Spark Streaming深度解析:原理与实战技巧
"Spark Streaming是Apache Spark的一部分,用于实时数据流处理。它通过将流处理任务分解为一系列小批量的批处理作业,利用Spark的快速并行计算能力,提供了高容错性和可扩展性。Spark Streaming支持多种数据源,如Kafka、Flume、Twitter、ZeroMQ等,并提供丰富的转换操作,包括无状态和有状态的转换,以及窗口操作。数据输出可以通过打印、持久化到文件系统或Hadoop等。此外,为了确保容错性,Spark Streaming还支持检查点功能。"
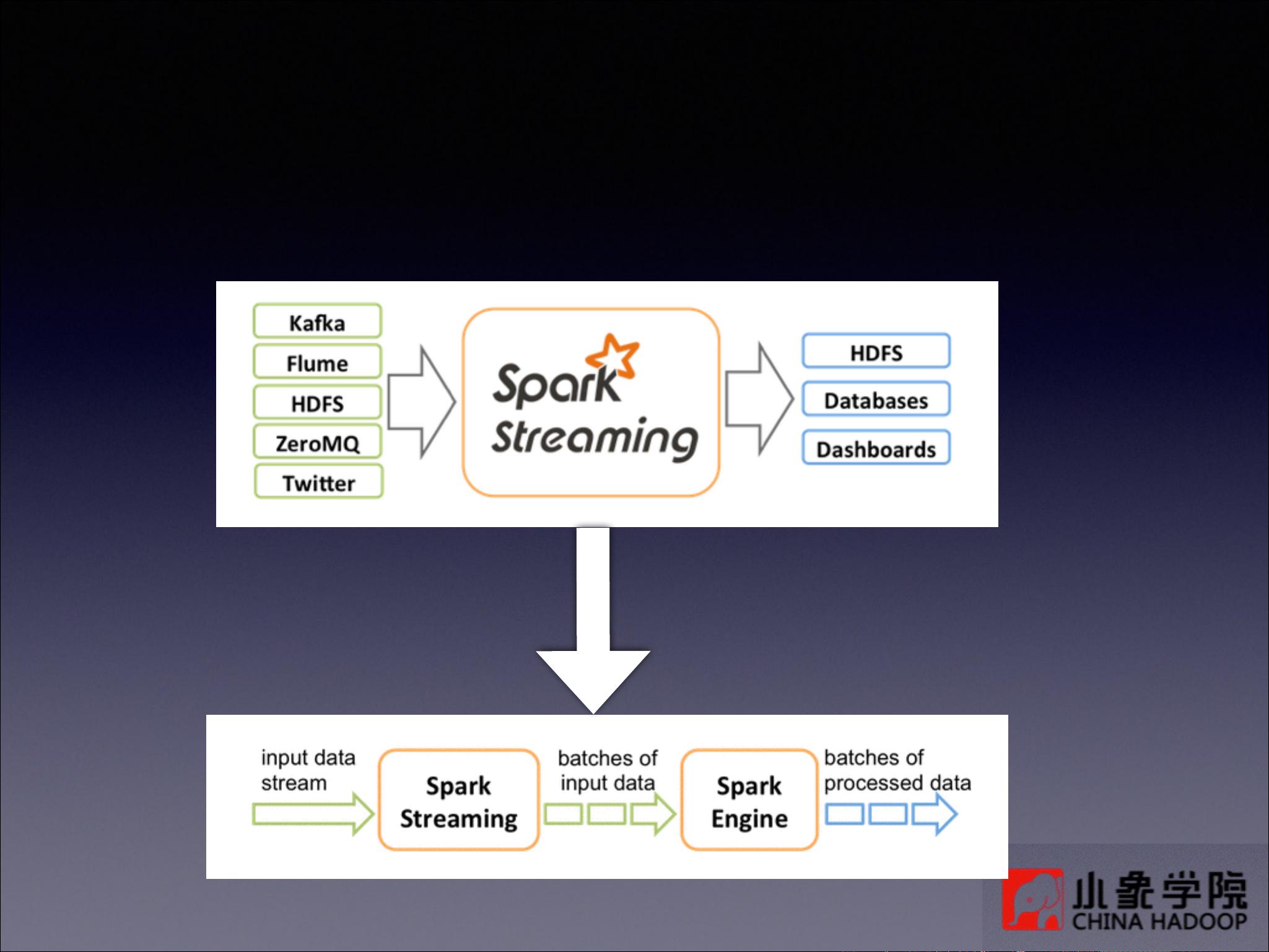
Spark Streaming是一个分布式、容错的流处理框架,它基于Apache Spark的核心功能构建,旨在处理连续的数据流。Spark Streaming的核心概念是Discretized Stream (DStream),这是一种表示连续数据流的抽象,由一系列连续的RDD(弹性分布式数据集)组成。RDD是Spark的基础数据结构,它表示不可变、分区的数据集合。
DStream的创建可以来源于各种输入源,例如Kafka主题、Flume事件、Twitter流、ZeroMQ消息队列、TCP套接字、Akka actors甚至是HDFS文件。一旦创建了DStream,用户可以对其进行转换操作,这些操作与Spark批处理API中的操作相似,包括无状态转换(如map、flatMap、filter、count、reduce)和有状态转换(如groupByKey、reduceByKey、updateStateByKey、window操作等)。有状态转换允许处理历史数据,比如updateStateByKey用于更新每个键的状态,而window操作则用于在时间窗口内聚合数据。
数据处理完成后,结果可以输出到不同的目标,如打印到控制台、保存为文本文件、对象文件,或者写入Hadoop文件系统。为了提高容错性,Spark Streaming支持数据持久化,即使在处理过程中出现故障,也可以从已持久化的状态恢复。默认情况下,来自网络的数据源会以序列化形式在内存中存储两份,以保证可用性。
对于那些需要长期保存状态的窗口和有状态操作,Spark Streaming引入了检查点机制。通过调用StreamingContext的checkpoint方法指定一个检查点目录,可以定期保存中间状态,以便在系统崩溃后能够恢复。这有助于实现容错,但同时也带来了额外的存储需求。
Spark Streaming提供了一种高效、灵活且容错的实时数据处理方式,它结合了批处理的易用性和流处理的实时性,使得开发人员能够轻松处理大规模的实时数据流。通过理解Spark Streaming的基本原理、DStream的概念以及转换和输出操作,开发者可以构建出强大的实时分析应用。
Overview
!6
剩余28页未读,继续阅读
2018-02-02 上传
2021-05-02 上传
2023-03-16 上传
2023-05-09 上传
2023-05-14 上传
2023-03-16 上传
2023-05-10 上传
2023-03-16 上传

shaguayidianhong
- 粉丝: 3
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
