracy by Artificial Neural Network (ANN) technique
using other pollutants and meteorological factors that are easy
to be monitored. An Entropy Maximization step is proposed to
avoid the over-fitting related to the data distribution of pollutant
data. Also, how to choose the input attributes is abstracted to an
optimization problem. An iterative greedy algorithm is proposed
to solve it, which reduces the cost and increases the estimation
accuracy at the same time. The experiment shows that the linear
correlation coefficient between the estimated value and real value
is 0.9488. Our model can also classify PM
2.5
levels with a high
accuracy. Additionally, the trade-off between accuracy and cost is
investigated according to the price and error rate of each sensor.
I. INTRODUCTION
Nowadays, the high frequency of hazy weather in many
cities in China has made the particles with aerodynamic
diameter less than 2.5 micrometer (PM
2.5
) attract more and
more attention. PM
2.5
can attach many kinds of poisonous
chemicals and impact human health, which may cause many
diseases such as asthma and chronic obstructive pulmonary
disease (COPD) [1]. As a result, many citizens urgently
want to know the PM
2.5
quality in their living and working
environment.
However, the existing methods to accurately monitor PM
2.5
require the support from a high-cost and complicated system,
which makes it difficult to measure PM
2.5
without a special-
ized monitor station [2]. It can be seen from Table I that all
these highly accurate equipments need a high cost that most
citizens and researchers cannot afford these equipments. As a
result, monitoring PM
2.5
is far from universal, and the lack
of data blocks the progress of researching and controlling of
PM
2.5
. Also, the high cost also leads to difficulties to analyse
the PM
2.5
problem under a specific environment, such as the
in-door PM
2.5
[3].
In order to reduce the cost of monitoring PM
2.5
, some
researchers use low-cost methods such as ANN technique to
estimate PM
2.5
recently [4]–[6]. The ANN technique attempts
to use data that are easy to be sensed to calculate PM
2.5
.
Nevertheless, PM
2.5
has complex causes and can be influenced
by too many factors compared with other molecular pollutants
such as O
3
[7]. The estimation accuracy is low when directly
using ANN, or the cost goes high again after many kinds
of expensive data are used. Given this situation, we find two
0
50
100
150
200
250
300
350
400
450
500
Time
PM
2.5
13-Mar-2014
12:00:00
24-Apr-2014
22:00:00
The boundary of Heavily
Polluted according to
the definition of Air
Quality Level [8]
Fig. 1. IAQI of PM
2.5
over a mounth
TABLE I
C
OST AND METHOD OF EQUIPMENTS TO MONITOR PM
2.5
Method Cost Principle
TEOM 1405 22,000$ TEOM Gravimentric
BAM-1020 23,000$ Beta-ray
TSI DUSTTRAJ II 80,000CNY Photometric
Dylos DC1700 425$ Particle counter
major problems that limit the estimation accuracy of ANN
model and choose specific algorithms to solve them.
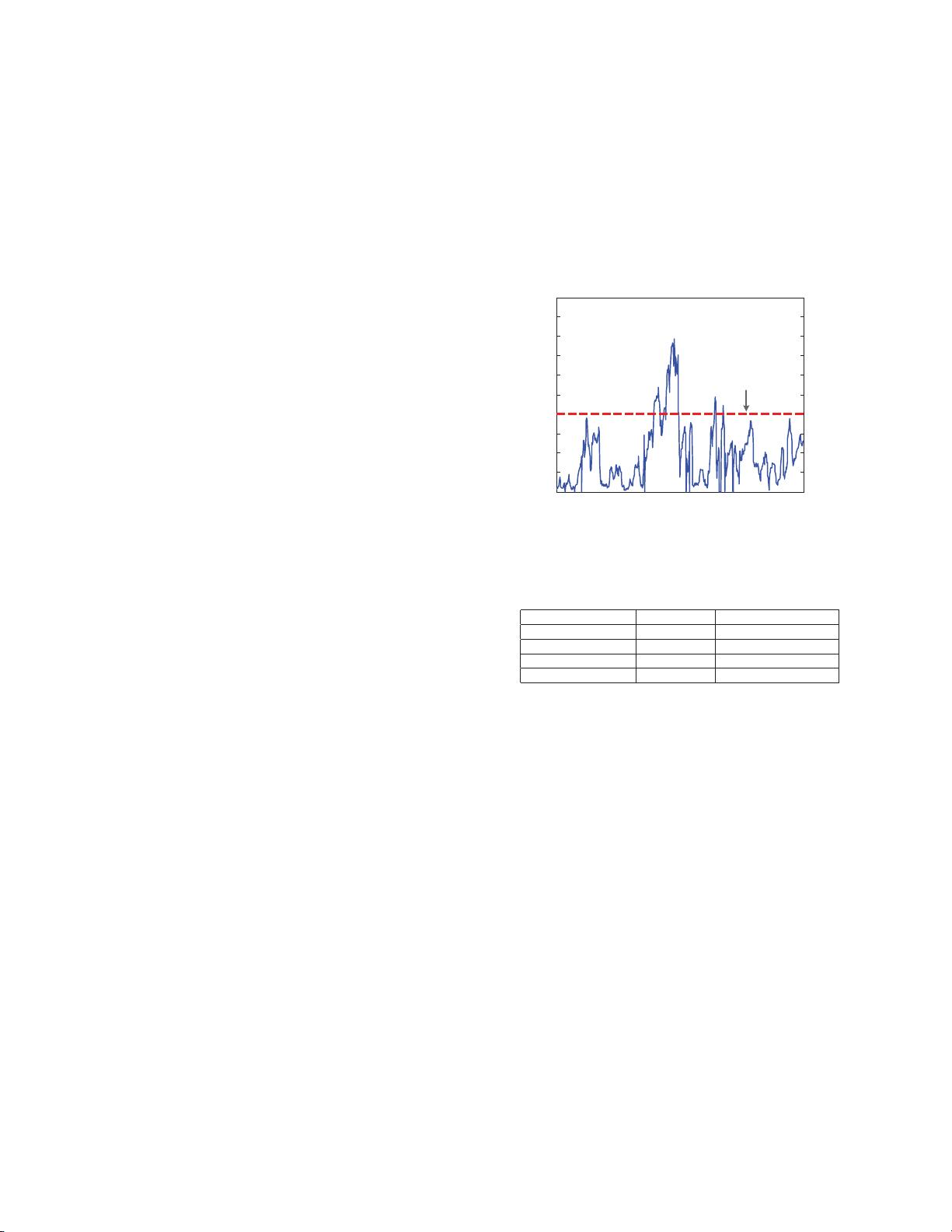
The first problem is the estimation error caused by the
different distributions of data over different data sets. As is
shown in Fig. 1, the Individual Air Quality Index (IAQI)
of PM
2.5
is more likely to take a low value and only has
little chance to take a high value. However, it is just the
data over the boundary of Heavily Polluted range in Fig. 1
that contain important information. As a result, the important
data may be ignored or only have little weights in training
phase due to the small amount. This is a kind of over-fitting
phenomenon which leads to a high error rate in the key range,
so the trained model is inefficient when the situation of the
T estingDataset is different from the T rainingDataset, for
example, the heavily polluted weeks. This paper proposes an
Entropy M aximization operation before training phase to
emphasize the important data, which can avoid the over-fitting
related to the data distribution and thus improve the estimation
accuracy.
Second, the redundant input attributes lead to unnecessary
cost and may bring noise to reduce the estimation accuracy. An
attribute refers to a kind of data, for example, the W indSpeed.
Considering that some meteorological data have an aggre-
gation characteristic over seasons, using the irrelevant input
attributes may also cause over-fitting. In fact, the problem
978-1-4799-7792-5/15/$31.00 ©2015 IEEE
2C-2
190
下载后可阅读完整内容,剩余5页未读,立即下载
2021-09-25 上传
256 浏览量
2021-09-25 上传
2824 浏览量
182 浏览量
126 浏览量
324 浏览量
2021-09-27 上传
2021-09-25 上传

weixin_38522529
- 粉丝: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 久度免费文件代存系统 v1.0:全技术领域源码分享
- 深入解析caseyjpaul.github.io的HTML结构
- HTML5视频播放器的实现与应用
- SSD7练习9完整答案解析
- 迅捷PDF完美转PPT技术:深度识别PDF内容
- 批量截取子网页工具:Python源码分享与使用指南
- Kotlin4You: 探索设计模式与架构概念
- 古典风格茶园茶叶酿制企业网站模板
- 多功能轻量级jquery tab选项卡插件使用教程
- 实现快速增量更新的jar包解决方案
- RabbitMQ消息队列安装及应用实战教程
- 简化操作:一键脚本调用截图工具使用指南
- XSJ流量积算仪控制与数显功能介绍
- Android平台下的AES加密与解密技术应用研究
- Место-响应式单页网站的项目实践
- Android完整聊天客户端演示与实践
