FedKC:联邦学习解决多语言自然语言理解的挑战
2 浏览量
更新于2024-06-19
收藏 1021KB PDF 举报
"联邦知识组合模块:解决多语言自然语言理解的联邦学习问题"
联邦学习是一种新兴的机器学习范式,旨在在保护数据隐私的同时,利用分布式数据进行模型训练。在自然语言理解(NLU)领域,多语言数据的处理是一项关键挑战,因为这些数据通常分散在不同的客户端,且具有非独立同分布(Non-IID)特性,尤其是语言分布的不平衡。现有的联邦学习方法主要针对IID数据设计,无法有效地处理多语言环境。
针对这一问题,研究人员提出了FedKC,这是一个联邦学习框架下的知识组合模块,特别为多语言NLU任务设计。FedKC的核心思想是在各客户端之间交换知识,而不是直接共享原始数据,这样可以在保护隐私的同时提升模型的性能。它通过计算基于跨客户端共享知识定义的一致性损失,使不同客户端上的模型能够在相似数据上做出一致的预测,从而促进模型的协同训练。
FedKC的设计考虑了非IID数据的特性,如数据分布的倾斜和语言资源的不均衡。对于只包含单语或双语数据的客户端,FedKC能够帮助它们学习其他语言的信息,以提高对低资源语言的理解能力。此外,FedKC的理论分析显示,它对原始数据具有较强的隐私保护,难以从损坏的数据中恢复原始信息。
实验部分,FedKC在三个公共多语言数据集上进行了验证,涵盖了释义识别、问答匹配和新闻分类等典型NLU任务。结果显示,FedKC在所有数据集上都显著优于传统的基线算法,证明了其在处理多语言联邦NLU任务上的优越性能。
FedKC的创新之处在于它的即插即用性质,可以方便地集成到现有的联邦学习框架中,为解决多语言环境下的隐私保护和高效学习提供了一个有效的解决方案。同时,它对教育和研究的开放许可也促进了学术界的交流与合作,推动了联邦学习和自然语言理解领域的进一步发展。
1841
J
.
()
→
{D
|
}
1
1
n
i
n
i
J
J
其中客户端权重
p
与训练量成正比
i
n
i
,w
i
是
分布式全局模型
上传/分发本地/全局模型
上传本地模型
上传质心和平
均预测
上传
/
分发局部
/
全局质心和平均
预测
全局
权重聚合
分发打包的质心和平
均预测
客户端
1
客户端
2
. . .
客户
i
. . .
客户机
N
•
------
•
------
•
------
•
------
客户端
i
的数据
集
1
•
------
•
------
•
------
•
------
Kmeans
聚类
第
1
第
2
第
3
客户端1
的数据
训练数据
0
1
可感知一致性丢失
任务分类丢失
质心
0
1
1
1
1
平均预测
客户端i
成簇
0
0
0
0
客户端
I
模型
FedKC
:
Federated Knowledge Composition for Multilingual Natural Language Understanding WWW
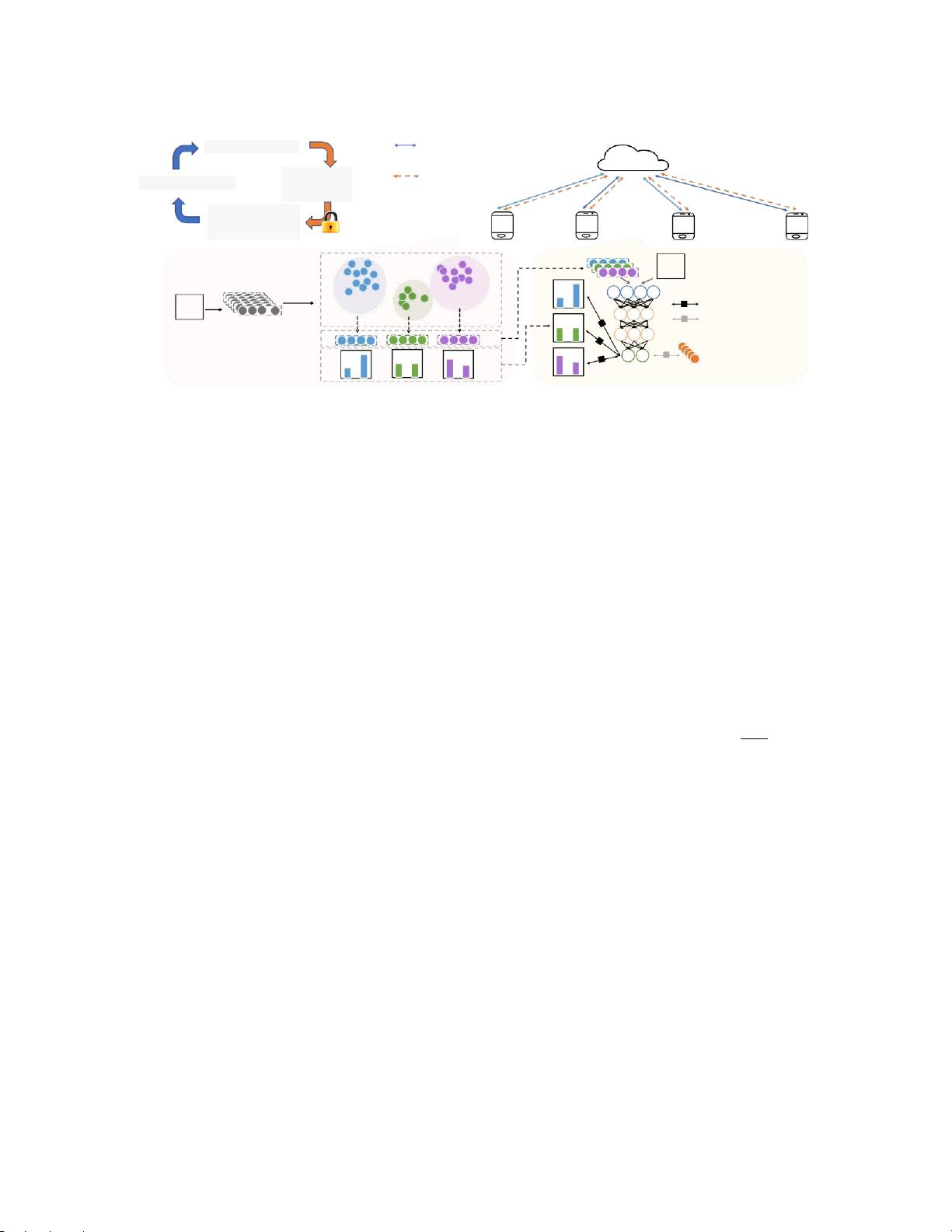
图1:知识构成的框架红色背景部分聚类数据,并计算质心和平均预测。橙色背景部分使用分布式质心和平均预测计算近似一致
性损失。左上角的流程图显示了上传和分发模型和数据的步骤
注意最近。联邦学习旨在学习高质量的
{(s
i
,y
i
),.,(s
i
,y
i
)},其中s
i
是文本内容,y
i
是la-
在多个本地客户端的帮助下实现全局性,同时禁止客户端之间的
数据共享
FedAvg [31]
是最具代表性的联邦学习方法之一它在本
地客户端执行本地随机梯度下降,在服务器端聚集模型然而,
FedAvg
训练有时并不稳定
[27]
。
因此,
FedProx [27]
添加了正则化
器,以防止参数
更新距离上一次通信回合中的参数太远。为了加速
FedAvg
收 敛 , 提 出 了
FedAdagrad [40]
,
FedYogi [40]
和
FedAdam [40]
为了解决客户端本地数据分布的异构性
,有很多
基于
对比学习、数据扩充和知识提取的工作。
MOON[25]
利用对比
学习来迫使参数在上一轮中比上一轮中的局部参数更接近全局参
数。
FedMix [59]
和
XorMixFL [41]
将
Mixup [60]
(一种流行的数
据增强方法)扩展到联邦学习。 然而
,很难应用mixup来实现
良好的性能
bel
,
n
i
是D
i
中训练实例的数量。联邦学习的目标是学习具有分
散 数 据 存 储 的 全 局 模 型 F s
i
y
i
。 在本文中,我们专注于开发多语言
NLU
任务的联邦学习算法,
其中多语言数据集表示为
i
i = 1,2,...,N与k类。
3.2系统
饲料平均值联邦平均[31]是联邦学习的一种流行和经典的算法
。
在给定的通信轮
t
内
,
存在
K
个
活动客户端在本地更新参数。 在联邦
学习中,中央服务器首先将全局模型
参数w
t
分发
给这些活动客户
端,然后活动客户端将
其更新的参数上传到中央服务器。 在中
心服务器
接收到更新的参数之后,中心服务器聚合参数
以通过w
t
+
1
=
i
p
i
w
t +1更新全局模型参数
,
三种基于知识提炼的方法然而,
FedMD
.
n
i
t
+
1
蒸馏,这在许多现实情况下是不可用的。对于
FEDDISTILL
,它
需要学习生成器。该方法虽然
对图像数据有效,但不容易推广
到文本数据,因为文本数据处于离散空间,难以生成。 与这
些
联邦学习方法相比,所提出的
FedKC
不需要保持共享
的辅助数
据集,并且不需要保持最后一轮
的全局或局部模型,而仅交换平
均嵌入。我们
还在表
1
中总结了所提出的
FedKC
和
其他联邦学习方
法之间的差异。
3
背景和序言
3.1 问题公式化
联合学习设置包括中央服务器,
N
个
客户。客户端i上 的数据集表示为D
i
为
在第
t
轮中更新客户端
i
的参数
4 方法
4.1 概述
联邦学习包括两个主要过程,一个是
更新本地客户端的参数,另一
个是聚合全局模型的客户端
参数。最广泛采用的权重聚合操作
[31]
是对每个客户端上的训练数据量进行加权求和,从而容易导致模
型偏向于更强调高资源语言。 为了克服这个问题,我们
提出了一
个知识组合模块,用于
在客户端之间交换知识,以进行联邦学习。
知识合成涉及两个步骤,包括跨客户端的知识共享(在子节
4.2
中)和通过集群感知的一致性损失更新客户端参数(在子节
4.3
中)。我们的
FedKC
框架首先在客户端之间
进行知识共享,然
后更新客户端
文本数据[4]。[24]第二十四话:
存储在一个客户端
i
上
的数据样本,
即,
p
i
=
而
FedED
需要一个额外的共享数据集来执行知识
我
剩余14页未读,继续阅读
2021-01-06 上传
2021-05-17 上传
2023-03-31 上传
2023-06-10 上传
2024-04-08 上传
2023-05-12 上传
2023-03-25 上传
2023-09-08 上传
2023-07-29 上传

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 磁性吸附笔筒设计创新,行业文档精选
- Java Swing实现的俄罗斯方块游戏代码分享
- 骨折生长的二维与三维模型比较分析
- 水彩花卉与羽毛无缝背景矢量素材
- 设计一种高效的袋料分离装置
- 探索4.20图包.zip的奥秘
- RabbitMQ 3.7.x延时消息交换插件安装与操作指南
- 解决NLTK下载停用词失败的问题
- 多系统平台的并行处理技术研究
- Jekyll项目实战:网页设计作业的入门练习
- discord.js v13按钮分页包实现教程与应用
- SpringBoot与Uniapp结合开发短视频APP实战教程
- Tensorflow学习笔记深度解析:人工智能实践指南
- 无服务器部署管理器:防止错误部署AWS帐户
- 医疗图标矢量素材合集:扁平风格16图标(PNG/EPS/PSD)
- 人工智能基础课程汇报PPT模板下载
