Pandas数据操作指南:行与列的选取与筛选
183 浏览量
更新于2024-08-31
1
收藏 170KB PDF 举报
"pandas 选取行和列数据的方法详解"
在Python数据分析领域,Pandas库是不可或缺的一部分,它提供了高效的数据处理能力。本篇将详细讲解如何在Pandas中选取行和列数据,以帮助你更好地理解和应用这些方法。
1. 选择列
在Pandas DataFrame中,你可以通过两种方式选取列。首先,你可以直接通过列名来获取Series对象,如`df['name']`。如果你想要获取多列,可以传递一个包含列名的列表,例如`df[['name', 'price']]`,这将返回一个新的DataFrame,包含你指定的列。
2. 选择行
选择行通常涉及到筛选数据。Pandas提供了`loc`和`iloc`方法来实现这一点。`loc`方法基于标签(即行索引)进行选择,而`iloc`则基于位置(即整数索引)进行选择。例如,如果你想要选取第一行,可以使用`df.loc[0]`或`df.iloc[0]`。
当你需要根据条件筛选行时,可以利用布尔索引。例如,如果要选取`quantity`小于0的所有行,可以编写如下代码:
```python
criteria = df['quantity'] < 0
df_filtered = df[criteria]
```
对于多个条件的筛选,可以使用逻辑运算符。例如,筛选`quantity`小于0且`unitprice`大于50的行:
```python
criteria = (df['quantity'] < 0) & (df['unitprice'] > 50)
df_filtered = df[criteria]
```
注意,这里的`&`代表逻辑与(AND),`|`代表逻辑或(OR)。如果要筛选`quantity`大于30或`unitprice`大于50的行,可以写成:
```python
criteria = (df["quantity"] > 30) | (df["unitprice"] > 50)
df_filtered = df[criteria]
```
3. 高级选择
除了基本的选择方式,Pandas还提供了一些高级选择方法,如`query()`函数,它允许你用类似SQL的语法来筛选数据。例如:
```python
df.query("quantity < 0 and unitprice > 50")
```
4. 花式索引(Fancy Indexing)
花式索引允许你通过列表或其他序列选择行,例如:
```python
index_to_select = [0, 2, 4]
df.loc[index_to_select]
```
5. 分组操作
如果你需要根据某一列或几列的值对数据进行分组并进行操作,可以使用`groupby()`函数。例如,按产品类别分组并计算每个类别的总销售额:
```python
grouped = df.groupby('category')['total_sales'].sum()
```
6. 排序
可以使用`sort_values()`对DataFrame按一列或多列进行排序:
```python
df_sorted = df.sort_values(by=['total_sales'], ascending=False)
```
通过熟练掌握以上各种选择和筛选技巧,你将能够有效地处理和分析Pandas中的数据。结合实际的数据集进行实践,将有助于你更好地理解这些概念,并提升数据分析的能力。
pandas 选取行和列数据的方法详解选取行和列数据的方法详解
主要介绍了pandas 选取行和列数据的方法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有
一定的参考学习价值,需要的朋友可以参考下
前言前言
本文介绍在 pandas 中如何读取数据行列的方法。数据由行和列组成,在数据库中,一般行被称作记录 (record),列被称作字
段 (field)。回顾一下我们对记录和字段的获取方式:一般情况下,字段根据名称获取,记录根据筛选条件获取。比如获取
student_id 和 studnent_name 两个字段;记录筛选,比如 sales_amount 大于 10000 的所有记录。对于熟悉 SQL 语句的人来
说,就是下面的语句:
select student_id, student_name
from exam_scores
where chinese >= 90 and math >= 90
上面的 SQL 语句表示从考试成绩表 (exam_scores) 中,筛选出语文和数学都大于或等于 90 分的所有学生 id 和 name。学习
pandas 数据获取,推荐这种以数据处理的目标为导向的方式,而不是被动的按 pandas 提供的 loc, iloc的语法中,一条条顺序
学习。
本篇我们要分析的关于销售数量和金额的一组数据,数据存放在 csv 文件中。示例数据我在 github 上放了一份,方便大家对
照练习。
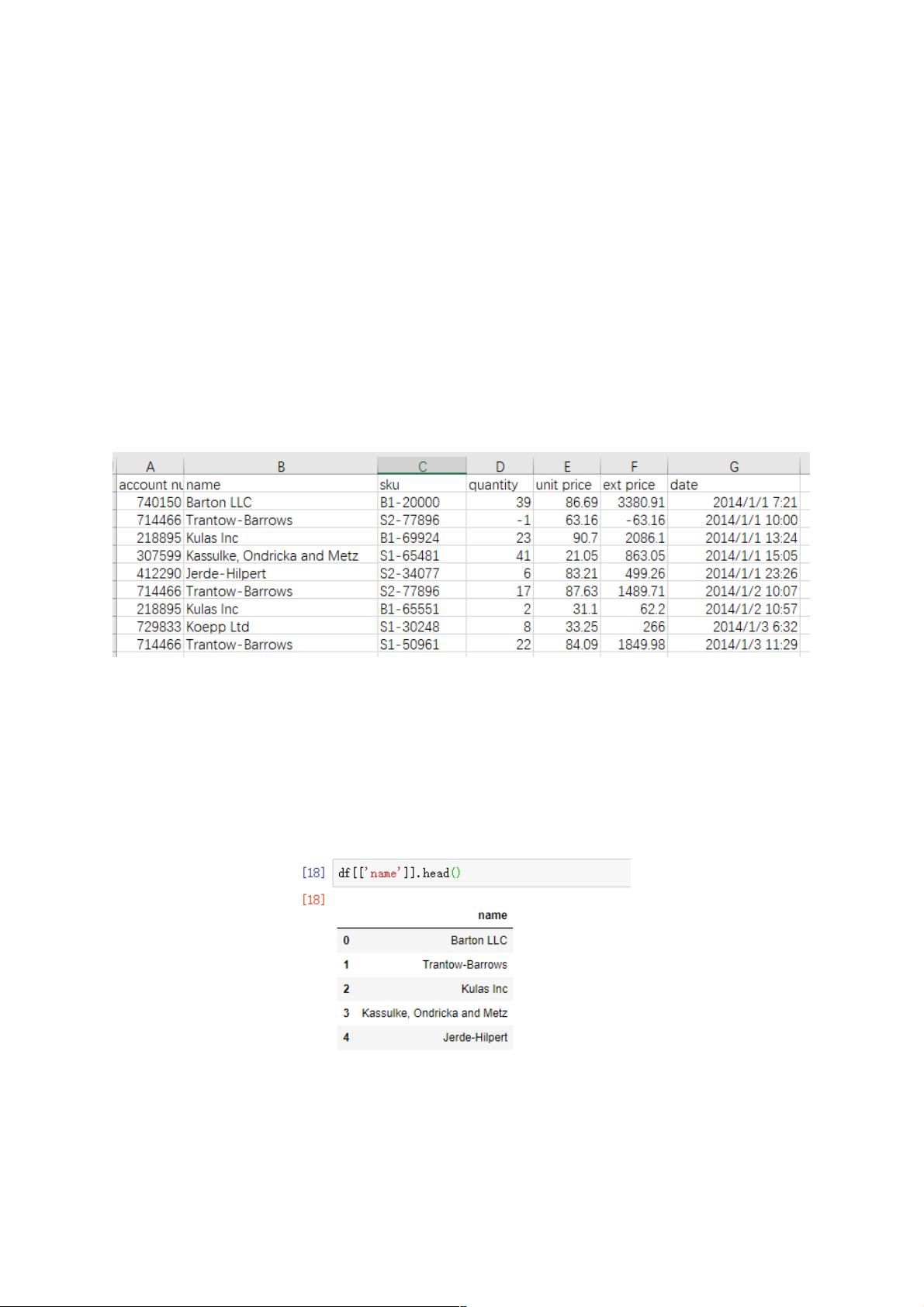
选择列选择列
以下两种方法返回 Series 类型:
import pandas as pd
df = pd.read_csv('sample-salesv3.csv')
df.name
# 或者
df['name']
如果需要返回 DataFrame 格式,使用 list 作为参数。为了方便说明,给出在 jupyter notebook 中显示的界面。
如果需要选取多列,传给 DataFrame 一个包含列名的 list:
下载后可阅读完整内容,剩余3页未读,立即下载
1736 浏览量
116 浏览量
313 浏览量
2890 浏览量
9332 浏览量
1943 浏览量
17042 浏览量
890 浏览量
1472 浏览量

weixin_38621427
- 粉丝: 10
 我的内容管理
展开
我的内容管理
展开







最新资源
- 32位instantclient_11_2使用指南及配置教程
- kWSL在WSL上轻松安装KDE Neon 5.20无需额外软件
- phpwebsite 1.6.2完整项目源码及使用教程下载
- 实现UITableViewController完整截图的Swift技术
- 兼容Android 6.0+手机敏感信息获取技术解析
- 掌握apk破解必备工具:dex2jar转换技术
- 十天掌握DIV+CSS:WEB标准实践教程
- Python编程基础视频教程及配套源码分享
- img-optimize脚本:一键压缩jpg与png图像
- 基于Android的WiFi局域网即时通讯技术实现
- Android实用工具库:RecyclerView分段适配器的使用
- ColorPrefUtil:Android主题与颜色自定义工具
- 实现软件自动更新的VC源码教程
- C#环境下CS与BS模式文件路径获取与上传教程
- 学习多种技术领域的二手电子产品交易平台源码
- 深入浅出Dubbo:JAVA分布式服务框架详解
