Python操作Kafka:分布式流处理详解
109 浏览量
更新于2024-08-29
收藏 981KB PDF 举报
"本文主要介绍了Python操作分布式流处理系统Kafka的相关知识,包括Kafka的基本概念、核心组件以及其分布式架构。"
Kafka是一个强大的分布式流处理平台,它设计的目标是提供高吞吐量、低延迟的消息传递能力。在Python中,我们可以利用各种库(如kafka-python)来与Kafka进行交互,实现数据的生产和消费。
Kafka的核心组件主要包括:
1. **Producer** - 消息生产者是系统中发布消息的客户端,它们负责将数据发送到Kafka的特定主题(topic)。
2. **Consumer** - 消息消费者则是消息的使用者,它们从Kafka服务器上获取并处理消息。消费者通过订阅特定的主题来消费消息。
3. **Topic** - 主题是逻辑上的分类,用户可以创建和配置多个主题,每个主题可以承载相关的消息流。Producer将消息发送到Topic,Consumer则从Topic中读取消息。
4. **Partition** - 每个主题可以被分成多个分区(partition),这是一个重要的概念,因为它提供了并行处理的能力。每个分区内部的消息是有序的,具有唯一的偏移量(offset)。
5. **Broker** - Kafka集群由一个或多个服务器(broker)组成,每个服务器都可以存储主题的分区。
6. **ConsumerGroup** - 消费者分组是Kafka的另一个关键特性,同一组内的消费者协同工作,共同消费主题中的消息,确保消息只被消费一次(除非重新设置offset)。
7. **Offset** - 消息在分区中的偏移量是其在分区中的唯一位置标识,消费者可以通过offset来定位和消费特定的消息。
Kafka的分布式架构使得它在大规模数据处理中表现出色。消息按照键值(key)进行分区,保证了具有相同键的消息会存储在同一partition内,实现数据的局部性。如果消息无键,则采用轮询策略分配到不同的partition。这种设计不仅提高了并发性,还允许在多个服务器之间进行负载均衡。
在Python中操作Kafka,开发者可以使用`kafka-python`库,它提供了与Kafka集群交互的API,包括创建Producer实例来发送消息,以及创建Consumer实例来订阅和消费消息。例如,创建一个Producer并发送消息:
```python
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers='localhost:9092')
producer.send('my-topic', key=b'key', value=b'value')
```
同样,创建一个Consumer来消费消息:
```python
from kafka import KafkaConsumer
consumer = KafkaConsumer('my-topic',
group_id='my-group',
bootstrap_servers=['localhost:9092'])
for message in consumer:
print(message.value)
```
总体来说,Python操作Kafka提供了灵活的数据处理和传输方案,适用于实时流数据处理、日志收集、事件驱动的微服务架构等多种场景。通过理解Kafka的基本概念和Python中的操作方式,开发者能够有效地构建高效、可靠的分布式数据处理系统。
Python操作分布式流处理系统操作分布式流处理系统Kafka
什么是Kafka
Kafka是一个分布式流处理系统,流处理系统使它可以像消息队列一样publish或者subscribe消息,分布式提供了容错性,并发
处理消息的机制。
Kafka的基本概念
kafka运行在集群上,集群包含一个或多个服务器。kafka把消息存在topic中,每一条消息包含键值(key),值(value)和时
间戳(timestamp)。
kafka有以下一些基本概念:
Producer - 消息生产者,就是向kafka broker发消息的客户端。
Consumer - 消息消费者,是消息的使用方,负责消费Kafka服务器上的消息。
Topic - 主题,由用户定义并配置在Kafka服务器,用于建立Producer和Consumer之间的订阅关系。生产者发送消息到指定的
Topic下,消息者从这个Topic下消费消息。
Partition - 消息分区,一个topic可以分为多个 partition,每个
partition是一个有序的队列。partition中的每条消息都会被分配一个有序的
id(offset)。
Broker - 一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
Consumer Group - 消费者分组,用于归组同类消费者。每个consumer属于一个特定的consumer group,多个消费者可以共
同消息一个Topic下的消息,每个消费者消费其中的部分消息,这些消费者就组成了一个分组,拥有同一个分组名称,通常也
被称为消费者集群。
Offset - 消息在partition中的偏移量。每一条消息在partition都有唯一的偏移量,消息者可以指定偏移量来指定要消费的消息。
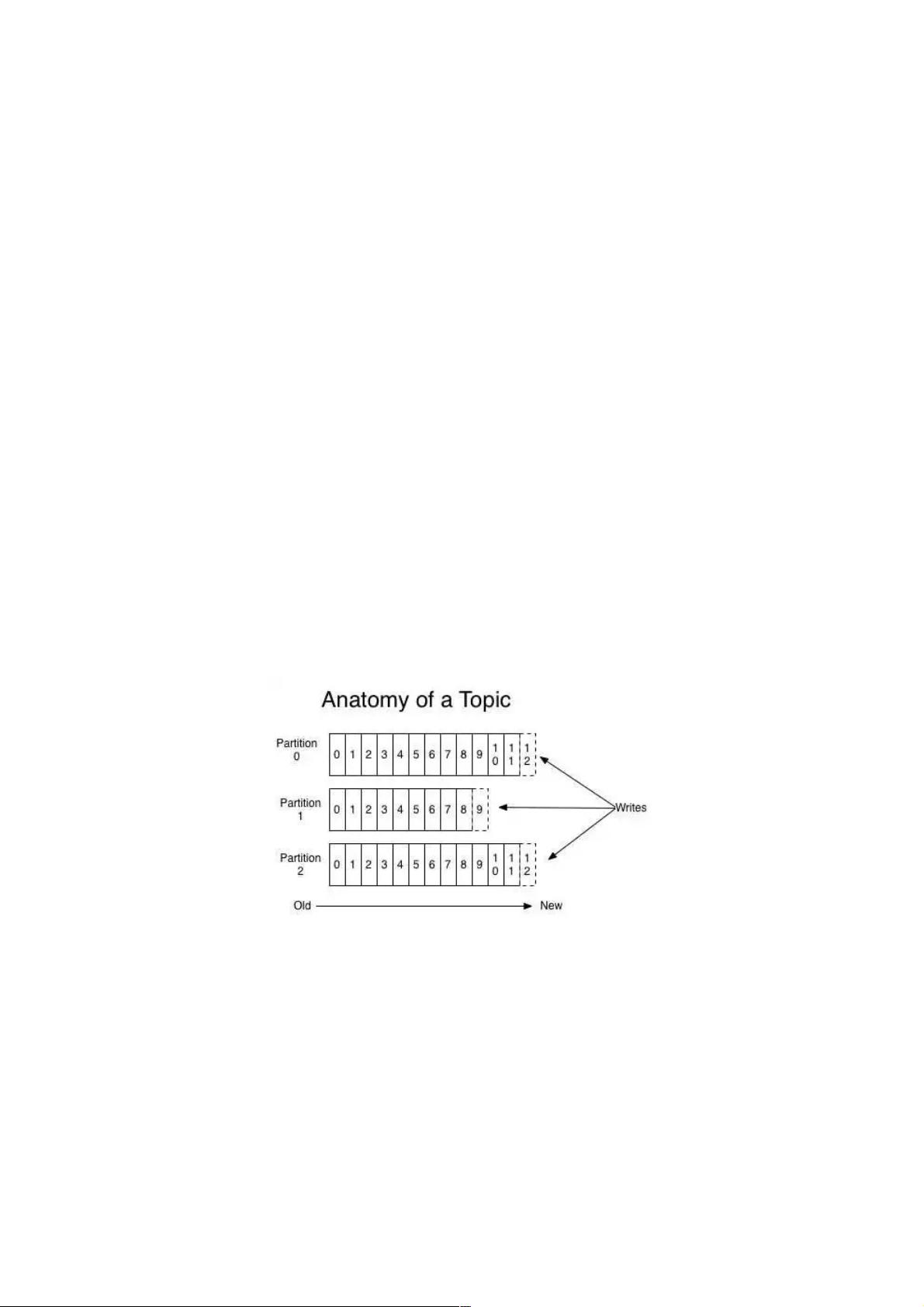
Kafka分布式架构
如上图所示,kafka将topic中的消息存在不同的partition中。如果存在键值(key),消息按照键值(key)做分类存在不同的
partiition中,如果不存在键值(key),消息按照轮询(Round Robin)机制存在不同的partition中。默认情况下,键值
(key)决定了一条消息会被存在哪个partition中。
partition中的消息序列是有序的消息序列。kafka在partition使用偏移量(offset)来指定消息的位置。一个topic的一个partition
只能被一个consumer group中的一个consumer消费,多个consumer消费同一个partition中的数据是不允许的,但是一个
consumer可以消费多个partition中的数据。
kafka将partition的数据复制到不同的broker,提供了partition数据的备份。每一个partition都有一个broker作为leader,若干个
broker作为follower。所有的数据读写都通过leader所在的服务器进行,并且leader在不同broker之间复制数据。
下载后可阅读完整内容,剩余7页未读,立即下载
2019-08-11 上传
2021-08-31 上传
2023-10-31 上传
2021-04-11 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-07-27 上传

weixin_38721252
- 粉丝: 5
- 资源: 936
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM Java项目:StudentInfo 数据管理与可视化分析
- pyedgar:Python库简化EDGAR数据交互与文档下载
- Node.js环境下wfdb文件解码与实时数据处理
- phpcms v2.2企业级网站管理系统发布
- 美团饿了么优惠券推广工具-uniapp源码
- 基于红外传感器的会议室实时占用率测量系统
- DenseNet-201预训练模型:图像分类的深度学习工具箱
- Java实现和弦移调工具:Transposer-java
- phpMyFAQ 2.5.1 Beta多国语言版:技术项目源码共享平台
- Python自动化源码实现便捷自动下单功能
- Android天气预报应用:查看多城市详细天气信息
- PHPTML类:简化HTML页面创建的PHP开源工具
- Biovec在蛋白质分析中的应用:预测、结构和可视化
- EfficientNet-b0深度学习工具箱模型在MATLAB中的应用
- 2024年河北省技能大赛数字化设计开发样题解析
- 笔记本USB加湿器:便携式设计解决方案
