YOLOv4训练自定义数据集:详细步骤与理解
84 浏览量
更新于2024-08-31
收藏 719KB PDF 举报
"这篇资源主要介绍了如何使用yolov4训练自定义数据集的模型,作者分享了个人的学习经历和操作流程,强调了理解模型训练原理的重要性。文章中提到,训练环境选择Ubuntu,因为Linux版本的操作更为简洁。作者参考了另一篇文章来理清训练思路,并对数据进行了预处理,包括将标注文件与图片分开放置,然后通过Python脚本生成XML文件。"
在训练自己的数据模型时,YOLOv4是一个强大的目标检测框架,它在YOLOv3的基础上进行了优化,提高了检测精度和速度。YOLO(You Only Look Once)是一种实时的目标检测系统,适用于各种应用场景,如自动驾驶、监控视频分析等。训练自定义数据集的关键步骤如下:
1. **数据准备**:首先,你需要用标注工具,如LabelMe,对图像进行标注,生成包含类别和边界框信息的JSON文件。对于YOLO,通常需要将这些标注信息转换成YOLO所需的格式,例如XML或TXT文件。在这个例子中,作者将JSON文件分别放在train和val文件夹中,用于训练和验证。
2. **数据预处理**:预处理阶段是将标注信息转化为模型可读格式的过程。这通常涉及将标注文件转换成YOLO的输入格式,即每个对象的边界框坐标和类别ID。在这个过程中,可能还需要对图像进行缩放、归一化或增强,以增加模型的泛化能力。
3. **配置文件修改**:在开始训练前,你需要修改YOLO的配置文件(如`yolov4.cfg`),设置正确的类别数量、批处理大小、学习率等参数。此外,需要指定训练数据和验证数据的路径。
4. **编译Darknet**:Darknet是YOLO的开源实现,需要编译以适应你的硬件环境。在Ubuntu上,可以通过Makefile进行编译。确保安装了必要的依赖库,如OpenCV和CUDA(如果使用GPU加速)。
5. **训练过程**:使用`darknet detector train`命令启动训练,提供配置文件和数据列表文件。训练过程中,模型会逐步学习并更新权重,同时保存中间结果,以便在需要时恢复训练。
6. **模型评估与微调**:训练过程中应定期检查模型的性能,使用验证集进行评估。如果发现模型在某些类别上表现不佳,可以调整超参数,如学习率,或者采用早停策略来防止过拟合。
7. **测试与部署**:训练完成后,使用`darknet detector test`命令对新图像进行预测,验证模型效果。模型可以被整合到实际应用中,比如嵌入到实时视频流处理中。
理解训练流程的每一个环节对于优化模型性能至关重要。作者从当初对YOLOv3的一知半解到如今能深入理解并应用YOLOv4,展示了理论知识和实践经验相结合的重要性。通过遵循这些步骤,你可以成功地训练出针对自己特定数据集的高效目标检测模型。
yolov4训练自己的数据模型训练自己的数据模型
看了下yolov4的作者给的操作说明,链接如下:https://github.com/AlexeyAB/darknet#how-to-compile-on-linux-using-make,有兴趣的可以去看看,总结起来,跟yolov3的操作方式基
本一样,所以现在记录一下这次的整个操作流程。
在几个月前,一直在准备一个项目,那个项目已经让人用lableme这个标注软件标注好了图片,但是直到现在,这个项目依旧还没有动工的苗头,估计是悬了,之前也用标注好的数据
进行过yolov3的训练,但是说实话,那时候对于yolov3是一头雾水,只知道按照他人的给的操作流程去做,但是为什么这样做,我是不清楚的,这也导致我自己都不知道当初的训练
模型的流程是否正确,现在好了,前段时间把yolov3,ssd学习了,现在来操作,就知道这样操作的原理了,整个操作流程就知道的很详细了,也知道怎么训练自己的数据了,不再茫
然。
环境说明:yolo系列一直都有linux版本和windows版本,我看了哈,很明显linux版本更加简单,windows版本还需要搭配vs来操作,光vs这个软件就十几个g,太大了,所以我就采取在
ubuntu上训练数据了。
首先,要感谢下面的这篇文章的作者:https://www.cnblogs.com/Assist/p/11091501.html,这篇文章为我梳理了整个思路,这也为我想处理自己的数据,训练自己的模型有了想法。
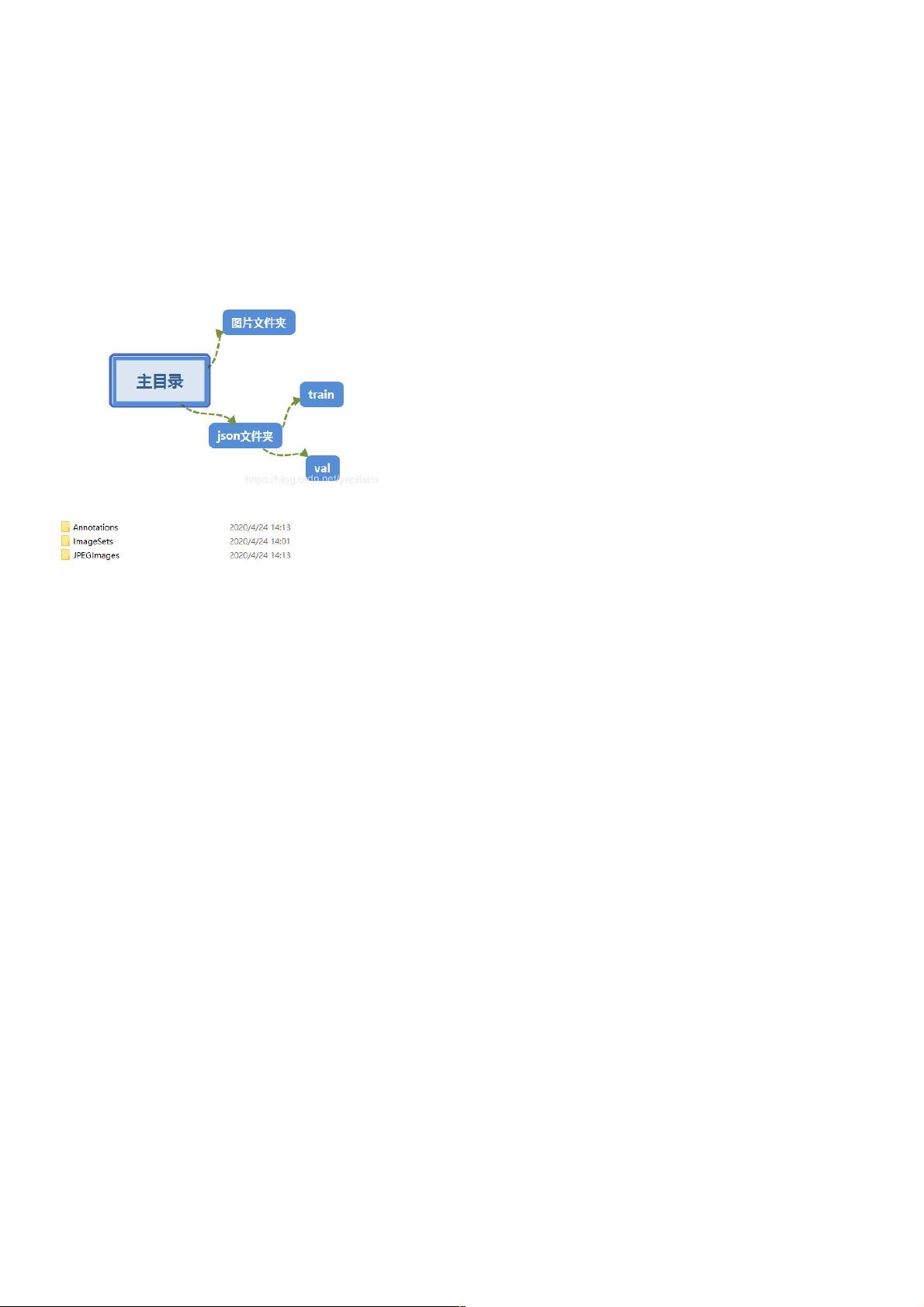
一般来说,训练coco, vol这些数据集,网上很多教程来进行数据的预处理,但是训练自己的数据,就得自己根据网上的教程来改代码了,因为coco这些数据集的标注文件和图片存储
结果可能跟自己的数据都不一样,对于我用labelme来标注的图像来说,每一张图片会对应一个json文件,这个json文件里面拥有这标注的类别坐标这些信息,所以,我这里值将所有
图片放到一个文件夹,所有json文件放到一个文件夹,但是为了区分训练数据和val数据,我将json进行了划分,一部分放到了train文件夹,一部分放到了val文件夹,最后整个文件的
结构如下:
接下来咱就可以开始正式的数据预处理了,这一块是最麻烦的,我个人觉得哈。我们运行第一个Py文件后,
要创建出下面这几个文件夹:
第一个文件夹用来装xml文件,这个xml文件里面有标签类别,图片的宽高,标签的左上角和右下角坐标这些信息,每一张照片对应一个xml文件,imagesets这个文件夹里面还有一个
文件夹:/Main, 在这个Main文件夹下面会产生train.txt和val.txt,这些文件里面的信息只是图片的名字,不带.jpg这些后缀的名字,而在JPEGImages里面就是所有图片了。
我们假设这第一个py文件叫convertvoc.py,我下面提供我的代码,大家不能照搬,有些地方要改。
'''author:nike hu'''
# -*- coding: utf-8 -*-
import shutil
import os
import json
import cv2
headstr = """\
VOC2007
%06d.jpg
My Database
PASCAL VOC2007
flickr
NULL
NULL
company
%d
%d
%d
0
"""
objstr = """\
%s
Unspecified
0
0
%d
%d
%d
%d
"""
tailstr = '''\
'''
# 上面的不用改
def writexml(idx, head, bbxes, tail):
filename = ("Annotations/%06d.xml" % (idx))
f = open(filename, "w")
f.write(head)
for bbx in bbxes:
f.write(objstr % (bbx[0], bbx[1], bbx[2], bbx[3], bbx[4]))
# 这里就是将文件中标签类别,左上角和右下角坐标存进去
下载后可阅读完整内容,剩余3页未读,立即下载
2020-04-29 上传
2020-06-23 上传
2020-05-15 上传
2020-10-19 上传
2024-04-10 上传
2024-05-04 上传
2023-05-15 上传
2024-09-27 上传
2023-08-12 上传

weixin_38626192
- 粉丝: 4
- 资源: 932
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
