Python3.5 Pandas DataFrame详解:创建、读取、过滤操作
66 浏览量
更新于2024-09-02
收藏 1001KB PDF 举报
"Python3.5中的Pandas模块是一个强大的数据处理库,DataFrame是其核心数据结构之一。本文将深入探讨如何在Python3.5环境下使用Pandas的DataFrame,包括创建、读取、过滤和获取数据等关键操作,并提供实例进行详细解释。"
在Python3.5中,Pandas的DataFrame是一种二维表格型数据结构,它具有列标签(column labels)和行索引(row indices)。DataFrame能够存储各种类型的数据,如整数、浮点数、字符串,甚至是其他复杂的数据类型。
1、DataFrame的创建
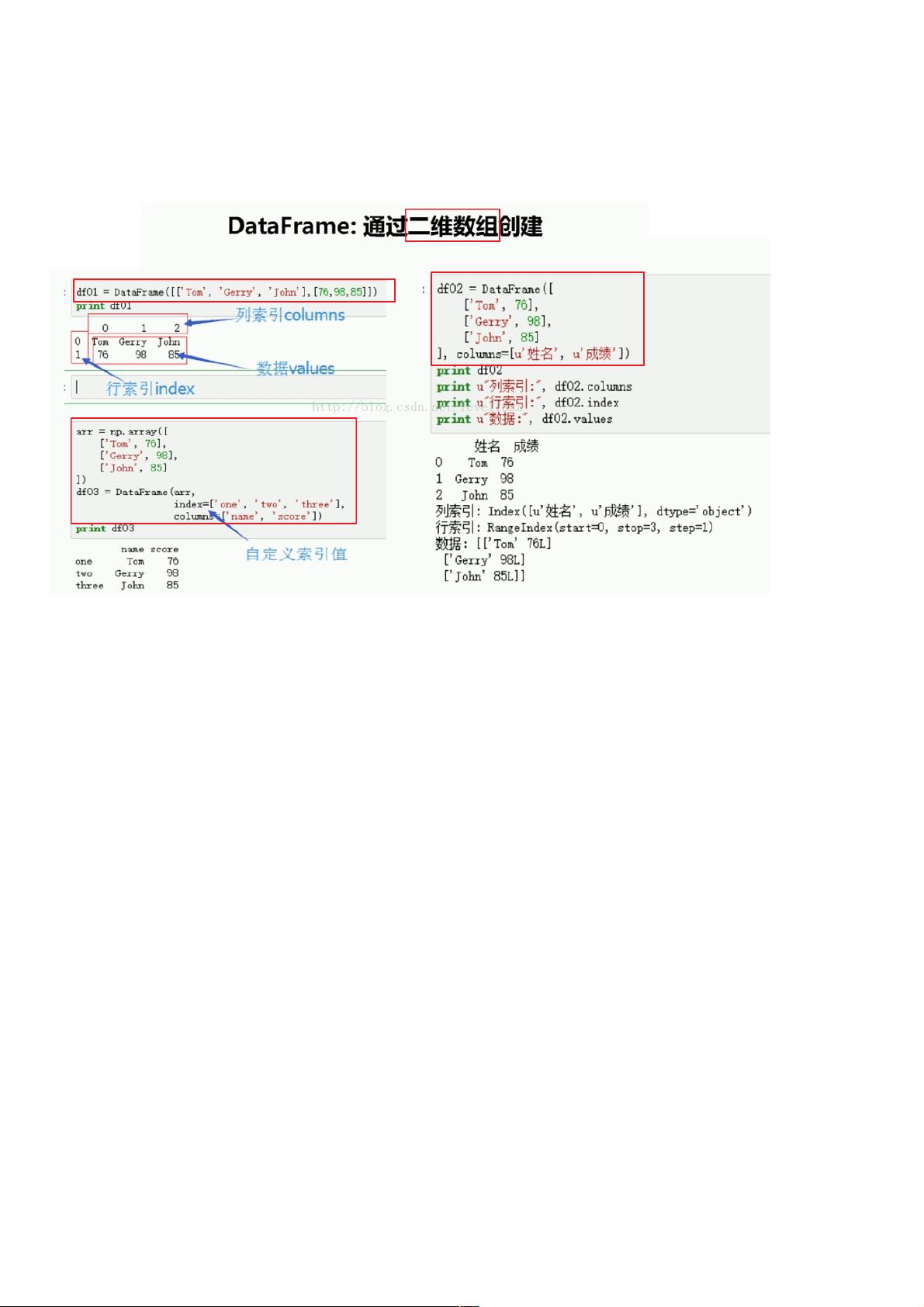
创建DataFrame有多种方式,其中最常见的是通过二维数组或列表来构建。下面展示了两种创建DataFrame的方法:
(1)直接通过二维列表创建:
```python
d1 = DataFrame([["a","b","c","d"], [1,2,3,4]])
```
这将创建一个DataFrame,其中第一行包含字符串"abcd",第二行包含数字1到4。
(2)利用numpy数组创建:
```python
import numpy as np
arr = np.array([["jack",78], ["lili",86], ["amy",97], ["tom",100]])
d2 = DataFrame(arr, index=["01","02","03","04"], columns=["姓名","成绩"])
```
在这个例子中,我们定义了numpy数组,并指定了行索引和列名,创建了一个包含姓名和成绩的DataFrame。
2、行和列的索引
创建DataFrame后,我们可以访问行和列的索引来获取特定数据。例如,`d2.index`返回行索引,`d2.columns`返回列索引,而`d2.values`则返回DataFrame的所有值,以二维numpy数组的形式:
```python
print(d2.index) # 打印行索引
print(d2.columns) # 打印列索引
print(d2.values) # 打印值
```
3、DataFrame的读取
Pandas提供了许多函数来读取不同格式的数据,例如CSV、Excel、SQL数据库等。以CSV文件为例,可以使用`pd.read_csv()`函数:
```python
df_csv = pd.read_csv('file.csv')
```
4、过滤和获取数据
过滤DataFrame可以通过布尔索引来实现,例如:
```python
filtered_df = df[df['成绩'] > 90] # 获取成绩大于90的记录
```
获取特定列的数据,可以使用列名:
```python
column_data = df['姓名'] # 获取'姓名'列的所有数据
```
5、其他操作
DataFrame还支持各种其他操作,如数据合并(`concat`、`merge`)、数据重塑(`pivot`、`stack`、`unstack`)、数据分组(`groupby`)、数据聚合(`agg`、`mean`、`sum`等)以及数据清洗等。
Pandas的DataFrame是处理结构化数据的强大工具,它提供的丰富功能使得数据预处理和分析变得简单高效。通过理解并熟练掌握DataFrame的各种操作,可以极大地提升数据分析的效率和质量。
Python3.5 Pandas模块之模块之DataFrame用法实例分析用法实例分析
主要介绍了Python3.5 Pandas模块之DataFrame用法,结合实例形式详细分析了Python3.5中Pandas模块的DataFrame结构创建、读取、过滤、获取
等相关操作技巧与注意事项,需要的朋友可以参考下
本文实例讲述了Python3.5 Pandas模块之DataFrame用法。分享给大家供大家参考,具体如下:
1、DataFrame的创建
(1)通过二维数组方式创建
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:ZhengzhengLiu
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
#1.DataFrame通过二维数组创建
print("======DataFrame直接通过二维数组创建======")
d1 = DataFrame([["a","b","c","d"],[1,2,3,4]])
print(d1)
print("======DataFrame借助array二维数组创建======")
arr = np.array([
["jack",78],
["lili",86],
["amy",97],
["tom",100]
])
d2 = DataFrame(arr,index=["01","02","03","04"],columns=["姓名","成绩"])
print(d2)
print("========打印行索引========")
print(d2.index)
print("========打印列索引========")
print(d2.columns)
print("========打印值========")
print(d2.values)
运行结果:
======DataFrame直接通过二维数组创建======
0 1 2 3
0 a b c d
1 1 2 3 4
======DataFrame借助array二维数组创建======
姓名 成绩
01 jack 78
02 lili 86
03 amy 97
04 tom 100
========打印行索引========
Index(['01', '02', '03', '04'], dtype='object')
========打印列索引========
Index(['姓名', '成绩'], dtype='object')
========打印值========
[['jack' '78']
['lili' '86']
['amy' '97']
['tom' '100']]
(2)通过字典方式创建
下载后可阅读完整内容,剩余5页未读,立即下载
789 浏览量
473 浏览量
189 浏览量
480 浏览量
216 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38553791
- 粉丝: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 网狐工具:核心DLL和程序文件解析
- PortfolioCVphp - 展示JavaScript技能的个人作品集
- 手机归属地查询网站完整项目:HTML+PHP源码及数据集
- 昆仑通态MCGS通用版S7400父设备驱动包下载
- 手机QQ登录工具的压缩包内容解析
- Git基础学习仓库:掌握版本控制要点
- 3322动态域名更新器使用教程与下载
- iOS源码开发:温度转换应用简易教程
- 定制化用户登录页面模板设计指南
- SMAC电机在包装生产线应用的技术案例分析
- Silverlight 5实现COM组件调用无需OOB技术
- C#实现多功能画图板:画直线、矩形、圆等
- 深入探讨C#语言在WPF项目开发中的应用
- 新版2012109通用权限系统源码发布:多角色用户支持
- 计算机科学与工程系网站开发技术源码合集
- Java实现简易导出Excel工具的开发教程
