数据挖掘十大算法解析
需积分: 50 32 浏览量
更新于2024-07-27
收藏 783KB PDF 举报
“这篇论文列出了IEEE国际数据挖掘会议(ICDM)在2006年评选出的十大数据挖掘算法,包括C4.5、k-Means、SVM、Apriori、EM、PageRank、AdaBoost、kNN、朴素贝叶斯和CART。这些算法对研究社区具有重大影响,并涵盖了分类、聚类、关联规则等多个领域。”
在数据挖掘领域,掌握一些经典算法是至关重要的。以下是对这些算法的详细介绍:
1. **C4.5**:由Ross Quinlan开发,是ID3决策树算法的升级版。C4.5通过信息增益率来选择最优特征,可以处理连续和离散属性,同时能处理缺失值,常用于分类任务。
2. **k-Means**:是一种无监督学习的聚类算法,通过迭代寻找最佳的k个聚类中心,将数据分配到最近的聚类。k值的选择会影响结果,算法对初始聚类中心的选择敏感。
3. **支持向量机(SVM)**:由Vapnik等人提出,基于结构风险最小化原则,通过构造最大边距超平面实现分类或回归。SVM在小样本、非线性及高维模式识别中有很好的表现。
4. **Apriori**:关联规则学习的经典算法,用于发现项集之间的频繁模式。Apriori利用了“频繁集的子集必须也是频繁集”的性质,减少了数据库扫描次数,提高了效率。
5. **期望最大化(EM)**:主要用于含有隐变量的概率模型参数估计。EM算法交替执行E(期望)步和M(最大化)步,逐步提高模型的似然性。
6. **PageRank**:Google的创始人Larry Page和Sergey Brin提出的网页排名算法,衡量网页的重要性。PageRank考虑了网页之间的链接关系,高权重的页面链接到的页面也会获得较高权重。
7. **AdaBoost**:是一种集成学习算法,通过迭代调整训练数据的权重,使弱分类器逐渐增强成为强分类器。每次迭代后,错误分类的数据权重会增加,使得下一次迭代的分类器更关注这些数据。
8. **k近邻(k-Nearest Neighbors, kNN)**:简单的分类和回归方法,根据最近邻的k个样本的类别决定新样本的类别。k的选择和距离度量对结果有直接影响。
9. **朴素贝叶斯(Naive Bayes)**:基于贝叶斯定理的分类算法,假设特征之间相互独立。尽管“朴素”,但在许多实际问题中仍表现出良好性能,如垃圾邮件过滤。
10. **分类与回归树(Classification and Regression Tree, CART)**:与C4.5类似,但CART不仅用于分类,还可以进行回归分析。它使用基尼不纯度或均方误差作为分裂标准。
这些算法在数据挖掘中扮演着核心角色,不断推动着该领域的发展。随着大数据和机器学习的快速发展,对这些算法的理解和应用能力已成为数据科学家的基本技能。每个算法都有其独特的优势和局限性,理解并灵活运用它们可以帮助我们更好地挖掘数据中的有价值信息。
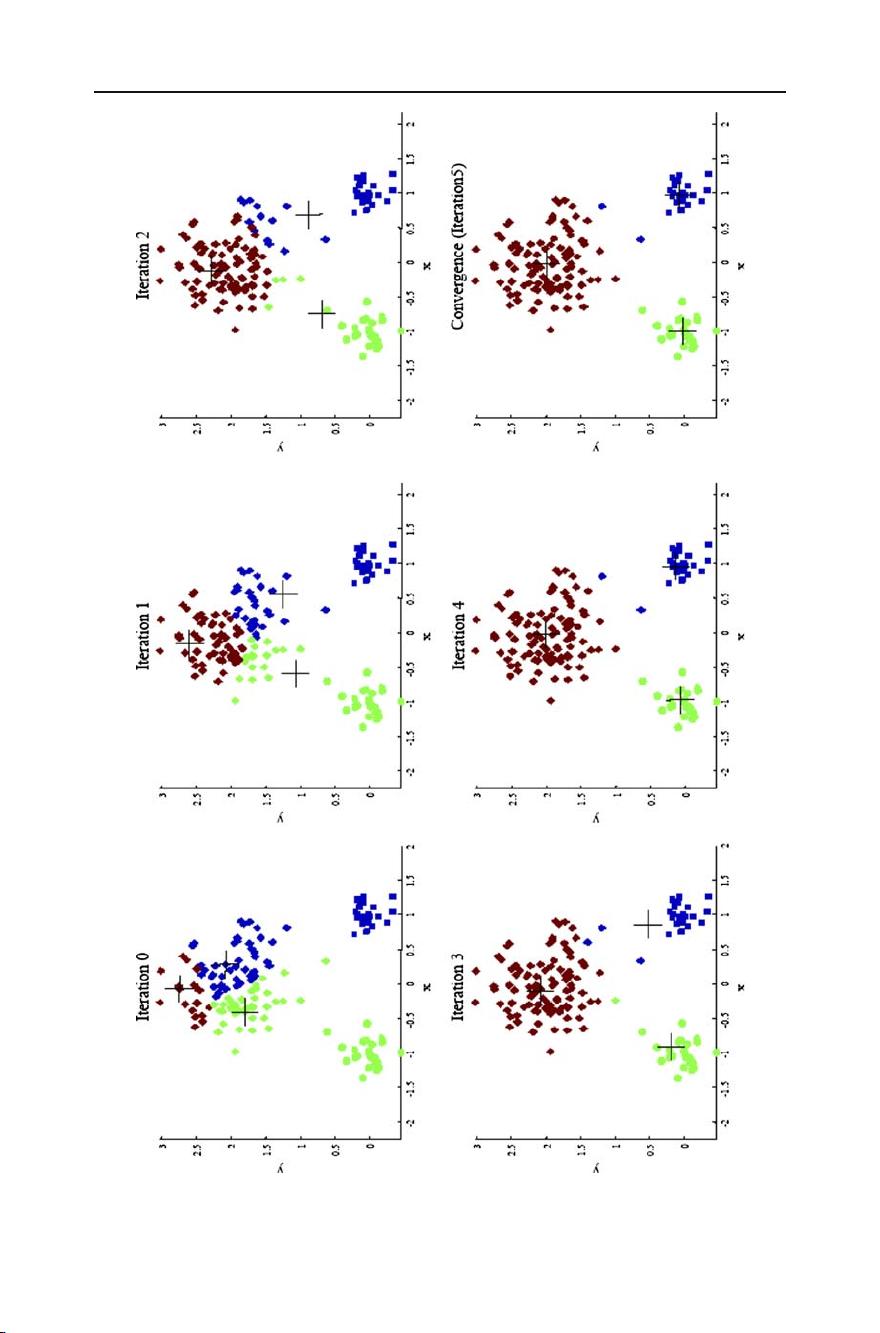
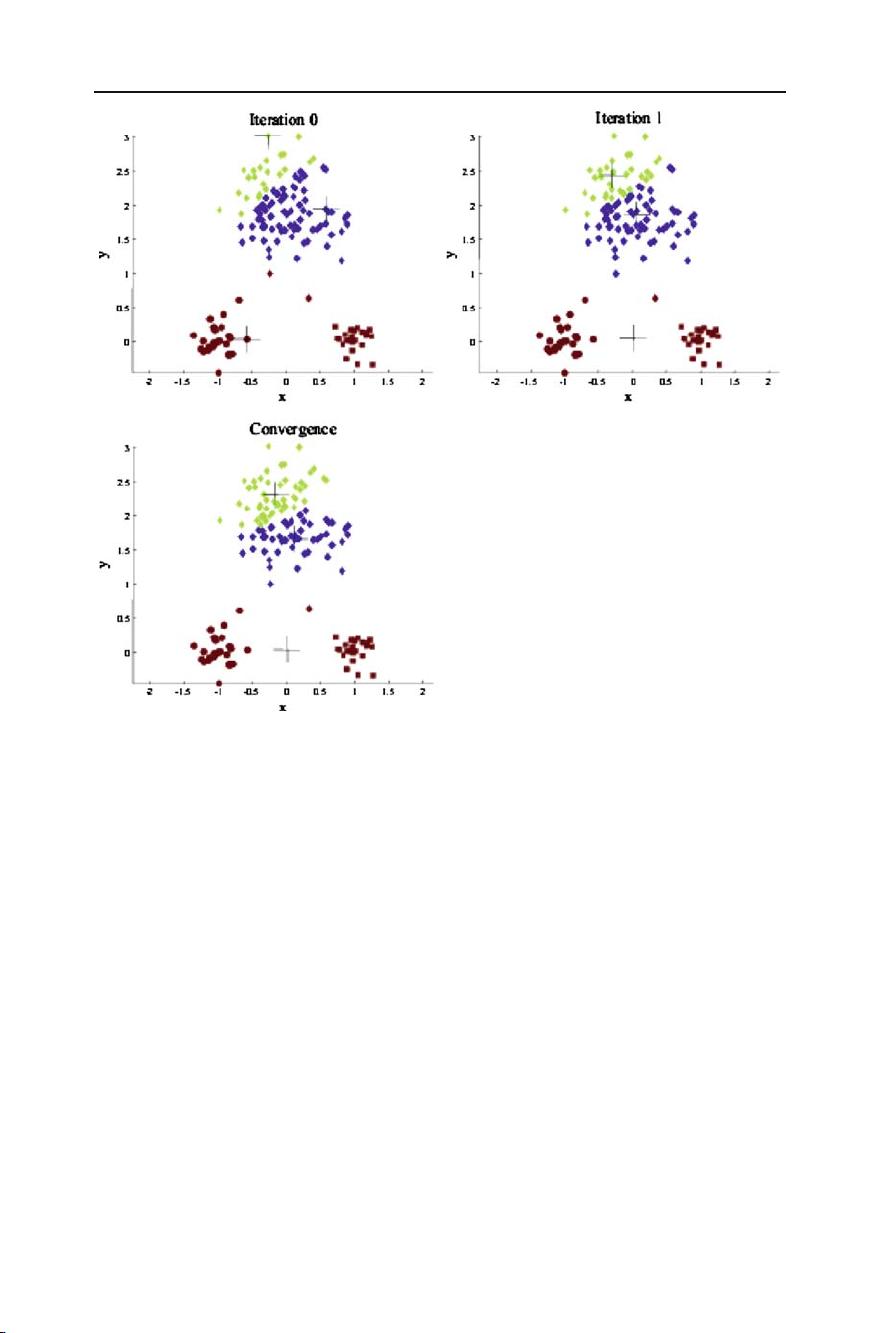
Top 10 algorithms in data mining 7
Fig. 1 Changes in cluster representative locations (indicated by ‘+’ signs) and data assignments (indicated
by color) during an execution of the k-means algorithm
123
剩余36页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-09-29 上传
2012-07-25 上传
2010-08-19 上传
2022-09-19 上传
2021-08-11 上传
2021-05-22 上传

dyllian
- 粉丝: 1
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- angular-prism:在Angular应用程序中使用Prism语法荧光笔
- FriendList:该Web应用程序可以下载您的Facebook朋友列表,并允许您对它们进行排序
- 实用程序_1fdp:程序基础知识1
- 灰色按钮克星源码例程.zip易语言项目例子源码下载
- docker-traefik::mouse:使用Traefik代理Docker容器进行* .localhost开发
- lidlab:Lidstrom 实验室@华盛顿大学共享代码
- savagejsx:将svg转换为React成分的实用程序
- Leetcode-optimized-solution-in-java-with-clear-explanation
- A_CNS_API:HIMS CNS API代码
- laas:从数据驱动的角度出发,基于指令库的逻辑汇编和分发
- Media XW-开源
- Java资源 javaeasycms-v2.0.zip
- Lab7_WhoWroteIt
- 烟花newyearFireworks-master.zip
- JanChaMVC
- Maliwan-开源
