DataFunTalk大数据峰会:案例分享与百万数据科学家历程
需积分: 9 36 浏览量
更新于2024-07-09
1
收藏 61.84MB PDF 举报
【大数据多维分析峰会专属典藏版合集】涵盖了众多来自国内外大厂(如BAT等)的大数据实现案例,深入剖析了数据科学领域的前沿技术和实战应用。该合集记录了DataFunTalk自2017年起举办的一系列线上线下活动,旨在促进大数据和人工智能技术的分享与交流。DataFunTalk通过100多场技术分享和两次大型峰会,吸引了600多位业界专家和知名学者,以及超过30,000名从业者参与,形成了一个活跃的数据科学社区,其运营的公众号原创文章累计超过500篇,阅读量超过百万,粉丝数量超过10万。
合集中的重要内容包括:
1. DorisDB在中移物联网PGW实时会话业务中的应用,展示了如何通过实时分析处理海量数据,提升业务效率。
2. 酷家乐利用DorisDB实现家居SaaS平台的全面数据分析升级,大幅降低成本,展现了大数据技术在企业中的实际效益。
3. 银行数据平台的进化路径探讨,揭示了金融机构如何适应大数据时代的数据管理和分析需求。
4. 批流一体大数据分析架构的搭建方法,帮助读者理解并构建高效的数据处理系统。
5. 极光技术在百万级日查询量场景下的应用选择和商业升级策略,提供针对高并发场景的最佳实践。
6. 车企转型指南,讲解如何构建云端数据湖,支持数据驱动的决策制定。
7. 快手如何应对EB级HDFS挑战,分享其在大数据存储和处理中的实践经验。
8. 贝壳基于Druid的OLAP引擎应用,展示企业如何利用数据驱动产品优化。
9. HiveMetaStore在快手遇到的问题及优化措施,体现了数据存储层的挑战与应对策略。
10. 贝壳数据平台的演变历程,反映企业数据治理的持续发展。
11. 快手在超大规模集群调度方面的优化实践,提供性能提升的策略。
12. 有赞的数据治理实践,探讨如何通过数据治理实现提质降本。
13. Impala 3.4在网易的最新应用,展示了大数据查询性能的提升和应用实例。
14. 美团酒旅的数据治理,呈现企业对复杂数据环境的管理。
15. 京东Flink优化与技术实践,揭示实时数据分析的重要性和技术细节。
16. Kafka在特定场景下的应用,强调实时数据流转的价值。
此外,合集还包含了微博基于Flink的机器学习应用实例,以及京东在实时数据仓库和Flink优化上的开发经验。这些案例充分展示了大数据在不同行业的实战应用,为数据科学家提供了丰富的学习资源和灵感。通过阅读这个典藏版合集,读者不仅能了解行业内的最佳实践,还能提升自己的专业技能,成为百万数据科学家之一。

DataFunTalk 成就百万数据科学家!
16
酷家乐 x DorisDB :家居 SaaS 独角兽如何实现数据
分析全面升级,大幅降低平台成本
酷家乐是群核科技旗下知名业务品牌,专注云设计系统及三维内容制作的技术研发和应
用,面向家居、房产、公装等全空间领域,为企业级客户提供设计渲染、营销展示、生
产施工、几何建模等场景的解决方案和服务。酷家乐大数据技术团队负责酷家乐大数据
体系框架的建设,支撑日常 BI 运营分析、商业化数据产品、在线大小数据业务、人群
画像等场景。生产环境上使用 DorisDB 集群(10 x 物理机)替换了原有阿里云 ADB 集
群和 EMR Presto 集群,在使用部分集群资源前提下,查询性能即可与 ADB 持平,Presto
P95 的查询从秒级提升到 500ms 级别。在完成同等分析任务情况下,DorisDB 性价比
是同类产品的两倍以上。DorisDB 一套集群统一了实时和离线的分析场景,替换了多套
系统带来的系统复杂性,简化了数据 ETL 流程,同时大幅提升 Adhoc 场景查询效率。本
文主要侧重于酷家乐大数据团队基于新一代极速 MPP 分析型数据库 DorisDB,在数据
服务体系和数据应用场景中的实践和探索。
“ 作者:弋舟大数据技术专家,酷家乐大数据团队负责人,坐标杭州 ”
数据引擎现状
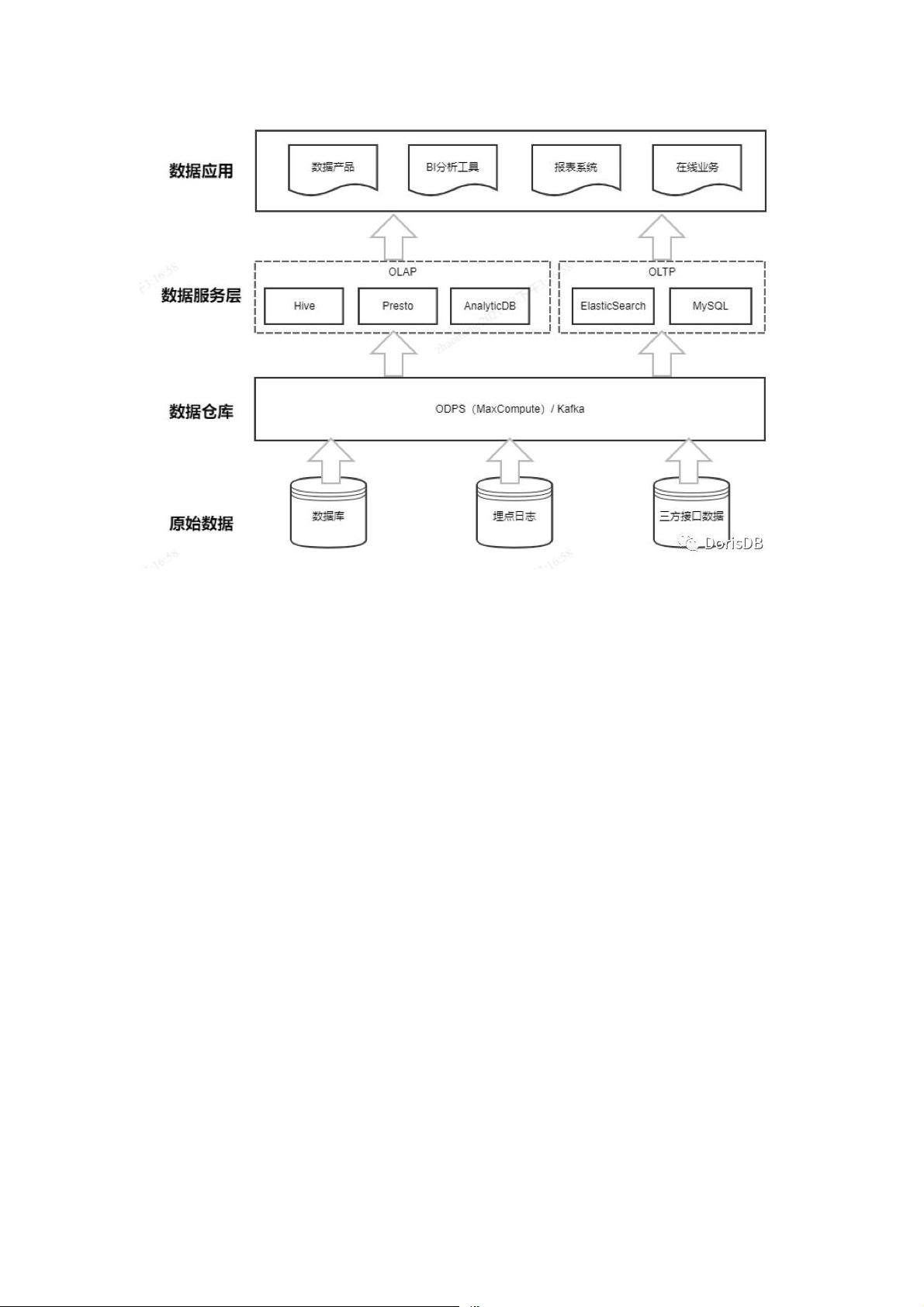
随着业务规模越来越大,数据规模和体量也急剧膨胀。企业的原始数据通常来源于
日志埋点文件、业务数据库、三方接口等。企业通常基于 CDH/Hadoop 等大
数据分布式计算框架和数据集成工具,构建离线的数据仓库,并对数据进行适当的
分层、建模、加工和管理。
但上层数据应用对查询的数据存储、时效性要求高,数据最终会通过数据同步工具
回流到 MySQL、ElasticSearch、Presto、HBase 等关系型
数据库/MPP 数据库中。



剩余1033页未读,继续阅读
2023-08-10 上传
2021-07-04 上传
2023-11-23 上传
2024-11-12 上传
2024-01-11 上传
2023-09-04 上传
2023-07-14 上传
2023-06-21 上传

xiaoSUM
- 粉丝: 6
- 资源: 26
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
