预训练语言模型探索:从ELMo到BERT
需积分: 9 100 浏览量
更新于2024-07-14
收藏 2.24MB PPTX 举报
“NLP预训练模型.pptx”是一份关于自然语言处理(NLP)领域预训练模型的学习资料,涵盖了多种预训练模型的介绍、结构、规模、分析、评价以及优化方法。其中包括了ELMo、CoVe、BERT、XLNet、RoBERTa、ALBERT、GPT、MASS、BART、ERNIE和ELECTRA等多个模型。这份资料还提到了基于LSTM、基于Transformer的模型架构,以及模型压缩和优化技术。
在NLP中,预训练模型是通过大量无标注文本数据进行训练,学习语言的一般性特征,然后在特定任务上进行微调,以提高任务性能。以下是部分模型的详细说明:
1. ELMo(Embeddings from Language Models):由两个单向LSTM构成的双向语言模型,它利用上下文信息动态生成词向量,解决了单词的多义性问题。在下游任务中,ELMo的各层表示可以被整合,作为输入词向量,提高了模型的表现。
2. CoVe(Contextualized Word Vectors):基于LSTM的预训练模型,首先在机器翻译任务上进行预训练,然后提取出的Embedding层和Encoder层用于新的任务,增强了模型在文本分类、问答和语义推理等任务的效果。
3. BERT(Bidirectional Encoder Representations from Transformers):引入了Transformer架构,采用自注意力机制,提出了Masked Language Modeling和Next Sentence Prediction两种预训练任务,实现了对文本的双向理解,显著提升了NLP任务的性能。
4. Transformer:核心是自注意力机制和多头注意力,取代了传统的RNN和CNN,使得模型并行计算成为可能,大大提高了训练效率。
5. GPT(Generative Pre-trained Transformer):与BERT相反,GPT是自右向左的预训练模型,主要用于生成任务,如文本生成和对话系统。
6. ALBERT(A Lite BERT):通过因子分解和句子级跨层参数共享,实现了更小的模型尺寸,但保持了高性能。
7. ERNIE(Enhanced Representation through kNowledge Integration):结合了知识图谱信息,增强了模型对语义的理解能力。
8. ELECTRA(Efficiently Learning an Encoder that Classifies Tokens and Reconstructs Text):通过生成对抗网络(GAN)训练,提出“判别式生成”策略,减少了训练时间。
这些模型的不断发展和优化,推动了NLP领域的进步,使得机器在理解和生成人类语言方面的能力大幅提升。预训练模型的广泛应用包括情感分析、问答系统、机器翻译、文本生成、信息检索等多个领域。了解并掌握这些模型的原理和应用,对于NLP研究者和从业者来说至关重要。
CNN
卷积层
池化层
全连接层
RNN
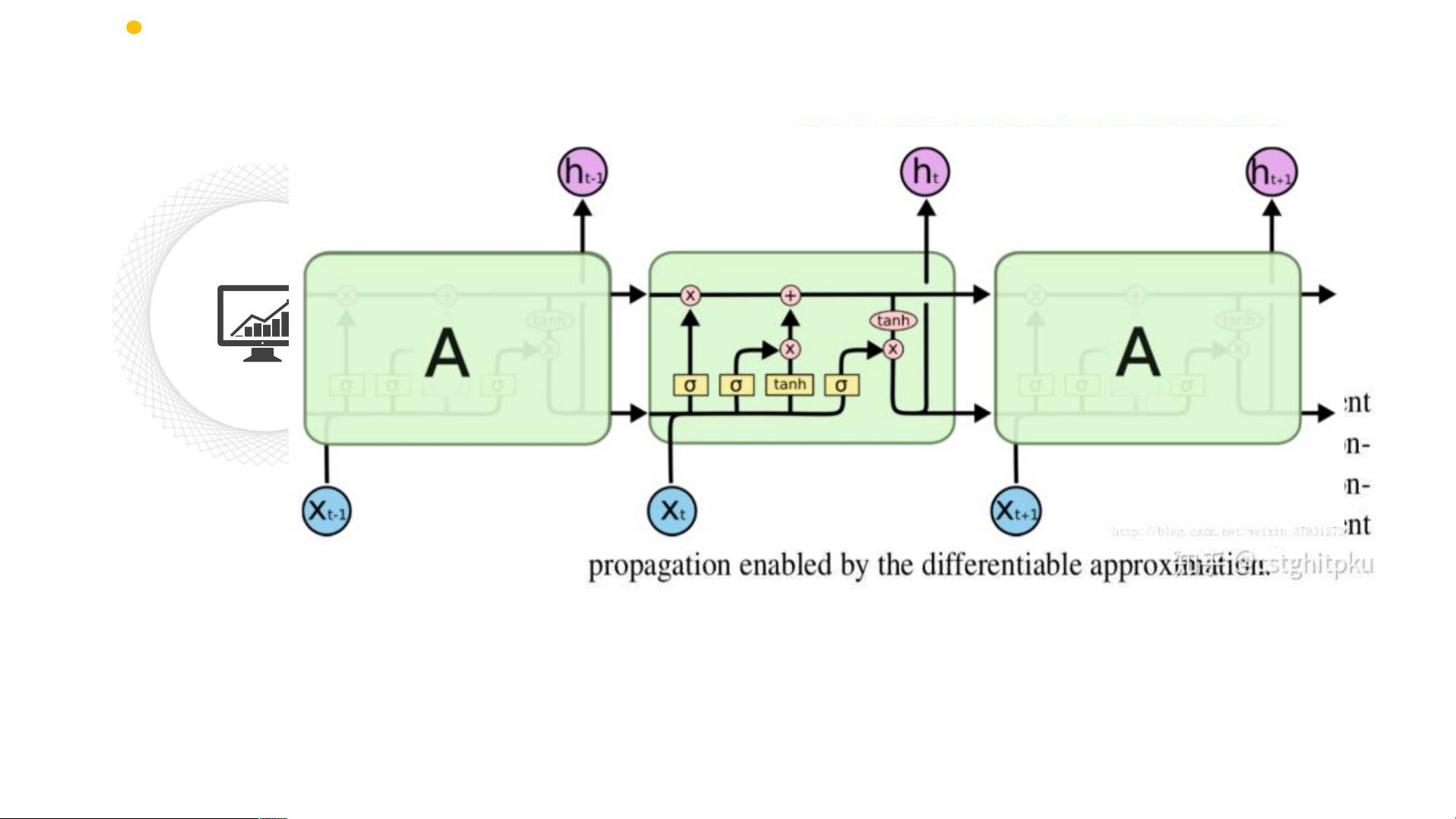
LSTM: 长短期记忆网络
遗忘门
输入门
输出门
GAN
生成器
判别器
基本原理
剩余23页未读,继续阅读
110 浏览量
884 浏览量
680 浏览量
112 浏览量
146 浏览量
2025-01-03 上传
161 浏览量
315 浏览量
181 浏览量

我bu
- 粉丝: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- 32位instantclient_11_2使用指南及配置教程
- kWSL在WSL上轻松安装KDE Neon 5.20无需额外软件
- phpwebsite 1.6.2完整项目源码及使用教程下载
- 实现UITableViewController完整截图的Swift技术
- 兼容Android 6.0+手机敏感信息获取技术解析
- 掌握apk破解必备工具:dex2jar转换技术
- 十天掌握DIV+CSS:WEB标准实践教程
- Python编程基础视频教程及配套源码分享
- img-optimize脚本:一键压缩jpg与png图像
- 基于Android的WiFi局域网即时通讯技术实现
- Android实用工具库:RecyclerView分段适配器的使用
- ColorPrefUtil:Android主题与颜色自定义工具
- 实现软件自动更新的VC源码教程
- C#环境下CS与BS模式文件路径获取与上传教程
- 学习多种技术领域的二手电子产品交易平台源码
- 深入浅出Dubbo:JAVA分布式服务框架详解
