"深度前馈神经网络原理与Python实现详解"
需积分: 0 39 浏览量
更新于2024-04-02
收藏 1.38MB PDF 举报
深度学习是一种机器学习方法,通过构建多层神经网络来学习复杂的特征表示,以实现对输入数据的准确预测和分类。本文将重点介绍深度前馈神经网络的原理,包括定义、变量约束、前向传播等方面的内容,并通过公式推导和Python实现来展示其工作机制。
首先,深度前馈神经网络又称为多层感知机,其目标是近似一个目标映射函数。通过学习参数的值,使神经网络模型能够拟合因变量和自变量之间的映射关系。在深度学习中,神经网络的每一层包含多个神经元,每个神经元都有特定的权重和偏置,用来计算输入数据的特征表示。
在定义深度前馈神经网络时,我们需要考虑输入层的特征数和隐藏层以及输出层的神经元数量。其中,隐藏层神经元的数量需要根据具体的问题来调整,以实现对输入数据的良好拟合。在神经网络中,每个神经元都有一个激活函数,用来引入非线性因素,从而增加神经网络的表示能力。
前向传播是神经网络中的一个重要步骤,它指的是输入数据沿着网络进行前向传递,直到输出层得到最终的预测结果。在前向传播过程中,我们需要计算每一层神经元的输出,并将其传递给下一层神经元,直到输出层得到最终的预测结果。通过不断调整神经网络的参数,使得预测结果与真实标签之间的误差不断减小,从而提高模型的准确性。
公式推导是深度学习中的关键环节,通过推导各层神经元的计算公式,我们可以更好地理解神经网络的工作原理。在深度前馈神经网络中,我们需要考虑损失函数的定义,以及通过反向传播和梯度下降算法来更新神经网络的参数,以最小化损失函数。这一过程需要不断迭代,直到模型收敛到最优解。
最后,我们通过Python实现深度前馈神经网络,通过调用相关的库和函数,我们可以快速搭建神经网络模型,并对输入数据进行训练和预测。在实现过程中,我们需要注意神经网络模型的结构和参数设置,以及调整超参数来优化模型的性能。通过不断调整神经网络的结构和参数,我们可以提高模型的准确性,实现对复杂数据的有效建模和预测。
总的来说,深度前馈神经网络是一种强大的机器学习模型,通过构建多层神经网络来学习复杂的特征表示,以实现对输入数据的准确预测和分类。通过理解其原理、公式推导和Python实现,我们可以更好地掌握深度学习的核心概念,提高模型的性能和效果,从而更好地解决现实世界中的各种复杂问题。
dnn_utils provides some necessary functions for this notebook.
testCases provides some test cases to assess the correctness of your functions
np.random.seed(1) is used to keep all the random function calls consistent. It will help us grade your work. Please don't change the seed.
In[1]:
2 - Outline of the Assignment
To build your neural network, you will be implementing several "helper functions". These helper functions will be used in the next assignment to build a
two-layer neural network and an L-layer neural network. Each small helper function you will implement will have detailed instructions that will walk you
through the necessary steps. Here is an outline of this assignment, you will:
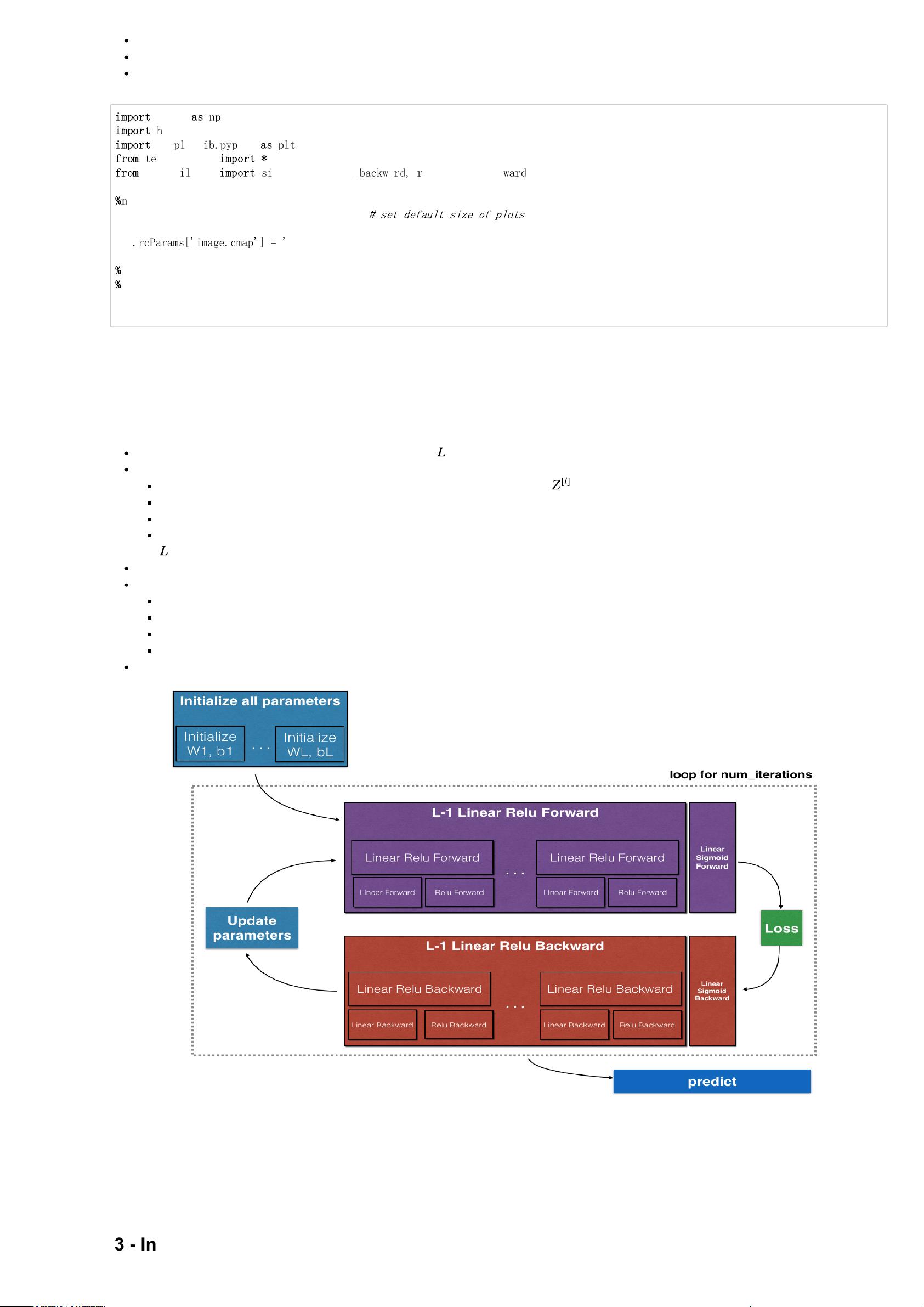
Initialize the parameters for a two-layer network and for an -layer neural network.
Implement the forward propagation module (shown in purple in the figure below).
Complete the LINEAR part of a layer's forward propagation step (resulting in ).
We give you the ACTIVATION function (relu/sigmoid).
Combine the previous two steps into a new [LINEAR->ACTIVATION] forward function.
Stack the [LINEAR->RELU] forward function L-1 time (for layers 1 through L-1) and add a [LINEAR->SIGMOID] at the end (for the final layer
). This gives you a new L_model_forward function.
Compute the loss.
Implement the backward propagation module (denoted in red in the figure below).
Complete the LINEAR part of a layer's backward propagation step.
We give you the gradient of the ACTIVATE function (relu_backward/sigmoid_backward)
Combine the previous two steps into a new [LINEAR->ACTIVATION] backward function.
Stack [LINEAR->RELU] backward L-1 times and add [LINEAR->SIGMOID] backward in a new L_model_backward function
Finally update the parameters.
Figure 1
Note that for every forward function, there is a corresponding backward function. That is why at every step of your forward module you will be storing
some values in a cache. The cached values are useful for computing gradients. In the backpropagation module you will then use the cache to
calculate the gradients. This assignment will show you exactly how to carry out each of these steps.
L
Z
[
l
]
L
3 - Initialization
import
numpy
as
np
import
h5py
import
matplotlib.pyplot
as
plt
from
testCases_v2
import
*
from
dnn_utils_v2
import
sigmoid, sigmoid_backward, relu, relu_backward
%
matplotlib inline
plt.rcParams['figure.figsize'] = (5.0, 4.0)
# set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
%
load_ext autoreload
%
autoreload 2
np.random.seed(1)
剩余15页未读,继续阅读
2022-08-03 上传
2020-12-20 上传
2021-05-17 上传
2021-05-12 上传
2021-04-20 上传
2021-03-07 上传
2023-07-19 上传
2021-04-08 上传

UEgood雪姐姐
- 粉丝: 42
- 资源: 319
 我的内容管理
展开
我的内容管理
展开







最新资源
- d3graphTheory:使用d3.js制作的互动式和彩色图论教程
- arcticseals:与NOAA海洋哺乳动物实验室合作进行的深度学习项目,用于对航空影像中的北极海豹进行检测和分类,以了解北极海豹如何适应不断变化的世界
- 61IC_S4282.rar_OpenCV_Visual_C++_
- FramerBasics
- A+InfoPower 2011(good).zip
- tableone:用于创建“表1”的R包,描述具有或不具有倾向得分加权的基线特征
- Discreet Links-crx插件
- NagiosCFG-开源
- ANFIS-Design.rar_matlab例程_matlab_
- matlab代码续行-UWPFlow:UWContinuationPowerFlow(c)1992、1996、1999、2006C.Caniz
- CSS3横向手风琴风格菜单
- leetcode:收集LeetCode问题以使编码面试更上一层楼! -使用[LeetHub](https
- ekpmeasure:用于各种实验的计算机控制代码存储库
- vue+node+mongodb完成的拼多多移动端仿站(练习项目).zip
- 查找:查找R的完整功能定义,包括编译后的代码,S3和S4方法
- CONTROLLER.zip_单片机开发_C++_
