有指导数据挖掘:目标变量、模型构建与业务应用
9 浏览量
更新于2024-08-30
收藏 182KB PDF 举报
构建一个有指导的数据挖掘模型是一种系统性的过程,它旨在利用统计分析和机器学习技术从大量数据中提取有价值的信息,以解决特定的业务问题。这个模型的关键在于其目标导向性,即明确定义和估计目标变量,而不是泛泛地寻找模式。
首先,理解并定义目标变量是构建模型的基础。目标变量通常是我们希望通过数据分析来预测或优化的结果,例如在营销活动中,可能的目标是二元响应,即客户是否会回应邮件或直接邮寄。通过分析历史客户数据,尤其是那些已响应类似活动的客户,我们可以构建一个模型,以识别出那些具有相似特征的潜在目标群体。
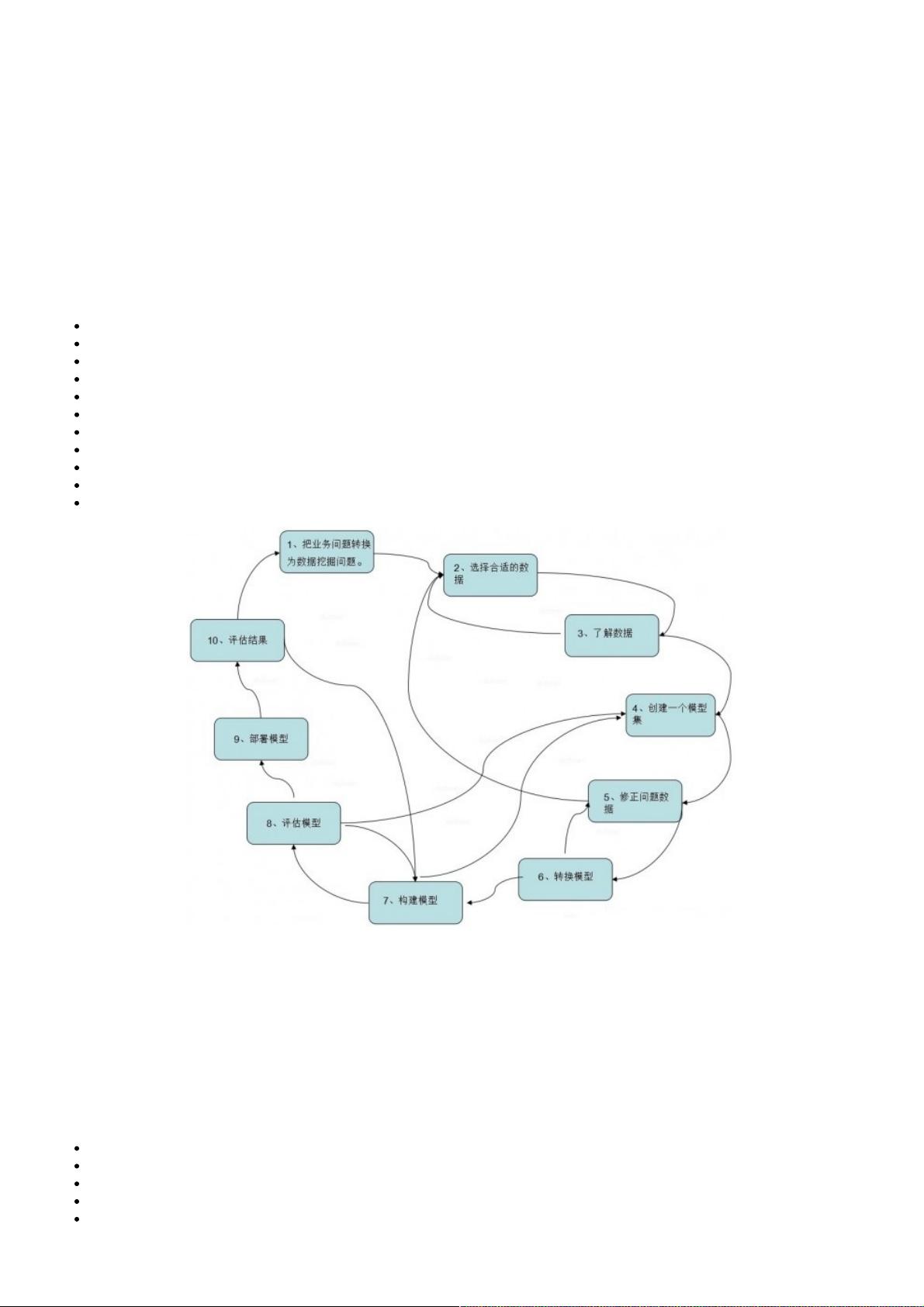
在构建过程中,分为几个关键步骤:
1. 业务问题转换:将实际的商业问题(如客户流失预测、欺诈检测等)转化为数据挖掘问题,确保目标清晰。
2. 数据准备:选择与目标相关的数据,包括清洗、整合和预处理,确保数据质量。
3. 模型构建:选择合适的算法,如决策树、逻辑回归或神经网络,创建模型集,并不断优化以提高准确性。
4. 模型评估:通过预测和解析模型,评估模型的稳定性和有效性,可能需要进行交叉验证和调整参数。
5. 模型部署与监控:将模型应用到实际环境中,持续监测和优化,以确保其在实际业务中的效果。
6. 反馈循环:根据模型的实际表现,不断调整和迭代,形成一个持续改进的过程。
有指导的数据挖掘强调的是目标导向和业务驱动,而非盲目挖掘。它要求数据科学家深入了解业务背景,这样才能有效地将数据转化为可操作的洞察,进而提升企业的决策效率和竞争力。只有这样,数据挖掘才能真正发挥其价值,帮助企业发现新的机会,减少风险,提高业绩。
构建一个有指导的数据挖掘模型构建一个有指导的数据挖掘模型
什么是有指导的数据挖掘方法模型,以及数据挖掘如何构建模型。在构建一个有指导的数据挖掘模型,首先要理解和定义一些
模型试图估计的目标变量。
数据挖掘的目的,就是从数据中找到更多的优质用户。接着上篇继续探讨有指导数据挖掘方法模型。什么是有指导的数据挖掘
方法模型,以及数据挖掘如何构建模型。在构建一个有指导的数据挖掘模型,首先要理解和定义一些模型试图估计的目标变
量。一个典型的案例,二元响应模型,如为直接邮寄和电子邮件营销活动选择客户的模型。模型的构建选择历史客户数据,这
些客户响应了以前类似的活动。有指导数据挖掘的目的就是找到更多类似的客户,以提高未来活动的响应。
这构造有指导的数据挖掘模型的过程中,首先要定义模型的结构和目标。二、增加响应建模。三、考虑模型的稳定性。四、通首先要定义模型的结构和目标。二、增加响应建模。三、考虑模型的稳定性。四、通
过预测模型、剖析模型来讨论模型的稳定性。过预测模型、剖析模型来讨论模型的稳定性。下面我们将从具体的步骤谈起,如何构造一个有指导的数据挖掘模型。
有指导数据挖掘方法:有指导数据挖掘方法:
把业务问题转换为数据挖掘问题
选择合适的数据
认识数据
创建一个模型集
修复问题数据
转换数据以揭示信息
构建模型
评估模型
部署模型
评估结果
重新开始
步骤:
1、把业务问题转换为数据挖掘问题、把业务问题转换为数据挖掘问题
《爱丽丝梦游仙境》中,爱丽丝说“我不关心去哪儿”。猫说:“那么,你走哪条路都没什么问题”。爱丽丝又补充到:只要我能
到达某个地方。猫:“哦,你一定能做到这一点,只要你能走足够长的时间。”
猫可能有另外一个意思,如果没有确定的目的地,就不能确定你是否已经走了足够长的时间。
有指导数据挖掘项目的目标就是找到定义明确的业务问题的解决方案。一个特定项目的数据挖掘目标不应该是广泛的、通用的
条例。应该把那些广泛的目标,具体化,细化,深入观察客户行为可能变成具体的目标:
确定谁是不大可能续订的客户
为以家庭为基础的企业客户设定一个拨打计划,该计划将减少客户的退出率
确定那些网络交易可能是欺诈
如果葡萄酒和啤酒已停止销售,列出处于销售风险的产品
根据当前市场营销策略,预测未来三年的客户数量
有指导数据挖掘往往作为一个技术问题,即找到一个模型以解释一组输入变量与目标变量的关系。这往往是数据挖掘的中心,
下载后可阅读完整内容,剩余3页未读,立即下载
2023-05-15 上传
2023-06-19 上传
2023-04-25 上传
2023-04-20 上传
2023-07-17 上传
2023-11-15 上传
2023-06-10 上传

weixin_38653508
- 粉丝: 2
- 资源: 903
 我的内容管理
展开
我的内容管理
展开







最新资源
- 李兴华Java基础教程:从入门到精通
- U盘与硬盘启动安装教程:从菜鸟到专家
- C++面试宝典:动态内存管理与继承解析
- C++ STL源码深度解析:专家级剖析与关键技术
- C/C++调用DOS命令实战指南
- 神经网络补偿的多传感器航迹融合技术
- GIS中的大地坐标系与椭球体解析
- 海思Hi3515 H.264编解码处理器用户手册
- Oracle基础练习题与解答
- 谷歌地球3D建筑筛选新流程详解
- CFO与CIO携手:数据管理与企业增值的战略
- Eclipse IDE基础教程:从入门到精通
- Shell脚本专家宝典:全面学习与资源指南
- Tomcat安装指南:附带JDK配置步骤
- NA3003A电子水准仪数据格式解析与转换研究
- 自动化专业英语词汇精华:必备术语集锦
