GPT-3:OpenAI引领小样本学习新纪元
需积分: 42 196 浏览量
更新于2024-07-15
收藏 6.44MB PDF 举报
"OpenAI发布了一款名为GPT-3的小样本学习器语言模型,该模型具有1750亿个参数,是目前最先进的语言模型。论文由32位作者共同完成,共计72页,详细阐述了如何通过大规模预训练和微调,使模型在没有大量特定任务数据的情况下,仅凭少量示例或简单指令就能执行新的语言任务。"
在《Language Models are Few-Shot Learners》这篇论文中,OpenAI团队揭示了小样本学习在自然语言处理(NLP)领域的巨大潜力。传统的NLP任务处理方式通常是在大规模文本数据上进行预训练,然后针对具体任务进行微调,这个过程需要数千甚至数万个例子。然而,GPT-3展示了一种全新的可能性,它在不需大量任务特定数据的情况下,仅通过少量示例就能适应并执行新的语言任务,这更接近人类的学习方式。
小样本学习(Few-Shot Learning)是指机器学习模型在仅有少数样例的情况下,能够快速理解和执行新任务的能力。在GPT-3的案例中,这一特性显著提高了模型的泛化能力,使其能应对各种未曾见过的任务。这种进步对于减少对大规模标注数据的依赖、提高模型的灵活性和实用性具有重要意义。
GPT-3的规模空前,拥有1750亿个参数,远超其前代GPT-2的15亿参数。模型的大规模使得它能捕获更多复杂的语言结构和模式,这对于理解和生成自然语言至关重要。大规模的参数数量也意味着更高的计算需求,但这并未削弱其在小样本设置下的表现力。
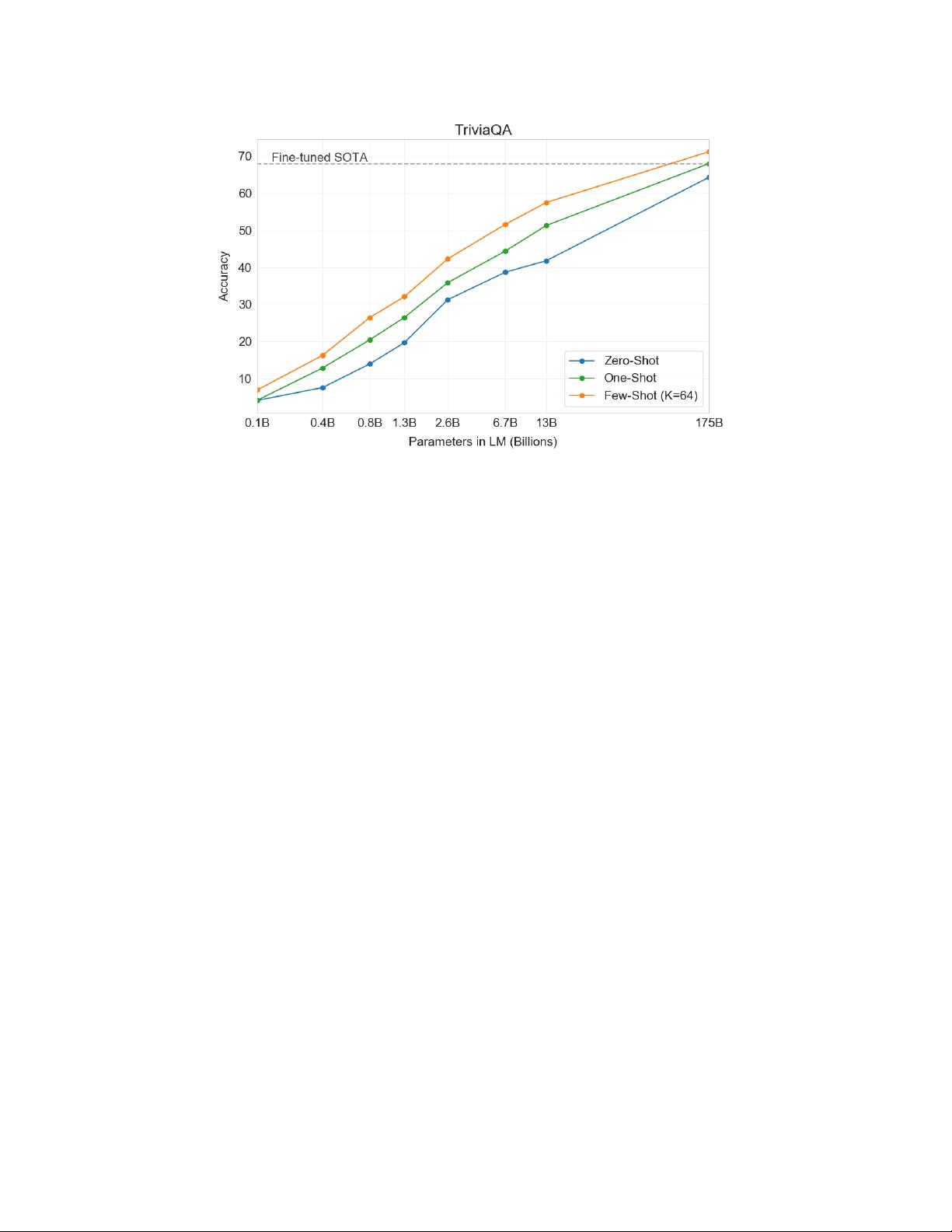
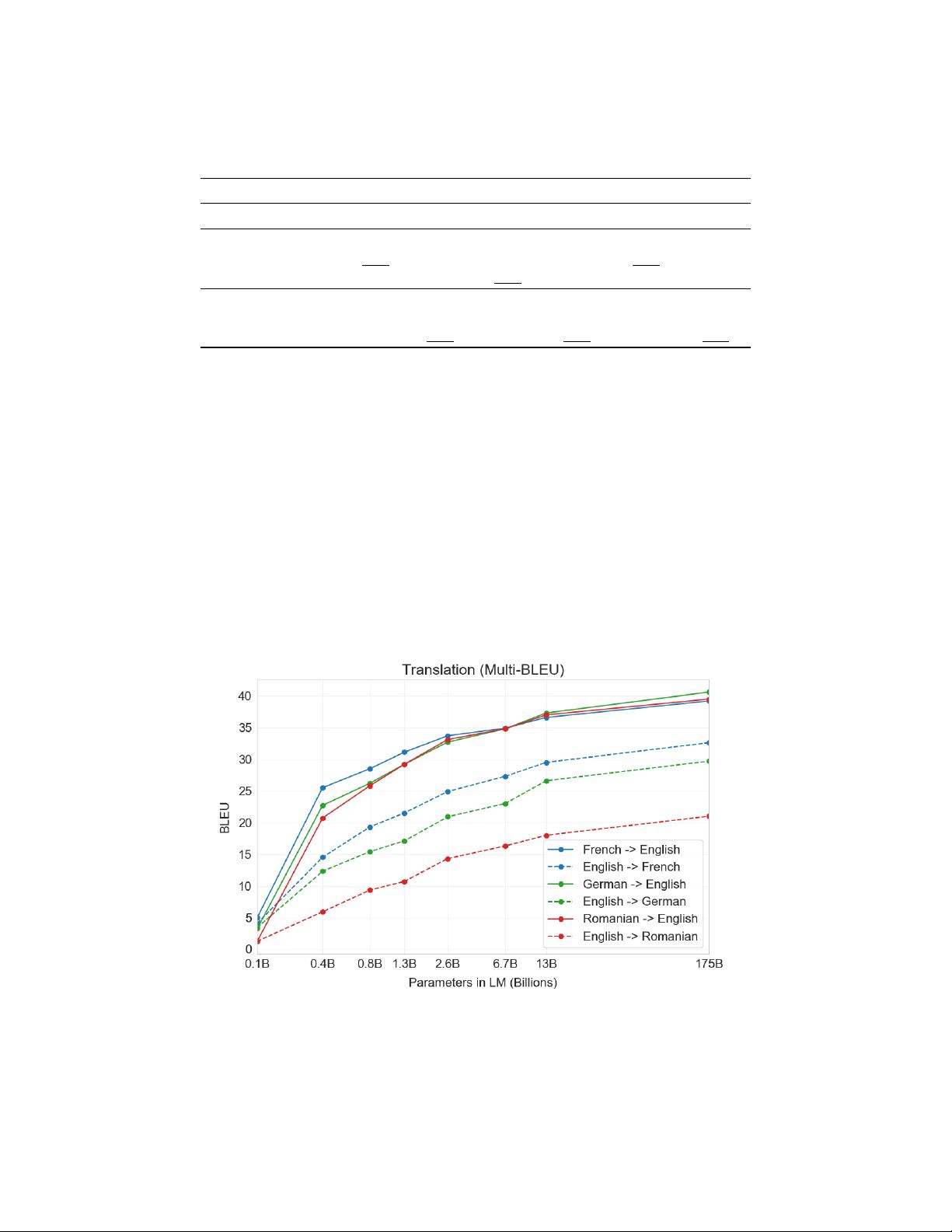
在实验中,GPT-3展示了多种NLP任务的出色性能,包括但不限于文本生成、问答系统、翻译、代码编写等。这些结果表明,随着模型规模的扩大,其在任务泛化方面的性能也在显著提升。同时,论文还讨论了模型的局限性,如理解复杂推理和长期依赖的问题,以及在某些情况下可能产生的不准确或有害的输出。
OpenAI的GPT-3展示了小样本学习在语言模型中的强大应用,预示着未来NLP领域的发展方向将更加侧重于模型的泛化能力和适应性,而不仅仅是对特定任务的优化。这不仅有助于减少数据收集和标注的成本,也为构建更加智能和自主的AI系统奠定了基础。然而,随着模型规模的增加,也带来了训练和部署上的挑战,需要寻找更高效、更经济的解决方案。
Setting
LAMBADA
(acc)
LAMBADA
(ppl)
StoryCloze
(acc)
HellaSwag
(acc)
SOTA 68.0
a
8.63
b
91.8
c
85.6
d
GPT-3 Zero-Shot 76.2 3.00 83.2 78.9
GPT-3 One-Shot 72.5 3.35 84.7 78.1
GPT-3 Few-Shot 86.4 1.92 87.7 79.3
Table 3.2: Performance on cloze and completion tasks.
GPT-3 significantly improves SOTA on LAMBADA while
achieving respectable performance on two difficult completion prediction datasets.
a
[
Tur20
]
b
[
RWC
+
19
]
c
[
LDL19
]
d
[LCH
+
20]
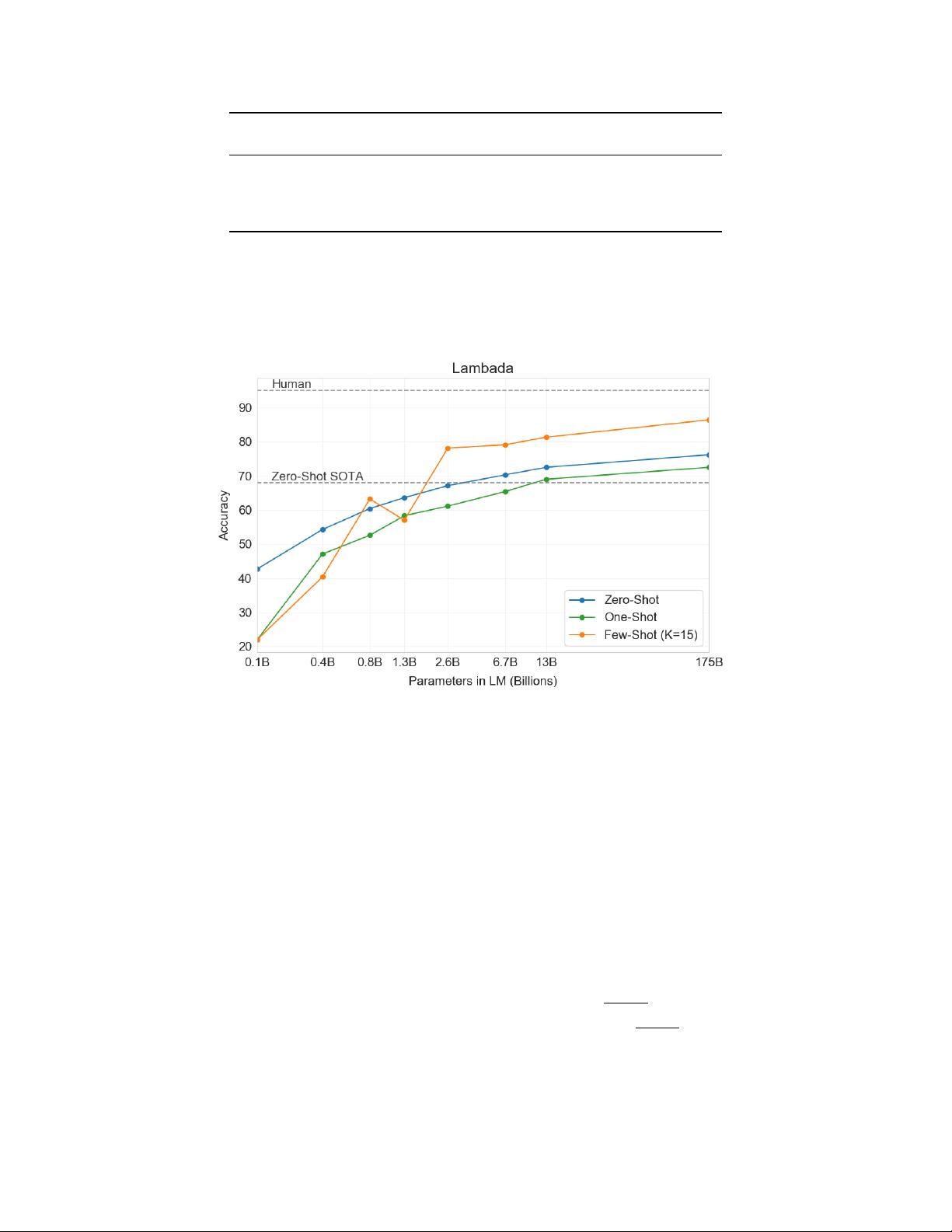
Figure 3.2:
On LAMBADA, the few-shot capability of language models results in a strong boost to accuracy. GPT-3
2.7B outperforms the SOTA 17B parameter Turing-NLG [
Tur20
] in this setting, and GPT-3 175B advances the state of
the art by 18%. Note zero-shot uses a different format from one-shot and few-shot as described in the text.
and [
Tur20
]) and argue that “continuing to expand hardware and data sizes by orders of magnitude is not the path
forward”. We find that path is still promising and in a zero-shot setting GPT-3 achieves 76% on LAMBADA, a gain of
8% over the previous state of the art.
LAMBADA is also a demonstration of the flexibility of few-shot learning as it provides a way to address a problem that
classically occurs with this dataset. Although the completion in LAMBADA is always the last word in a sentence, a
standard language model has no way of knowing this detail. It thus assigns probability not only to the correct ending but
also to other valid continuations of the paragraph. This problem has been partially addressed in the past with stop-word
filters [
RWC
+
19
] (which ban “continuation” words). The few-shot setting instead allows us to “frame” the task as a
cloze-test and allows the language model to infer from examples that a completion of exactly one word is desired. We
use the following fill-in-the-blank format:
Alice was friends with Bob. Alice went to visit her friend . → Bob
George bought some baseball equipment, a ball, a glove, and a . →
When presented with examples formatted this way, GPT-3 achieves 86.4% accuracy in the few-shot setting, an increase
of over 18% from the previous state-of-the-art. We observe that few-shot performance improves strongly with model
size. While this setting decreases the performance of the smallest model by almost 20%, for GPT-3 it improves accuracy
by 10%. Finally, the fill-in-blank method is not effective one-shot, where it always performs worse than the zero-shot
setting. Perhaps this is because all models still require several examples to recognize the pattern.
12

剩余71页未读,继续阅读
2020-12-20 上传
2021-02-23 上传
2020-07-22 上传
2023-04-25 上传
2021-04-05 上传
2023-07-30 上传
2023-04-24 上传
点击了解资源详情
点击了解资源详情

syp_net
- 粉丝: 158
- 资源: 1187
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java集合ArrayList实现字符串管理及效果展示
- 实现2D3D相机拾取射线的关键技术
- LiveLy-公寓管理门户:创新体验与技术实现
- 易语言打造的快捷禁止程序运行小工具
- Microgateway核心:实现配置和插件的主端口转发
- 掌握Java基本操作:增删查改入门代码详解
- Apache Tomcat 7.0.109 Windows版下载指南
- Qt实现文件系统浏览器界面设计与功能开发
- ReactJS新手实验:搭建与运行教程
- 探索生成艺术:几个月创意Processing实验
- Django框架下Cisco IOx平台实战开发案例源码解析
- 在Linux环境下配置Java版VTK开发环境
- 29街网上城市公司网站系统v1.0:企业建站全面解决方案
- WordPress CMB2插件的Suggest字段类型使用教程
- TCP协议实现的Java桌面聊天客户端应用
- ANR-WatchDog: 检测Android应用无响应并报告异常
