CogVLM:视觉语言大模型的开源突破与深度融合
需积分: 0 180 浏览量
更新于2024-06-19
收藏 8.92MB PDF 举报
本文档深入解读了名为"CogVLM: Visual Expert for Large Language Models"的预印本论文。CogVLM是一种强大的开源视觉语言基础模型,它在处理跨模态任务时展现出了显著的优势。与传统的浅层映射方法不同,这种方法并不将图像特征直接映射到语言模型的输入空间,而是通过一个可训练的视觉专家模块,该模块被嵌入到注意力和全连接层中,实现了语言模型与图像编码器之间的深度融合。
这个设计的关键在于,CogVLM能够桥接预先训练好的语言模型与图像编码器之间的鸿沟,使得两者能够高效地交互和共享信息,而无需牺牲自然语言处理(NLP)任务的性能。这在实践中意味着模型能够更好地理解和结合文本与视觉输入,从而在诸如NoCaps、Flicker30k captioning、RefCOCO、RefCOCO+、RefCOCOg、Visual7W、GQA、ScienceQA、VizWiz VQA和TDIUC等经典的跨模态基准测试上取得了最先进的表现。
例如,CogVLM-17B版本在VQA 2.0、OKVQA、TextVQA以及COCO captioning等评测中排名第二,证明了其在理解和生成高质量多模态响应方面的实力,超越了现有的许多竞争对手。此外,作者们强调,这种设计不仅提升了模型在跨模态理解上的性能,而且为未来的研究者和开发者提供了一个强大的工具,便于他们在自己的项目中利用视觉和语言信息进行创新。
这篇论文的核心贡献在于提出了一种新型的跨模态模型架构,通过可训练的视觉专家模块,促进了视觉和语言特征的深度融合,这在当前的自然语言处理和计算机视觉领域具有重要的实践价值和理论意义。对于希望深入研究或应用跨模态技术的读者来说,这份翻译笔记提供了快速理解和对比原文的宝贵资源。
Preprint
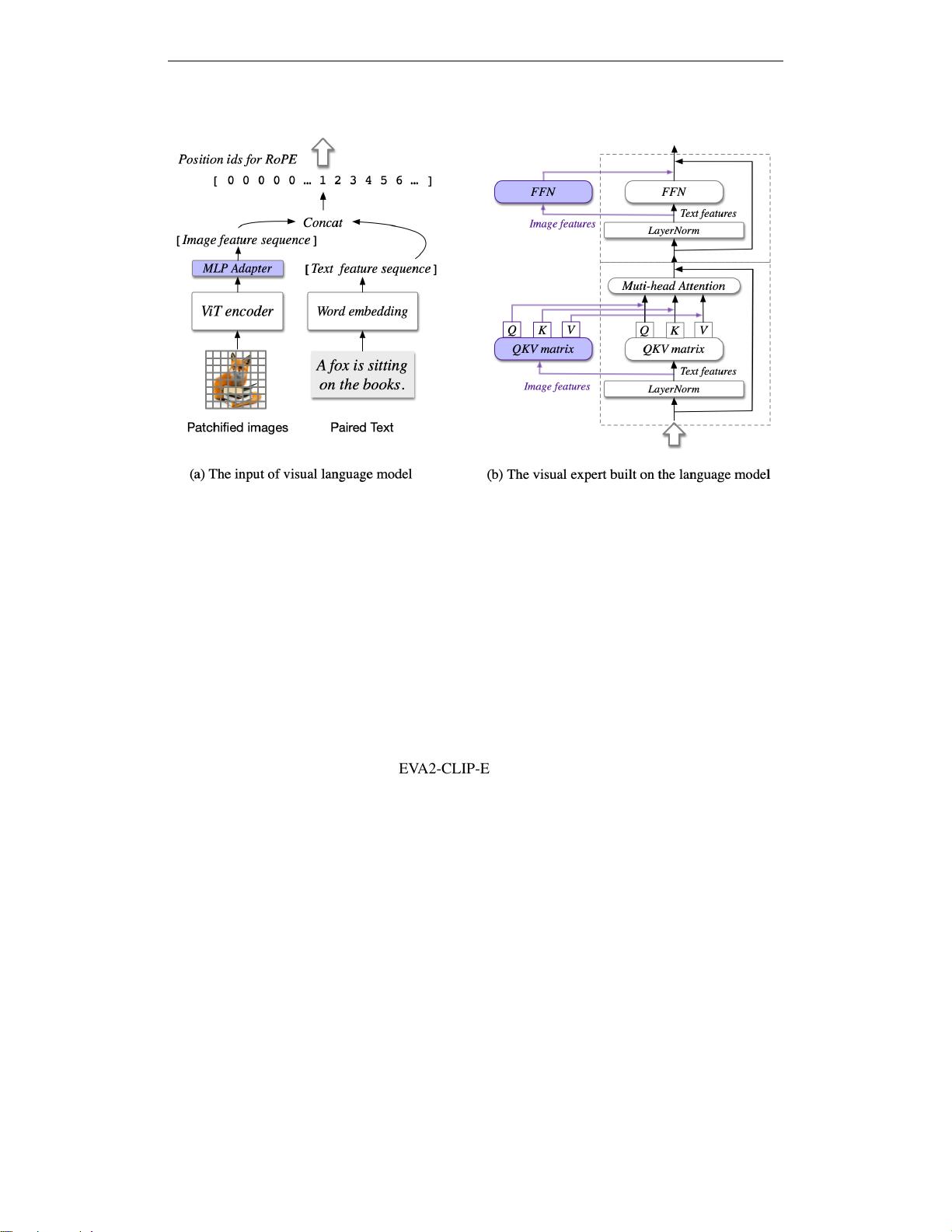
Figure 3: The architecture of CogVLM. (a) The illustration about the input, where an image is processed by a
pretrained ViT and mapped into the same space as the text features. (b) The Transformer block in the language
model. The image features have a different QKV matrix and FFN. Only the purple parts are trainable.
2 METHOD
2.1 ARCHITECTURE
CogVLM model comprises four fundamental components: a vision transformer (ViT) encoder, an
MLP adapter, a pretrained large language model (GPT), and a visual expert module. Figure 3 shows
an overview of the CogVLM architecture. The components’ design and implementation details are
provided below:
ViT encoder. We utilize pretrained EVA2-CLIP-E (Sun et al., 2023) in CogVLM-17B. The final
layer of ViT encoder is removed because it specializes in aggregating the [CLS] features for con-
trastive learning.
MLP adapter. The MLP adapter is a two-layer MLP (SwiGLU (Shazeer, 2020)) to map the output
of ViT into the same space as the text features from word embedding. All image features share the
same position id in the language model.
Pretrained large language model. CogVLM’s model design is compatible with any off-the-
shelf GPT-style pretrained large language model. Specifically, CogVLM-17B adopts Vicuna-7B-
v1.5 (Chiang et al., 2023) for further training. A causal mask is applied to all the attention opera-
tions, including the attention between image features.
Visual expert module. We add a visual expert module to each layer to enable deep visual-language
feature alignment. Specifically, the visual expert module in each layer consists of a QKV matrix
and an MLP in each layer. The shapes of the QKV matrix and MLP are identical to those in the
pretrained language model and initialized from them. The motivation is that each attention head
in the language model captures a certain aspect of semantic information, while a trainable visual
expert can transform the image features to align with the different heads, therefore enabling deep
fusion.
Formally, suppose that the input hidden states of an attention layer are X ∈ R
B×H×(L
I
+L
T
)×D
,
where B is the batch size, L
I
and L
T
are the lengths of image and text sequences, H is the number
of attention heads, and D is the hidden size. In the attention with visual expert, X is first split as
4
CogVLM模型有四个部分组成,其一视觉编码VIT,其二MLP adapter,其三一个预训练大语言模型GPT,其四视觉专家模块。图3显示了模型架构,设计与现象细节如下:
VIT 我们利用预训练的EVA2-CLIP-E在CogVLM-17B。VIT encoder最后一层被移除,因为CLS特征在对比学习中是专门回归。
MLP adapter来自SwiGLU论文是一个2层的MLP结构,目的是将VIT输出格式对齐嵌入文本空间。
在大语言模型中所有图像特征共享相同位置。
我们在语言模型每一层增加一个视觉专家模块,促使视觉语言特征深度校准。视觉专家模块由QKV矩阵+MLP构成,且模块可根据选择语言模型构建
QKV矩阵与mlp,也会初始化。从而语言模型每个注意力头将捕获各自语义信息,同时可训练专家模块能转换视觉特征与不同头进行校准,因此实现
深度融合。
剩余17页未读,继续阅读

tangjunjun-owen
- 粉丝: 2w+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java图片爬虫程序深入解析:连接数据库实现高效下载
- Panasonic SDFormatter:专业SD卡格式化解决方案
- 官方发布:单片机下载器驱动程序安装与使用指南
- 深入理解Cloud Post - 构建Node.js应用与安全实践
- Android网络检测技术示例:检测不可用WiFi连接
- MSP430F149烧录软件使用与USB-BSL驱动下载指南
- 揭秘网站安全编程:防止xss漏洞的实战技巧
- Java推箱子游戏开发教程及实践
- 使用PHP将Markdown转换为HTML的简易教程
- J2ME推箱子游戏开发:课程设计与移动运行指南
- 邮政编码识别:利用OPENCV技术进行倾斜矫正与字符分隔
- 揭秘无刷电机霍尔传感器与绕组位置对应关系
- OMics患者报告生成与R软件包安装指南
- 使用xmlbeans-2.4.0快速生成JAVA代码的方法
- suit.less:简化 LESS 编写,兼容 Suitcss 样式
- C#连接Access创建密码管理器简易操作指南
