
−2w
1
− 1w
2
+ b ≥ 1
−1w
1
− 0w
2
+ b ≥ 1
3w
1
+ 0w
2
− b ≥ 1
透過聯立解及交集後,可以得到的 W=[1,-1]、b=2,但
是 QP 方法實在是效率太低了,當為正定時,用橢圓
法可在多項式時間內解二次規劃問題。當為非正定時,
二次規劃問題是 NP 困難的(NP-Hard)。即使 Q 只存
在一個負特徵值時,二次規劃問題也是 NP 困難的,可
以試想當資料有幾萬筆、每筆的特徵又有幾千個,這
樣的做法是非常非常消耗效能的。
2. Slack Variable
SVM 在不斷修正變化的過程中... 線可能會不斷地
偏移!甚至變得無法分出正確的選擇,因為有可能在
輸入值的時候輸入錯誤!導致我們給的 y 給錯,因而
造成許多不可挽回的錯誤,畢竟人有失足馬有亂蹄,因
此,為了避免這種情況發生,將太誇張、差太多的值給
剔除在調整的計算中。
2.1. Significance
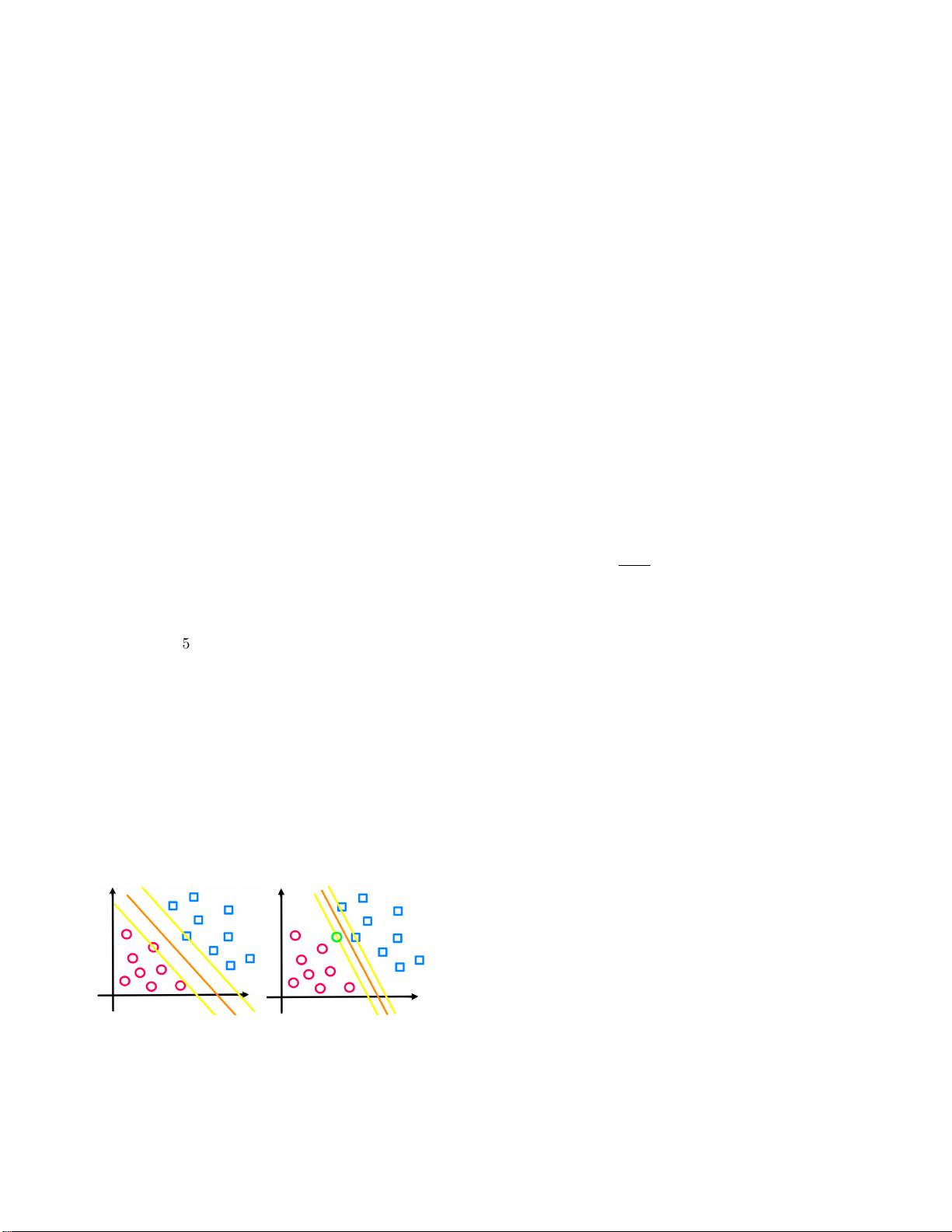
所以在這過程中,可能會有偏差過大或是錯誤的
數據出現 (如圖5),導致計算出來的線並不是最理想的
線,因次需在這邊加入 1. 鬆弛變數 (ξ):這個變數代
表的意思類似容錯率的概念,因此這個數值沒有負數,
而這個鬆弛變數是為每一個點所客製化的,因此他不
會是同一個數。2. 懲罰因子 (C):這個因子代表的意
思是你有多重視離群點,所以當我們懲罰因子越大就
代表我們越重視離群點。這個概念有點像是當我的數
據出現錯誤時,要用多大力道去將分割線打到能越接
近數據正確的地方。這樣的話就能夠透過加入來適時
的容錯,也藉由這兩個來幫助找到最理想的線 原本的
图 5. 偏差過大的點導致 SVM 線不理想
SVM 因為沒有加入鬆弛變數及懲罰因子的部分,所以
他所要求的值變得非常的硬性、非常直接並且強烈的
劃分出來,因此在沒有加入這兩項時的 SVM 有一個稱
呼”硬間隔”分類;在加入這兩項後,因為對錯誤的數
據或離群點有了兼容得特性出現,因此不會再這麼的
硬性劃分,也就變成了”軟間隔”分類。
2.2. Variety
已經說明了什麼是鬆弛變數及懲罰因子,了解他
們是做什麼用以及對我們的 SVM 有什麼樣的幫助,接
著將鬆弛變數加入式子中,上面有說過鬆弛變數是為
每個點所客製的所以代表每個點都有自己的一個鬆弛
變數,而這個鬆弛變數的目的就是要將原本錯誤的部
分分到正確的上面,因此就將鬆弛變數加入限制式中,
因為加入了鬆弛變數的關係而導致我們將每一個值都
是正確的,但是這樣會變成無限制的擴充,因為只有加
在限制式中,將限制式放寬了,但是要求的極小值卻沒
有變,所以接下來就要再求極小值那邊做變化,在這邊
將所有的鬆弛變數相加後再給他一個懲罰因子,因為
每加入一個鬆弛變數,就必須支付一次代價。:
期望求得:min
w,b
∥W ∥
2
2
+ C
∑
n
i
ξ
i
限制條件:y
n
(
W
T
X
n
− b
)
≥ 1 −ξ
n
, ξ
n
≥ 0
這樣加入到極值部分其實要想到剛剛一直說到的幾件
事:
1. 鬆弛變數 (ξ) 是客製化的變數,假如 A 點是被正
確的劃分的話,A 點鬆弛變數就是 0;假如 A 點
沒有被正確劃分且算出來的結果是-1 的話,A 點
的鬆弛變數就是 2。
2. 懲罰因子 (C) 會與“相加後的鬆弛變數”相乘並
放在極小值的求解地方是為了來表示有多重視離
群值。
上面兩件事可以知道當越重視離群值的話 C 就會越大,
代表說當他如果有離群值的話,會影響到整個最小值
的部份,有可能導致原本是可以很正確的分出,卻因為
幾個離群值而導致偏了方向。
3. Lagrange Multiplier
Lagrange Multiplier 又稱拉格朗日乘數法,其目
的是在一個函式且有約束條件下要求極值 (最大/最小
值)。此方法會引入一個以上新的未知數,而稱這個未
知數為拉格朗因子。看一下他要怎麼表示:
3
剩余10页未读,继续阅读

_小树不倒我不倒
- 粉丝: 0
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- WebLogic集群配置与管理实战指南
- AIX5.3上安装Weblogic 9.2详细步骤
- 面向对象编程模拟试题详解与解析
- Flex+FMS2.0中文教程:开发流媒体应用的实践指南
- PID调节深入解析:从入门到精通
- 数字水印技术:保护版权的新防线
- 8位数码管显示24小时制数字电子钟程序设计
- Mhdd免费版详细使用教程:硬盘检测与坏道屏蔽
- 操作系统期末复习指南:进程、线程与系统调用详解
- Cognos8性能优化指南:软件参数与报表设计调优
- Cognos8开发入门:从Transformer到ReportStudio
- Cisco 6509交换机配置全面指南
- C#入门:XML基础教程与实例解析
- Matlab振动分析详解:从单自由度到6自由度模型
- Eclipse JDT中的ASTParser详解与核心类介绍
- Java程序员必备资源网站大全
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


