分布式数据库:历史、现状与未来趋势
21 浏览量
更新于2024-08-27
收藏 225KB PDF 举报
"本文详细讲述了分布式数据库的起源、发展现状及未来趋势,重点分析了TiDB的架构和进展,并探讨了数据库技术的演变历程。"
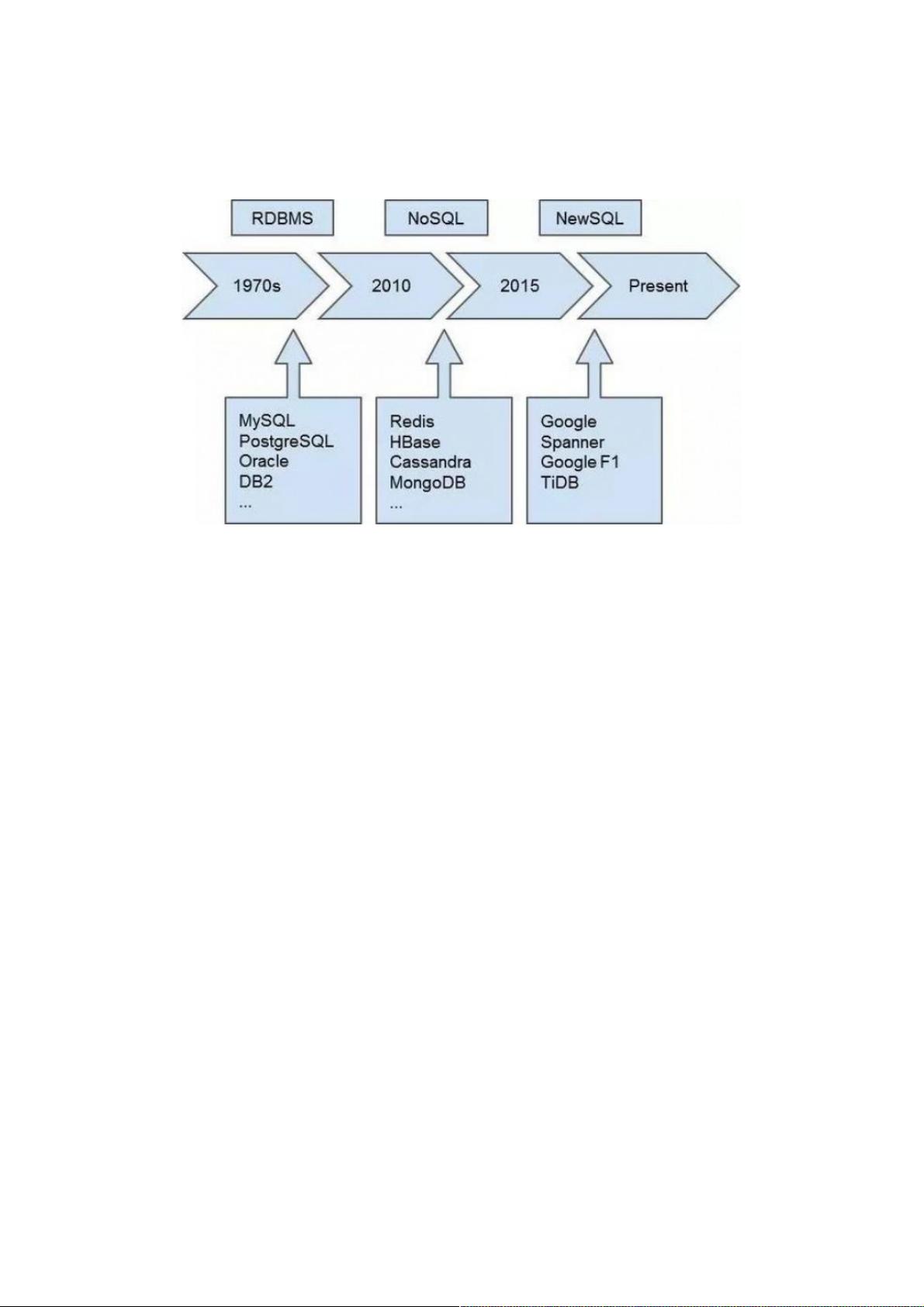
在分布式数据库的历史与现状部分,文章首先介绍了传统单机数据库的发展,关系型数据库自1970年代以来,其核心功能是数据存储和计算需求满足。早期的商业数据库如Oracle和DB2以及后来的开源数据库MySQL和PostgreSQL通过提升性能和利用摩尔定律的进步,成功应对了业务需求。然而,随着互联网尤其是移动互联网的爆发,数据量急剧增加,单机数据库的局限性逐渐显现。
2005年前后,为了解决单机容量限制,NoSQL数据库应运而生,包括HBase、Cassandra和MongoDB等。它们通过牺牲事务支持和简化接口实现了水平扩展,例如HBase是Google BigTable的开源实现,基于Hadoop生态系统,解决了对小对象操作的需求。NoSQL数据库在一定程度上降低了对业务的支撑能力,但为大规模数据处理提供了新的解决方案。
二、TiDB的架构与进展
TiDB(Ti交易型数据库)是一款新型的分布式数据库,它结合了NewSQL数据库的强一致性和NoSQL数据库的水平扩展性。TiDB的设计目标是实现无限水平扩展、强一致性和高可用性。它的架构包括TiKV(分布式键值存储)、PD(Placement Driver,负责集群管理)和TiDB服务器(SQL层)。TiDB通过Raft一致性算法保证数据的强一致性,同时使用分布式事务处理,支持ACID特性。
TiDB的进展包括性能优化、生态完善和更多行业应用场景的探索。例如,它已经应用于金融、零售、电信等多个领域,解决了大数据量下的实时分析和事务处理问题。
三、分布式数据库的未来趋势
随着云计算和容器化技术的发展,未来的分布式数据库可能会更加注重云原生,即更好地适应云环境的弹性伸缩和资源管理。此外,随着事务处理和分析查询需求的融合,HTAP(混合事务/分析处理)将成为一个重要方向。TiDB等数据库已经在尝试实现这一目标,旨在提供单一系统下同时支持在线事务处理(OLTP)和在线分析处理(OLAP)的能力。
同时,随着AI和机器学习的普及,数据库可能会集成更多的智能化特性,如自动调优和异常检测。在安全性方面,隐私保护和数据加密也将成为分布式数据库设计的重要考量。
总结来说,分布式数据库从单机到分布式、从NoSQL到NewSQL的演进,反映了数据库技术应对数据规模挑战的创新。未来,分布式数据库将继续优化性能、增强扩展性,同时兼顾事务处理和分析查询,以满足日益复杂的数据处理需求。
细说分布式数据库的过去、现在与未来细说分布式数据库的过去、现在与未来
随着大数据这个概念的兴起以及真实需求在各个行业的落地,很多人都热衷于讨论分布式数据库,今天就这个话题,主要分为
三部分:第一部分讲一下分布式数据库的过去和现状,希望大家能对这个领域有一个全面的了解;第二部分讲一下TiDB的架构
以及最近的一些进展;最后结合我们开发TiDB过程中的一些思考讲一下分布式数据库未来可能的趋势。
一、分布式数据库的历史和现状
1、从单机数据库说起
关系型数据库起源自1970年代,其最基本的功能有两个:
把数据存下来;
满足用户对数据的计算需求。
第一点是最基本的要求,如果一个数据库没办法把数据安全完整存下来,那么后续的任何功能都没有意义。当满足第一点后,
用户紧接着就会要求能够使用数据,可能是简单的查询,比如按照某个Key来查找Value;也可能是复杂的查询,比如要对数据
做复杂的聚合操作、连表操作、分组操作。往往第二点是一个比第一点更难满足的需求。
在数据库发展早期阶段,这两个需求其实不难满足,比如有很多优秀的商业数据库产品,如Oracle/DB2。在1990年之后,出
现了开源数据库MySQL和PostgreSQL。这些数据库不断地提升单机实例性能,再加上遵循摩尔定律的硬件提升速度,往往能
够很好地支撑业务发展。
接下来,随着互联网的不断普及特别是移动互联网的兴起,数据规模爆炸式增长,而硬件这些年的进步速度却在逐渐减慢,人
们也在担心摩尔定律会失效。在此消彼长的情况下,单机数据库越来越难以满足用户需求,即使是将数据保存下来这个最基本
的需求。
2、分布式数据库
所以2005年左右,人们开始探索分布式数据库,带起了NoSQL这波浪潮。这些数据库解决的首要问题是单机上无法保存全部
数据,其中以HBase/Cassadra/MongoDB为代表。为了实现容量的水平扩展,这些数据库往往要放弃事务,或者是只提供简
单的KV接口。存储模型的简化为存储系统的开发带来了便利,但是降低了对业务的支撑。
(1)NoSQL的进击的进击
HBase是其中的典型代表。HBase是Hadoop生态中的重要产品,Google BigTable的开源实现,所以这里先说一下BigTable。
BigTable是Google内部使用的分布式数据库,构建在GFS的基础上,弥补了分布式文件系统对于小对象的插入、更新、随机
读请求的缺陷。HBase也按照这个架构实现,底层基于HDFS。HBase本身并不实际存储数据,持久化的日志和SST file存储
在HDFS上,Region Server通过 MemTable 提供快速的查询,写入都是先写日志,后台进行Compact,将随机写转换为顺序
写。数据通过 Region 在逻辑上进行分割,负载均衡通过调节各个Region Server负责的Region区间实现,Region在持续写入
后,会进行分裂,然后被负载均衡策略调度到多个Region Server上。
前面提到了,HBase本身并不存储数据,这里的Region仅是逻辑上的概念,数据还是以文件的形式存储在HDFS上,HBase并
不关心副本个数、位置以及水平扩展问题,这些都依赖于HDFS实现。和BigTable一样,HBase提供行级的一致性,从CAP理
论的角度来看,它是一个CP的系统,并且没有更进一步提供 ACID 的跨行事务,也是很遗憾。
HBase的优势在于通过扩展Region Server可以几乎线性提升系统的吞吐,及HDFS本身就具有的水平扩展能力,且整个系统
成熟稳定。但HBase依然有一些不足。首先,Hadoop使用Java开发,GC延迟是一个无法避免问题,这对系统的延迟造成一
些影响。另外,由于HBase本身并不存储数据,和HDFS之间的交互会多一层性能损耗。第三,HBase和BigTable一样,并不
下载后可阅读完整内容,剩余3页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2016-11-22 上传
2020-12-22 上传
2021-10-25 上传
2021-02-03 上传
点击了解资源详情

weixin_38674415
- 粉丝: 5
- 资源: 920
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular程序高效加载与展示海量Excel数据技巧
- Argos客户端开发流程及Vue配置指南
- 基于源码的PHP Webshell审查工具介绍
- Mina任务部署Rpush教程与实践指南
- 密歇根大学主题新标签页壁纸与多功能扩展
- Golang编程入门:基础代码学习教程
- Aplysia吸引子分析MATLAB代码套件解读
- 程序性竞争问题解决实践指南
- lyra: Rust语言实现的特征提取POC功能
- Chrome扩展:NBA全明星新标签壁纸
- 探索通用Lisp用户空间文件系统clufs_0.7
- dheap: Haxe实现的高效D-ary堆算法
- 利用BladeRF实现简易VNA频率响应分析工具
- 深度解析Amazon SQS在C#中的应用实践
- 正义联盟计划管理系统:udemy-heroes-demo-09
- JavaScript语法jsonpointer替代实现介绍
