Solr全文检索与反向索引解析
"Solr概念介绍,包括反向索引、查询和Solr全文检索基本原理。"
Solr是一个强大的开源企业级搜索平台,由Apache软件基金会维护,它提供了高效的全文索引和搜索功能。Solr利用反向索引这一核心技术,以实现快速准确的搜索。反向索引是一种优化的索引结构,它不同于传统的顺序索引,后者是通过记录的顺序查找属性值,而反向索引则是根据属性值(在这里指的是文本中的词汇)来定位记录的位置。
在传统顺序索引中,查找特定词汇可能需要遍历整个数据集,效率低下。而在反向索引中,每个词汇都会关联一个列表,这个列表包含了所有包含该词汇的文档ID。例如,在员工手册的例子中,如果我们要找包含“坑娘”的页面,只需查找反向索引中“坑娘”对应的文档列表,就能快速定位到正确位置,大大提高了搜索速度。
建立反向索引的过程涉及到分词,这是构建索引的关键步骤。分词是指将连续的文本分解成单独的词汇单元,不同的分词技术会产生不同的词汇列表,从而影响搜索结果的准确性。例如,对于句子“你们技术部为什么要一直删数据啊?”不同的分词策略可能会得到“你们技术部”、“技术部”、“为什么”等不同结果。
在Solr中,分词组件可以配置各种分词器,如标准分词器(Standard Tokenizer)或中文分词器(Chinese Tokenizer),它们会处理各种语言特性。同时,Solr还支持停词过滤,停词是指在特定语言中频繁出现但对搜索意义不大的词汇,如英语中的“the”和中文中的“的”。去除这些停词可以减少索引大小,提高搜索效率。
除了分词和停词处理,Solr还包含语言处理组件,对分词后的词元进行进一步加工。例如,对于英语,组件通常会将单词转为小写,执行词干提取(stemming)或词形还原(lemmatization),使搜索更具包容性。而对于中文,可能需要处理诸如词语切分、词性标注等任务,以便更准确地理解文本含义。
Solr通过反向索引、分词和语言处理等技术,实现了高效的企业级搜索解决方案。其提供的REST风格的HTTP/XML和JSON API使得集成到各种系统中变得简单,易于扩展,是现代大数据环境下理想的全文检索工具。
solr
Solr 处理之索引组件
索引组件
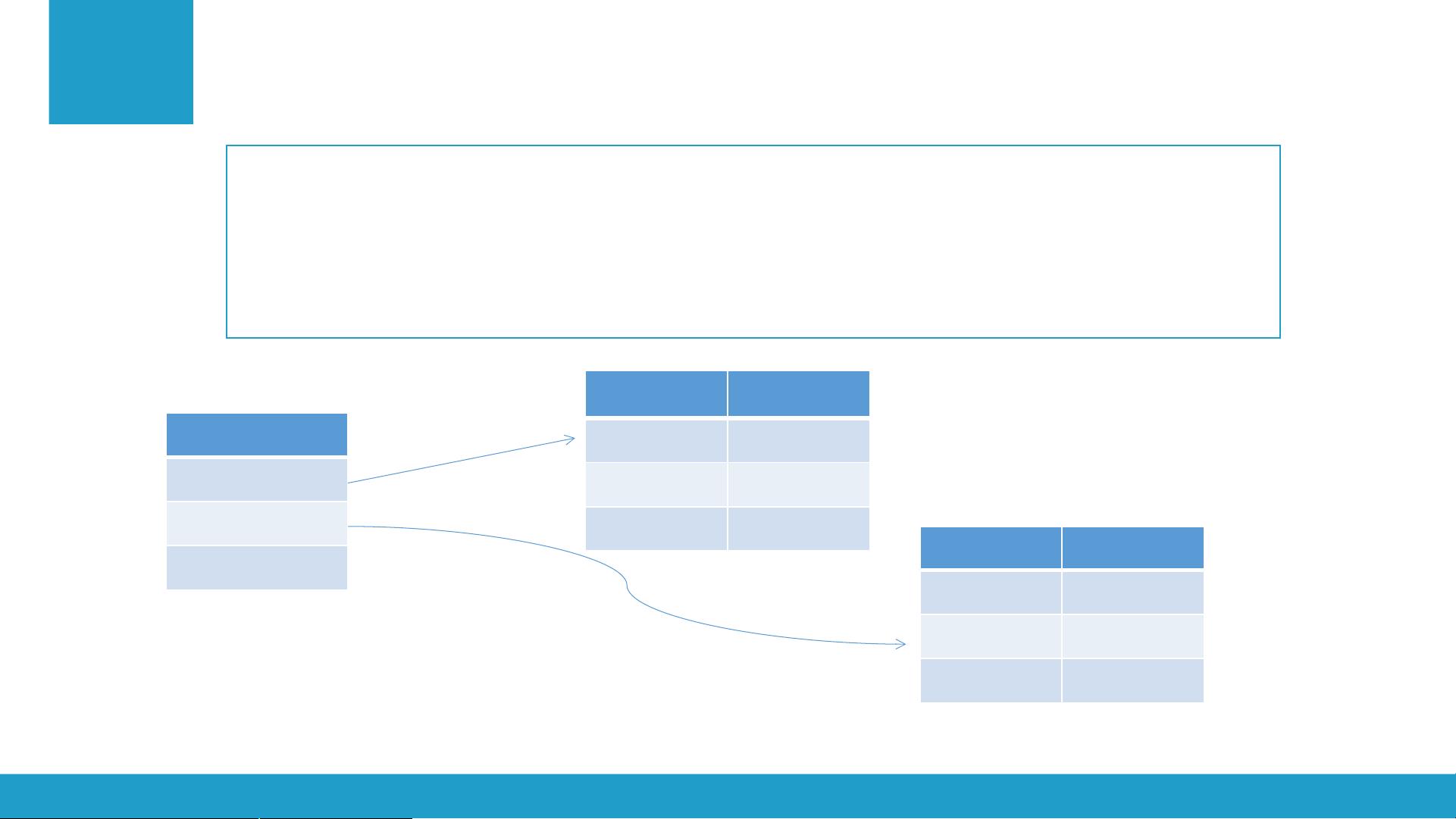
索引组件主要是对语言处理组件后得到的词元,进行合并,建立对
应的文档索引。
文档 ID 词频
1 2
6 8
2 13
词元
沙发
中式
简约
文档 ID 词频
12 3
7 8
6 23


剩余59页未读,继续阅读
2018-03-19 上传
2018-11-30 上传
2018-08-22 上传
点击了解资源详情
2013-08-22 上传
2011-08-05 上传
2021-10-02 上传
2016-08-19 上传

jjtimer
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 行业文档-设计装置-一种利用字型以及排序规则实现语言拼写校正的方法.zip
- jojo_js:前端相关的js库 ,组件,工具等
- auto
- audio-WebAPI:HTML5 音频录制和文件创建
- Text-editor:使用nodejs和html制作的多人文字编辑器
- kcompletion:K完成
- 课程设计--Python通讯录管理系统.zip
- 基于机器学习的卷积神经网络实现数据分类及回归问题.zip
- node_mailsender:使用docker的简单node.js邮件发件人脚本
- my-website
- angular-gulp-seed-ie8:使用 Gulp 动态加载 IE8 polyfills 的 Angular 基础项目
- ATMOS:ATMOS代码
- 基于webpack的vue单页面构建工具.zip
- Suitor_python_flask:Reddit feed命令行客户端界面和Web界面工具
- 行业文档-设计装置-一种利用秸秆制备瓦楞纸的方法.zip
- .emacs.d:我的个人emacs配置
