NIMA:基于深度学习的图像质量评估与单图无参考优化
需积分: 11 145 浏览量
更新于2024-09-06
收藏 10.09MB PDF 举报
NIMA Neural Image Assessment (NIMA) 是一篇发表于 2018 年 IEEE Transactions on Image Processing (TIP) 的论文,该研究将自动学习的图像质量评估推向了新的高度。随着图像在摄影、存储和分享等领域的广泛应用,传统的主观性问题——如何准确反映人类对图像质量的感知——变得越来越重要。然而,大多数现有的方法仅限于预测像AVA和TID2013这样的数据集提供的平均意见分数,这未能充分捕捉到主观性和多样性。
NIMA 的创新之处在于,它利用深度学习技术,特别是卷积神经网络(CNN),来预测人类对图像质量的主观意见分布。这种方法突破了单一点预测的局限,能够提供更丰富的评估信息。通过借鉴和改进先进的深度对象识别网络的成功经验,NIMA 设计出了一种性能卓越且结构相对简单的架构。这使得该模型不仅能够可靠地评价图像质量,并与人类感知高度相关,而且还能用于指导和优化照片编辑/增强算法,从而提升摄影流程的整体效果。
与传统方法不同,NIMA 不依赖于所谓的“黄金”参考图像进行评估,实现了无参考、语义感知和感知敏锐的质量评估。这意味着即使在没有标准对比的情况下,也能对图像质量做出客观的判断。这对于实时应用和大规模数据处理具有显著优势,因为无需为每一张图片都准备一个参考样本。
NIMA 研究在图像质量评估领域引入了新颖的深度学习方法,提升了评估的准确性和灵活性,对于推动该领域的发展和技术进步具有重要意义。未来的研究可能进一步探索如何将NIMA 结合到更广泛的图像处理任务中,如图像修复、风格转换或自动化摄影指导系统。
3
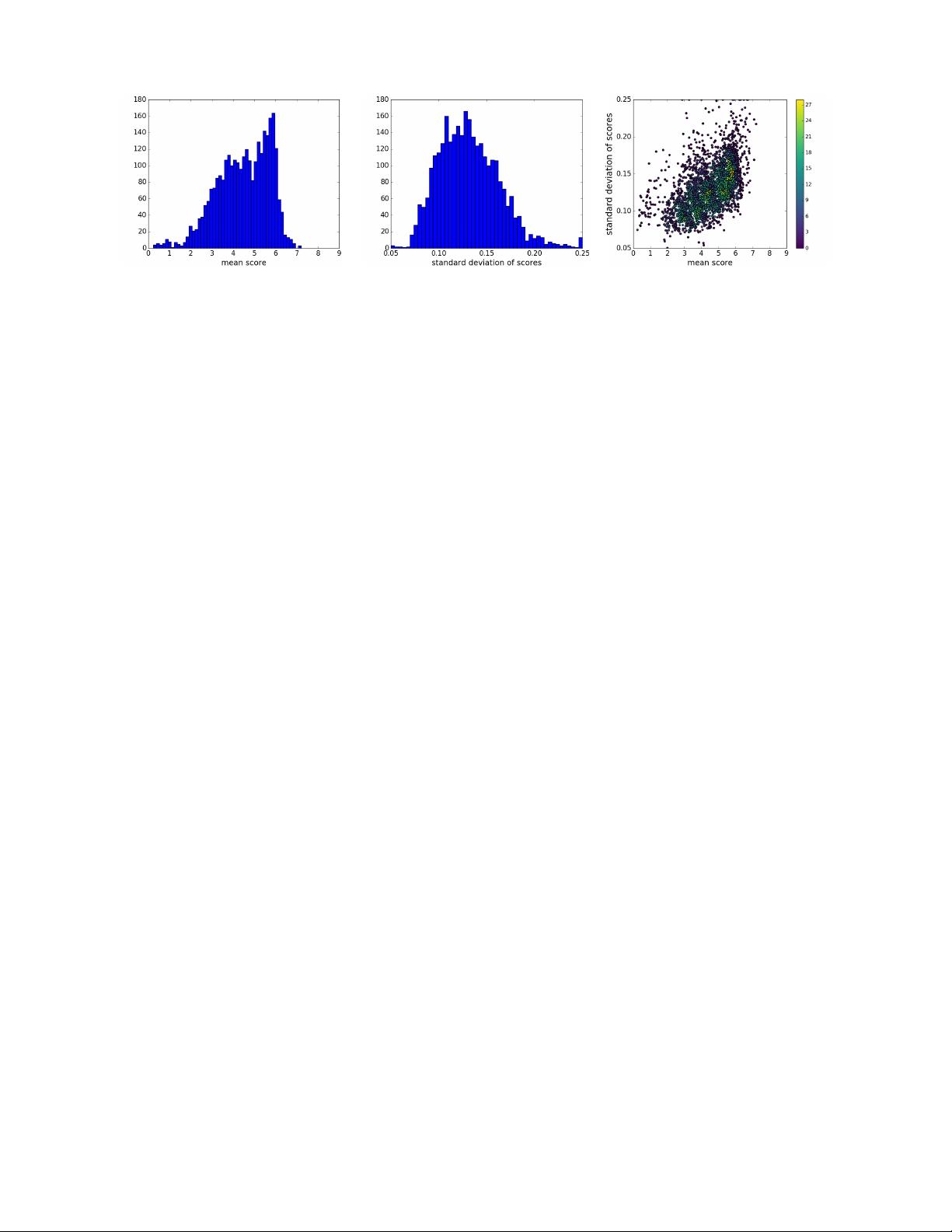
Fig. 3: Histograms of ratings from TID2013 dataset [2]. Left: Histogram of mean scores. Middle: Histogram of standard
deviations. Right: Joint histogram of the mean and standard deviation.
D. Tampere Image Database 2013 (TID2013) [2]
TID2013 is curated for evaluation of full-reference percep-
tual image quality. It contains 3000 images, from 25 reference
(clean) images (Kodak images [20]), 24 types of distortions
with 5 levels for each distortion. This leads to 120 distorted
images for each reference image; including different types of
distortions such as compression artifacts, noise, blur and color
artifacts.
Human ratings of TID2013 images are collected through
a forced choice experiment, where observers select a better
image between two distorted choices. Set up of the experiment
allows raters to view the reference image while making a
decision. In each experiment, every distorted image is used
in 9 random pairwise comparisons. The selected image gets
one point, and other image gets zero points. At the end of
the experiment, sum of the points is used as the quality score
associated with an image (this leads to scores ranging from 0 to
9). To obtain the overall mean scores, total of 985 experiments
are carried out.
Mean and standard deviation of TID2013 ratings are shown
in Fig. 3. As can be seen in Fig. 3(c), the mean and score
deviation values are weakly correlated. A few images from
TID2013 are illustrated in Fig. 4 and Fig. 5. All five levels
of JPEG compression artifacts and the respective ratings are
illustrated in Fig. 4. Evidently higher distortion level leads to
lower mean score
2
. Effect of contrast compression/stretching
distortion on the human ratings is demonstrated in Fig. 5.
Interestingly, stretch of contrast (Fig. 5(c) and Fig. 5(e)) leads
to relatively higher perceptual quality.
Unlike AVA, which includes distribution of ratings for each
image, TID2013 only provides mean and standard deviation
of the opinion scores. Since our proposed method requires
training on score probabilities, the score distributions are
approximated through maximum entropy optimization [21].
II. PROPOSED METHOD
Our proposed quality and aesthetic predictor stands on
image classifier architectures. More explicitly, we explore a
few different classifier architectures such as VGG16 [17],
Inception-v2 [22], and MobileNet [23] for image quality
2
This is a quite consistent trend for most of the other distortions too
(namely noise, blur and color distortions). However, in case of the contrast
change (Fig. 5), this trend is not obvious. This is due to the order of contrast
compression/stretching from level 1 to level 5)
assessment task. VGG16 consists of 13 convolutional and 3
fully-connected layers. Small convolution filters of size 3 × 3
are used in the deep VGG16 architecture [17]. Inception-
v2 [22] is based on Inception module [24] which allows for
parallel use of convolution and pooling operations. Also, in
the Inception architecture, traditional fully-connected layers
are replaced by average pooling, which leads to a signifi-
cant reduction in number of parameters. MobileNet [23] is
an efficient deep CNN, mainly designed for mobile vision
applications. In this architecture, dense convolutional filters are
replaced by separable depth filters. This simplification results
in smaller and faster CNN models.
We replaced the last layer of the baseline CNN with a
fully-connected layer with 10 neurons followed by soft-max
activations (shown in Fig. 6). Baseline CNN weights are
initialized by training on the ImageNet dataset [15], and then
an end-to-end training on quality assessment is performed. In
this paper, we discuss performance of the proposed model with
various baseline CNNs.
In training, input images are rescaled to 256 × 256, and
then a crop of size 224 × 224 crop is randomly extracted.
This lessens potential over-fitting issues, especially when
training on relatively small datasets (e.g. TID2013). It is worth
noting that we also tried training with random crops without
rescaling. However, results were not compelling. This is due to
the inevitable change in image composition. Another random
data augmentation in our training process is horizontal flipping
of the image crops.
Our goal is to predict the distribution of ratings for a
given image. Ground truth distribution of human ratings of
a given image can be expressed as an empirical probability
mass function p = [p
s
1
, . . . , p
s
N
] with s
1
≤ s
i
≤ s
N
,
where s
i
denotes the ith score bucket, and N denotes the
total number of score buckets. In both AVA and TID2013
datasets N = 10, in AVA, s
1
= 1 and s
N
= 10, and in TID
s
1
= 0 and s
N
= 9. Since
P
N
i=1
p
s
i
= 1, p
s
i
represents the
probability of a quality score falling in the ith bucket. Given
the distribution of ratings as p, mean quality score is defined
as µ =
P
N
i=1
s
i
× p
s
i
, and standard deviation of the score is
computed as σ = (
P
N
i=1
(s
i
− µ)
2
× p
s
i
)
1/2
. As discussed in
the previous section, one can qualitatively compare images by
mean and standard deviation of scores.
Each example in the dataset consists of an image and its
ground truth (user) ratings p. Our objective is to find the
剩余12页未读,继续阅读
2021-05-18 上传
2021-05-22 上传
2023-04-08 上传
2021-02-04 上传
2021-05-04 上传
2021-05-28 上传
2021-02-05 上传
2021-09-27 上传

K5niper
- 粉丝: 93
- 资源: 10
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索AVL树算法:以Faculdade Senac Porto Alegre实践为例
- 小学语文教学新工具:创新黑板设计解析
- Minecraft服务器管理新插件ServerForms发布
- MATLAB基因网络模型代码实现及开源分享
- 全方位技术项目源码合集:***报名系统
- Phalcon框架实战案例分析
- MATLAB与Python结合实现短期电力负荷预测的DAT300项目解析
- 市场营销教学专用查询装置设计方案
- 随身WiFi高通210 MS8909设备的Root引导文件破解攻略
- 实现服务器端级联:modella与leveldb适配器的应用
- Oracle Linux安装必备依赖包清单与步骤
- Shyer项目:寻找喜欢的聊天伙伴
- MEAN堆栈入门项目: postings-app
- 在线WPS办公功能全接触及应用示例
- 新型带储订盒订书机设计文档
- VB多媒体教学演示系统源代码及技术项目资源大全
