Linux内核链表详解:结构与操作实战
需积分: 10 70 浏览量
更新于2024-09-16
收藏 296KB PDF 举报
本文主要深入解析了Linux内核中的链表结构,特别关注于2.6.x版本的实现。作者杨沙洲,来自国防科技大学计算机学院,提供了一个初级级别的教程。链表作为一种重要的数据结构,通过指针将数据节点组织成有序的序列,具有动态性和灵活性,适合在不确定数据量的情况下进行插入和删除操作。
文章首先概述了链表的基本概念,强调了其与数组相比的优势,即动态分配空间和高效的插入删除操作,但同时也指出链表的缺点是访问顺序性和空间浪费。常见的链表类型包括单链表、双链表和循环链表。单链表只有一个指针域,只能顺序遍历;双链表则有前驱和后继指针,允许双向遍历,进一步扩展可以形成树状结构;循环链表的特点是尾节点的后继指向首节点,提供了灵活的遍历路径。
在Linux内核中,链表被广泛应用于设备管理、模块数据组织等场景。内核中使用了一种由[include/linux/list.h]定义的高效链表数据结构,这个结构在2.4和2.6版本之间基本保持一致。虽然本文以2.6内核为例,但对于2.4内核的理解并无太大障碍。
接下来,文章将详细介绍Linux内核链表数据结构的具体实现,包括其组织方式和使用方法,通过实例来阐述每个链表操作接口,帮助读者更好地理解和应用。这部分内容对于理解Linux内核底层工作原理以及如何处理动态数据至关重要。无论你是Linux初学者还是高级开发人员,学习和掌握这类基础知识都对提升编程技能和系统理解有着不可忽视的作用。
深入分析
Linux
内核链表
级别:
初级
杨沙洲
(pubb@163.net)
国防科技大学计算机学院
2004
年
8
月
01
日
本文详细分析了
2.6.x
内核中链表结构的实现,并通过实例对每个链表操作接口进
行了详尽的讲解。
一、
链表数据结构简介
链表是一种常用的组织有序数据的数据结构,它通过指针将一系列数据节点连接成一条数据
链,是线性表的一种重要实现方式。相对于数组,链表具有更好的动态性,建立链表时无需预
先知道数据总量,可以随机分配空间,可以高效地在链表中的任意位置实时插入或删除数据。
链表的开销主要是访问的顺序性和组织链的空间损失。
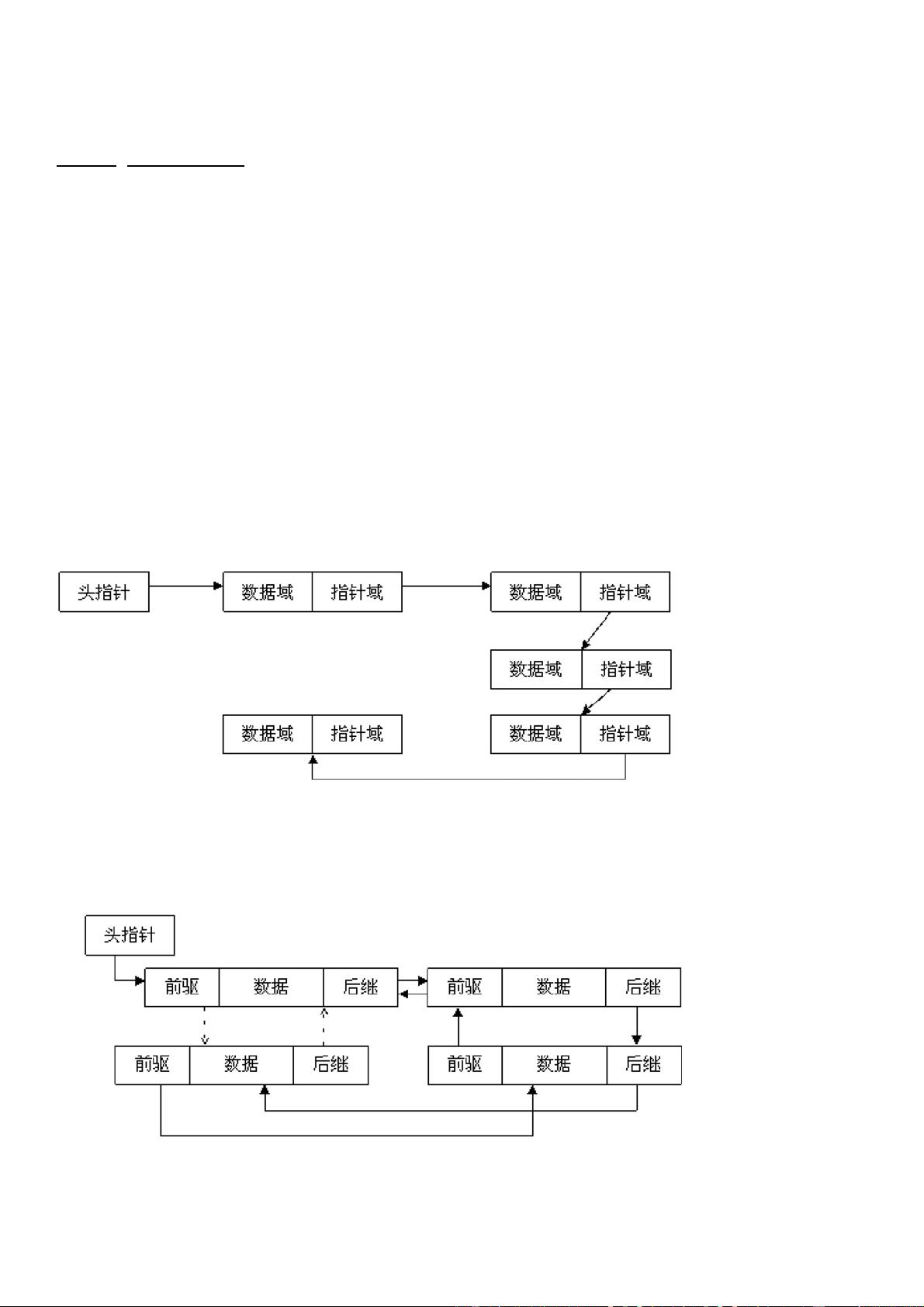
通常链表数据结构至少应包含两个域:数据域和指针域,数据域用于存储数据,指针域用于建
立与下一个节点的联系。按照指针域的组织以及各个节点之间的联系形式,链表又可以分为单
链表、双链表、循环链表等多种类型,下面分别给出这几类常见链表类型的示意图:
1. 单链表
图 1 单链表
单链表是最简单的一类链表,它的特点是仅有一个指针域指向后继节点(
next
),因此,对单
链表的遍历只能从头至尾(通常是
NULL
空指针)顺序进行。
2
.
双链表
图 2 双链表
通过设计前驱和后继两个指针域,双链表可以从两个方向遍历,这是它区别于单链表的地方。
如果打乱前驱、后继的依赖关系,就可以构成
"
二叉树
"
;如果再让首节点的前驱指向链表尾节
点、尾节点的后继指向首节点(如图
2
中虚线部分),就构成了循环链表;如果设计更多的指
针域,就可以构成各种复杂的树状数据结构。
3. 循环链表
2010/9/19 深入分析Linux内核链表
ibm.com/developerworks/…/l-chain/ 1/9
下载后可阅读完整内容,剩余8页未读,立即下载
143 浏览量
239 浏览量
点击了解资源详情
134 浏览量
338 浏览量
点击了解资源详情
176 浏览量
1469 浏览量









