




基于无数据知识提取的非IID联邦学习:FedFTG算法
PDF格式 | 866KB |
更新于2025-01-16
| 95 浏览量 | 举报
无数据知识提取的非IID联邦学习
在联邦学习(FL)中,数据异构性是一个主要挑战,因为它导致收敛速度慢和性能下降。大多数实例方法只通过限制客户端局部模型更新来解决异构性问题,而忽略了直接全局模型聚集所带来的性能下降。为了解决这个问题,我们提出了无数据的知识蒸馏方法FedFTG,在服务器端,缓解了直接模型聚集的问题,以微调的聚集模型。FedFTG通过生成器探索局部模型的输入空间,并利用它将局部模型的知识传递到全局模型。此外,我们提出了一个硬样本挖掘方案,以实现整个训练过程中有效的知识提炼。我们的FedFTG显着优于国家的最先进的(SOTA)FL算法,可以作为一个强大的插件,用于增强FedAvg,FedProx,FedDyn和SCAFFOLD。
一、联邦学习概述
联邦学习(FL)是一种新兴的隐私约束下的分布式学习模式。FL的主要挑战之一是数据异质性,即客户端中的数据是不相同且独立分布的(非IID)。已经证实,香草FL算法FedAvg导致漂移的局部模型,并且在这种情况下灾难性地忘记全局知识,这进一步导致性能下降和收敛缓慢。
二、无数据知识提取方法FedFTG
FedFTG是一种无数据的知识蒸馏方法,在服务器端,缓解了直接模型聚集的问题,以微调的聚集模型。FedFTG通过生成器探索局部模型的输入空间,并利用它将局部模型的知识传递到全局模型。FedFTG可以缓解模型聚集后的性能下降问题,提高FL的性能。
三、硬样本挖掘方案
我们提出了一个硬样本挖掘方案,以实现整个训练过程中有效的知识提炼。该方案可以帮助FL模型更好地学习客户端的数据特征,提高FL的性能。
四、实验结果
大量的实验表明,FedFTG显着优于国家的最先进的(SOTA)FL算法,可以作为一个强大的插件,用于增强FedAvg,FedProx,FedDyn和SCAFFOLD。
五、结论
无数据知识提取的非IID联邦学习可以缓解FL中的数据异构性问题,提高FL的性能。我们的FedFTG方法可以作为一个强大的插件,用于增强FL算法,提高FL的性能和收敛速度。
10176
←
{D}
∈
← ⌈
·
⌉
关于
我们
Σ
--
ω
K
K
K
N
K
t
t
K
--
k=1
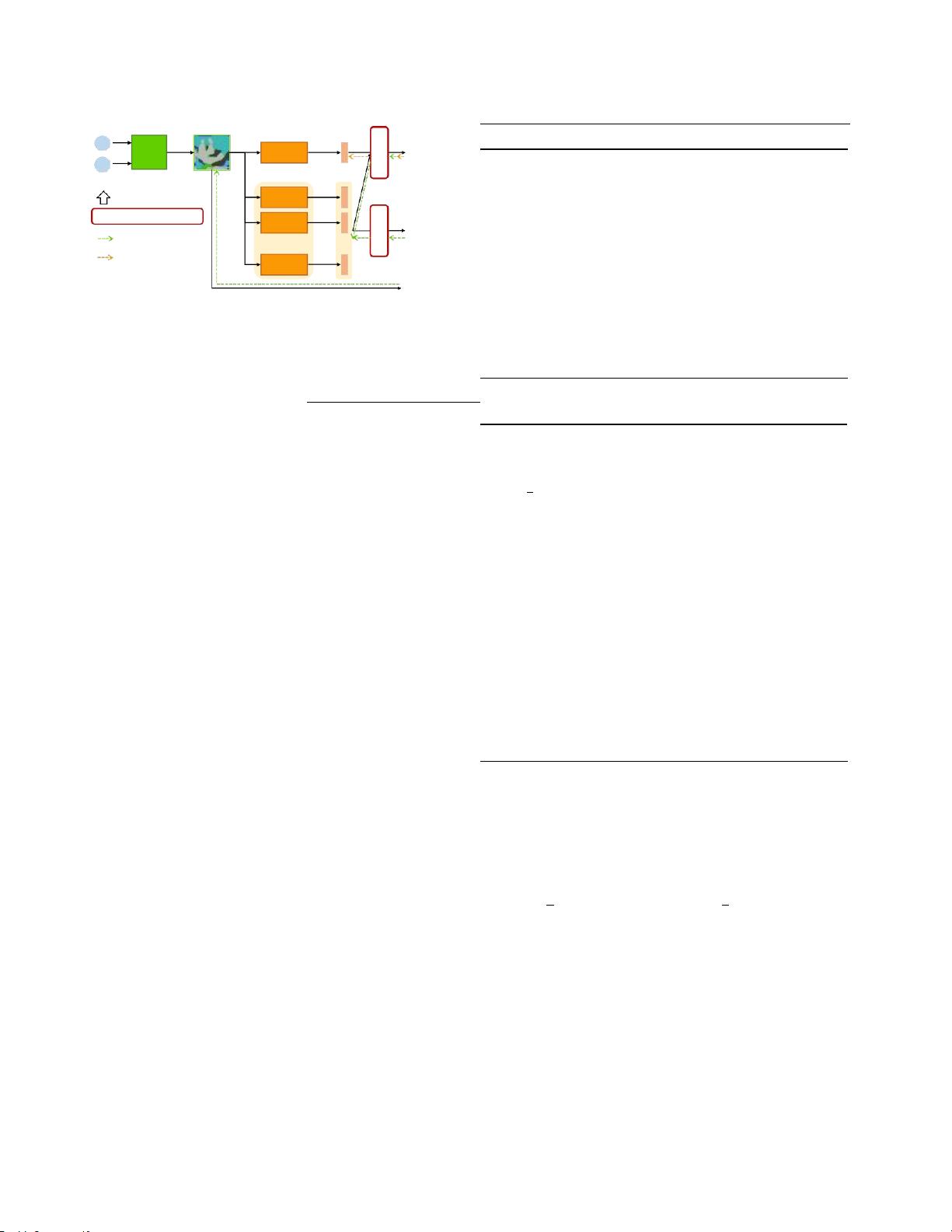
图2.服务器中FedFTG的培训程序。FedFTG在第t轮接收局部
模型并进行聚合后,逆向生成硬样本,通过
Lmd
向聚合后的
全局模型传递知识。L
cls
和L
dis
是uti-
算法1FedFTG
输入:T:沟通回合
;
K:客户编号
;
C:每轮中的代理客户
的
分数
;
k
∈
{
1
,
.
,
K
}
:
客户端
的
数据集
;
ω
:分类器的
参数
;
θ:生成器的参数。
1:
初始化模型参数
ω
和
θ
2
:对于
t= 1,
...
,
没
做
3
:
S
t
(
C
的随机集 K客户端)
;
4
: 对于k S
t
并行,
5: ω
k
ClientUpdate(ω,D
k
)
安装
FedAvg
、
FedProx
、
FedDyn
和
SCAFFOLD
6:结束
7
: ω,θ
ServerUpdate
(ω,θ,ω
kk
∈
S
t
)
8:
结束
用于提高硬样本的保真度和多样性。 此外,我们认为,
FedFTG
使用定制标签采样和类级集成
最大限度地利用知识。
教师模型中的知识。
FedGen还[43]学习了一个轻量级的生成器,
算法2服务器更新,轮t
输入:I:服务器中训练过程的迭代
;
I
g
,I
d
:训练生成器和
全局模型的内迭代
;
η
g
:全局步长
;
ω,θ,{ω
k
}
k
∈
St
,
λ
cls
,
λ
r
.
以无数据的方式收集本地模型的知识-
1
:ω
=
1
|
S
t
|
k
∈
S
t
(
ω
k
−
ω
),
ω
←
ω
+
η
g
<
$ω
ner,但使用发电机来规范本地训练。此外,我们还设
计了硬样本挖掘方案、自定义标签抽样和类级集成,
有效地将数据异构场景下的知识从局部模型转移到全
局模型。
3.
方法
在本节中,我们将描述所提出的新联邦学习方法:
FedFTG在每一轮通信中,FedFTG随机选择一组客户
端,并向它们广播全局模型。每个客户端使用全局模
型对本地模型进行优化,并使用本地优化器对其进行
训练服务器收集本地模型并聚合
第二章: 根据等式计算p
t
(y)。(九)
3:
对于
i
= 1
,
...
, 我
4
:
(
Z
,
Y
)←(采样一批
z
<$N(
0
,
1
)和
y<$p
t
(
y
))
5: 计算 α
k
,
yk
∈
S
,
y
∈
Y
,
根据等式(十)
6
: 对于
j = 1
,
…
,我
愿意
7:
根据等式更新发生器
θ
(
8
)基于当前全局
模型
ω
8:
结束
9
:
对于
j
= 1
,
…
,我
会
的
10:
根据等式
11
更新全局模型
ω
。(
8
)将知识
从ω
kk
∈
S
t
转移
到ω k k ∈ St
11:结束
12:
结束
13:返回ω,θ
这是一个初步的全球模型。而不是广播
D
k
=
{
(x
k
,
i
,
y
k
,
i
)
}
数据集是否单独存储
聚合模型直接返回到每个客户端,FedFTG使用
在第k个客户
端中,N
i
=1
k
是相应的样本数。
从本地模型中提取的知识具体地说,我们提出了一种
无数据的知识提取方法,
一般来说,联邦学习可以用公式表示,
如以下问题:
样本挖掘,以有效地探索和转移知识
-
K
N
k
min
1
<$
f
(
ω
),
f
(
ω
)
=
1
<$
L(
x
i
,
y
i
;
ω
),
(
1
)
类级集成,以促进更有效地利用知识。图2显示了服务
器上的训练过程,相应的算法总结在算法1和2中。请
注意,FedFTG与优化本地模型训练的工作正交,例如
SCAFFOLD,FedAvg,FedProx和FedDyn。
3.1.基于硬样本挖掘的无数据知识提取全局模型微
调
设ω是服务器和客户端中的模型参数。在这项工作
中,我们考虑存在K
个
客户端,其中
噪声发生器伪数据处理
器
全局模型
预测
标签
评分
局部模型
中国
,
抽样
自
()
向后换刀
向后
转
年
月
恩姆布
恩姆布
…
N
k
边缘到全局模型。考虑到客户端标签分布的变化,我
们提出了定制标签抽样,
k
i
=1
下载后可阅读完整内容,剩余11页未读,立即下载
相关推荐



cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开








最新资源
- JavaScript在农作物管理中的应用分析
- iOS中使用alpha渐变数据提升动画切换平滑性
- 易语言实现的网页自动化填表注册教程
- 掌握MFC图形绘制:直线、椭圆、矩形的实现技巧
- QQ全能绿化工具magic01深度解析
- 小祝工作室截图展示与工作流程验证
- 华为路由器日常维护与监测的实践指南
- Pentaho大数据分析解决方案及代码实践(2013)
- 计算机维护中的实用bat脚本技巧
- SAP ERP教程全集:掌握企业资源规划精髓
- 深入理解HBase表设计与操作技巧
- 探索CAD格式转换器:高效版本互换
- JavaScript API时间表管理指南
- Qt虚拟键盘实现及测试报告
- 掌握SQL Server开发的终极指南
- SVN中文语言包1.5.3版本发布及下载指南






















