亚马逊云架构:构建弹性伸缩的应用程序
需积分: 9 176 浏览量
更新于2024-09-03
收藏 281KB PDF 举报
“Cloud Architectures.pdf 是一份探讨云计算框架的英文文献,主要介绍如何利用互联网云服务构建应用程序。本文档由Amazon Web Services的技术布道师Jinesh Varia撰写,适合具备英文阅读能力并对云计算框架感兴趣的读者。内容涵盖了一个实际运行中的应用示例,该应用利用亚马逊AWS提供的按需基础设施进行大规模的模式匹配处理。”
云计算架构是基于互联网可访问的按需服务构建软件应用的设计模式。这些应用的特点是在需要时(例如处理用户请求时)才使用底层计算基础设施,按需获取如计算服务器或存储等资源,执行特定任务,然后释放不再需要的资源,并且通常在任务完成后自动关闭。运行过程中,应用能根据资源需求弹性伸缩。
文档的第一部分详述了一个使用亚马逊Web Services(AWS)提供的按需基础设施的实战应用案例。这个应用允许开发者对数百万网页文档进行模式匹配。当有需求时,应用可以即时启动数百个虚拟服务器,这些服务器能够动态扩展以应对处理大量数据的需求。这展示了云计算架构的灵活性和可扩展性,使得开发者无需预先投入大量硬件资源,也能处理大规模的数据处理任务。
AWS是全球领先的云服务提供商,提供了一系列广泛的服务,包括计算(如EC2)、存储(如S3)、数据库(如RDS)、分析工具(如EMR)等,这些服务构成了构建云架构的基础。通过APIs和SDKs,开发者可以轻松地集成和管理这些服务,创建高度可伸缩和自适应的应用程序。
在描述的应用中,可能使用了AWS的EC2(Elastic Compute Cloud)来快速启动和关闭虚拟服务器,满足动态变化的计算需求。S3(Simple Storage Service)可能被用来存储大量的文档数据,而其他服务如Elastic Map Reduce (EMR) 可能用于进行大规模的并行处理,以实现高效的模式匹配功能。此外,可能还使用了Auto Scaling和CloudWatch等工具来监控和调整资源分配,确保应用的稳定性和效率。
总结来说,"Cloud Architectures.pdf"深入介绍了利用AWS构建云架构的方法,强调了弹性计算、动态资源配置以及云服务在构建现代应用程序中的核心作用。对于理解云计算的工作原理和最佳实践,以及如何利用云服务优化应用程序的性能和成本,这份文档具有很高的学习价值。
Amazon Web Services
In this paper, we will discuss one application example in
detail - code-named as “GrepTheWeb”.
Cloud Architecture Example: GrepTheWeb
The Alexa Web Search web service allows developers to
build customized search engines against the massive
data that Alexa crawls every night. One of the features of
their web service allows users to query the Alexa search
index and get Million Search Results (MSR) back as
output. Developers can run queries that return up to 10
million results.
The resulting set, which represents a small subset of all
the documents on the web, can then be processed
further using a regular expression language. This allows
developers to filter their search results using criteria that
are not indexed by Alexa (Alexa indexes documents
based on fifty different document attributes) thereby
giving the developer power to do more sophisticated
searches. Developers can run regular expressions against
the actual documents, even when there are millions of
them, to search for patterns and retrieve the subset of
documents that matched that regular expression.
This application is currently in production at Amazon.com
and is code-named GrepTheWeb because it can “grep” (a
popular Unix command-line utility to search patterns) the
actual web documents. GrepTheWeb allows developers to
do some pretty specialized searches like selecting
documents that have a particular HTML tag or META tag
or finding documents with particular punctuations
(“Hey!”, he said. “Why Wait?”), or searching for
mathematical equations (“f(x) = ∑x + W”), source code,
e-mail addresses or other patterns such as
“(dis)integration of life”.
While the functionality is impressive, for us the way it
was built is even more so. In the next section, we will
zoom in to see different levels of the architecture of
GrepTheWeb.
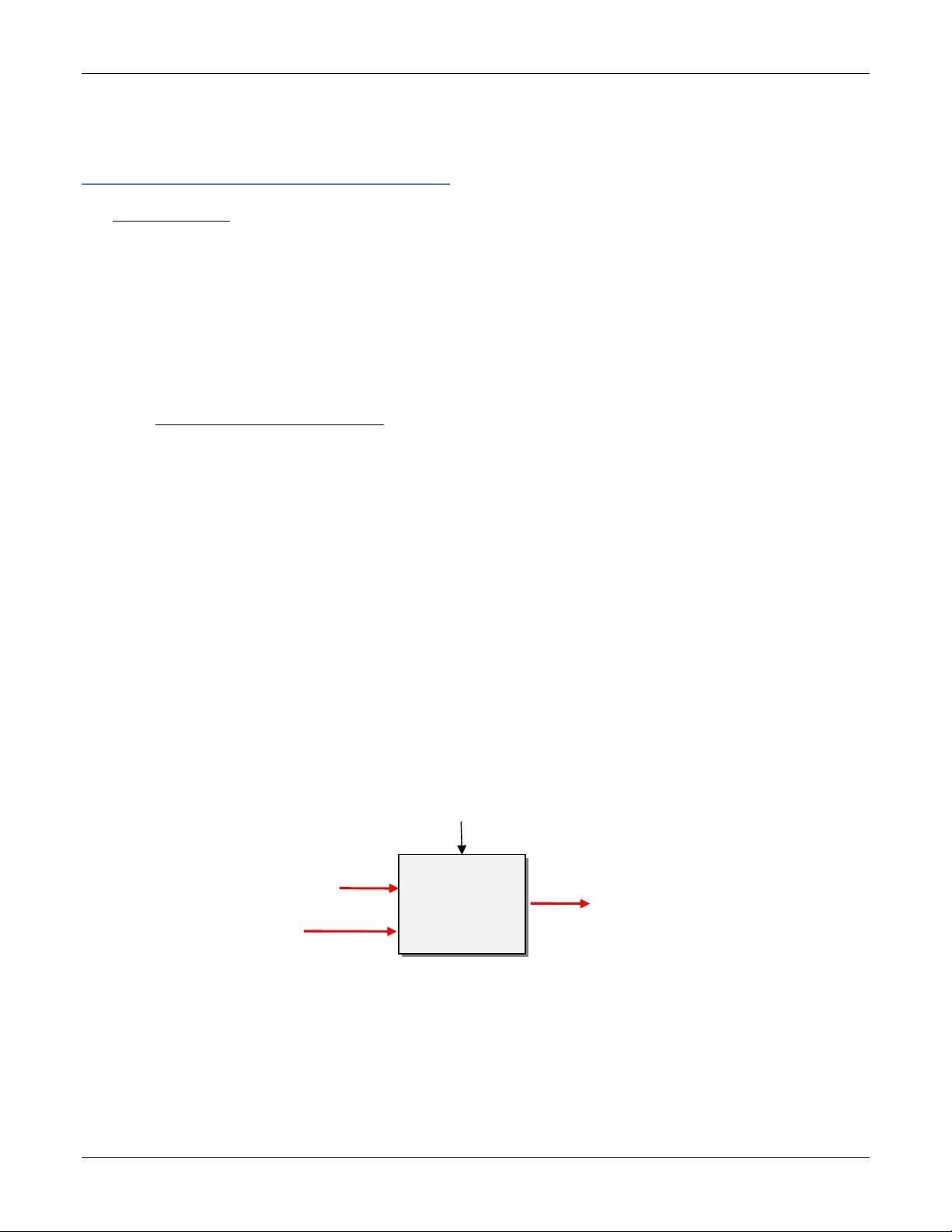
Figure 1 shows a high-level depiction of the architecture.
The output of the Million Search Results Service, which is
a sorted list of links and gzipped (compressed using the
Unix gzip utility) in a single file, is given to GrepTheWeb
as input. It takes a regular expression as a second input.
It then returns a filtered subset of document links sorted
and gzipped into a single file. Since the overall process is
asynchronous, developers can get the status of their jobs
by calling GetStatus() to see whether the execution is
completed.
Performing a regular expression against millions of
documents is not trivial. Different factors could combine
to cause the processing to take lot of time:
• Regular expressions could be complex
• Dataset could be large, even hundreds of
terabytes
• Unknown request patterns, e.g., any number of
people can access the application at any given
point in time
Hence, the design goals of GrepTheWeb included to scale
in all dimensions (more powerful pattern-matching
languages, more concurrent users of common datasets,
larger datasets, better result qualities) while keeping the
costs of processing down.
The approach was to build an application that not only
scales with demand, but also without a heavy upfront
investment and without the cost of maintaining idle
machines (“downbottom”). To get a response in a
reasonable amount of time, it was important to distribute
the job into multiple tasks and to perform a Distributed
Grep operation that runs those tasks on multiple nodes in
parallel.
GrepTheWeb
Application
RegEx
Subset of
document URLs
that matched
the RegEx
Input dataset (List of
Document Urls)
GetStatus
Fig
ure
1
: GrepTheWeb Architecture
-
Zoom Level 1
剩余13页未读,继续阅读
2019-04-22 上传
2019-06-26 上传
2018-03-11 上传
2018-01-13 上传
2018-01-09 上传
2019-08-28 上传
2019-06-19 上传
2021-08-08 上传
2019-06-26 上传

stonylhy2011
- 粉丝: 7
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- Essentials for KissAnime-crx插件
- 有冲突:R的替代冲突解决策略
- keegankresge.github.io
- napfinder-开源
- code-services-api:编码服务API规范
- nodejs-project
- 货币换算-crx插件
- vue+node全栈项目.zip
- cnode社区移动端开发.zip
- prettycode:语法在终端中突出显示R代码
- 参考资料-26房产估价案例分析总结记录.zip
- Can-Test-Program.rar_单片机开发_C/C++_
- flutter_login
- pyreadr:Python包,用于从熊猫数据帧读取R RData和Rds文件。 无需R或其他外部依赖项
- ts版本node项目.zip
- On10-TodasEmTech-MONITORIA-ProjetoI
