Python爬虫教程:静态与动态网页图片抓取
需积分: 21 201 浏览量
更新于2024-08-04
收藏 86KB DOC 举报
"这篇文档是关于Python爬虫的案例讲解,特别针对新手,旨在教授如何使用Python抓取网页上的图片数据。文档详细介绍了如何处理静态和动态网页,并提供了使用requests库和selenium库的示例。主要内容包括解析静态网页结构,定位图片元素,以及使用xpath库提取图片URL。此外,还涉及到了利用多线程技术提高爬取效率的实践代码。"
在Python编程领域,网络爬虫是一个重要的应用方向,尤其对于数据挖掘和分析而言。本案例主要讲解了如何使用Python进行网页图片的爬取。首先,区分了静态网页和动态网页。静态网页通常可以直接通过HTTP请求获取,而动态网页则需要模拟浏览器行为,这里推荐使用selenium库。不过,文档首先从静态网页入手,以"不羞涩|真实的图片分享交友社区"为例。
在静态网页的爬取过程中,首先分析了网页的URL规律,发现每一页的URL都是基本地址加上"page=数字"的形式。接着,通过浏览器的开发者工具(F12)观察HTML源代码,找到图片元素,发现图片的URL存储在img标签的src属性中。因此,可以使用XPath库来提取这些信息。XPath是一种在XML文档中查找信息的语言,"//img/@src"表达式就是用来查找所有img标签并提取它们的src属性值,即图片链接。
为了提高爬取速度,文档引入了多线程的概念,使用了`concurrent.futures.ThreadPoolExecutor`库。通过创建线程池,可以并发地执行多个下载任务,显著提升爬虫的效率。在提供的代码示例中,创建了一个下载类,定义了初始化方法、URL列表的生成以及多线程下载图片的逻辑。同时,还包含了创建目标目录的函数,确保图片能够被正确保存。
这个案例不仅介绍了Python爬虫的基本步骤,还展示了如何在实际操作中解决效率问题,对Python初学者来说是一份非常有价值的教程。通过学习和实践这份文档,读者可以掌握静态网页爬取、XPath表达式使用以及多线程爬虫的基本技能,为进一步深入学习和开发更复杂的爬虫项目打下坚实的基础。
python 一大用途就是爬取网页数据,这篇我们来用 python 爬取网页图片数据,其中网页可
以分为静态网页和动态网页,其中静态网页我们一般用 requests 库,动态网页我们需要用
到 selenium 库,先来看静态网页爬取。
1:静态网页爬取
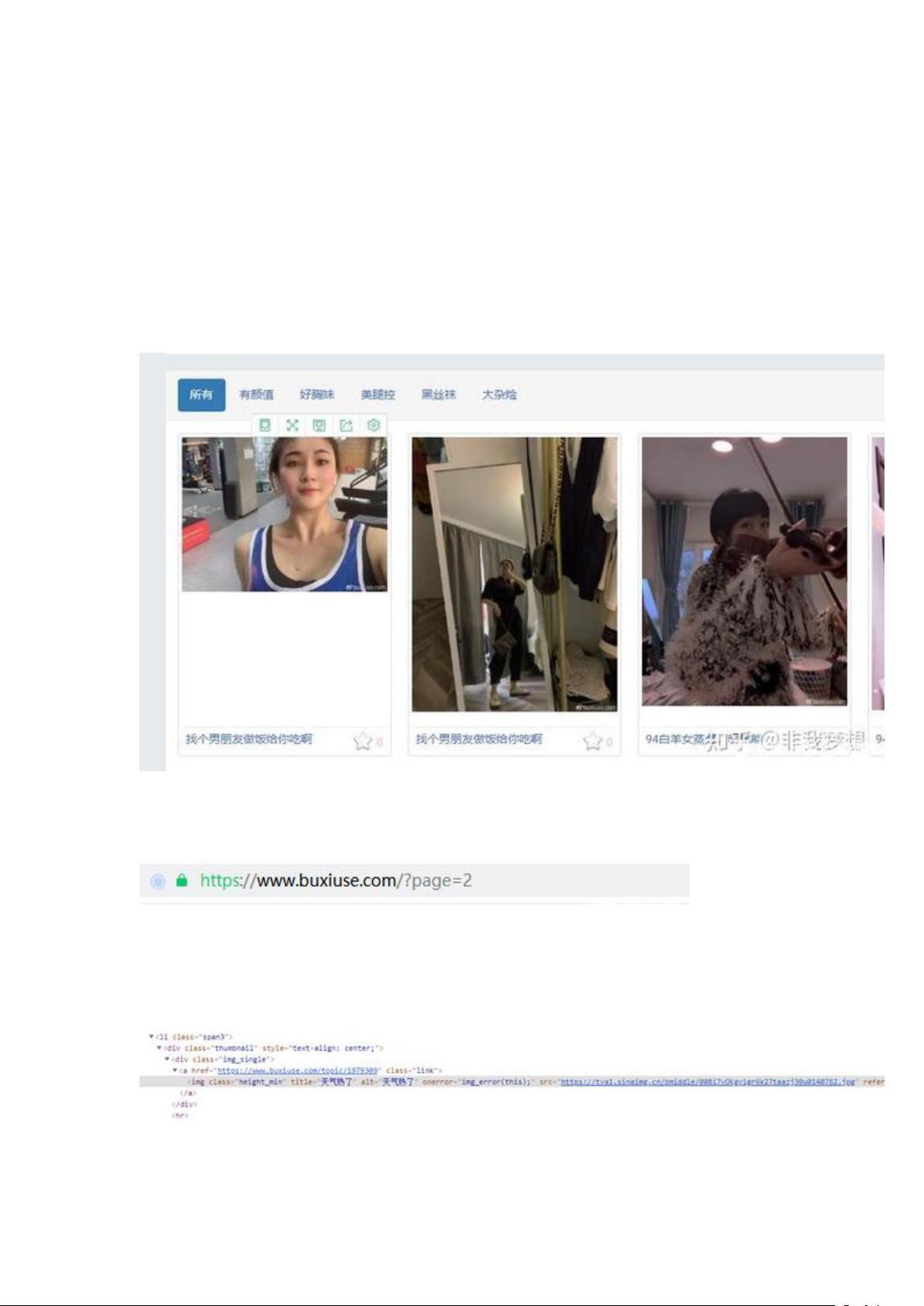
我们先打开一个网页,网址是不羞涩 | 真实的图片分享交友社区,打开后我们看到内容如
下:
点击下一页,我们看到网址变为:
所以网址变化规律为每一页都是在基本地址“https://www.buxiuse.com/” 后面加上 page=数
字,我们爬取前 60 页的图片。按 F12 审查元素,我们可以看到图片元素的标签是:
下载后可阅读完整内容,剩余5页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-02-22 上传
2024-02-04 上传
2020-09-20 上传
2021-05-25 上传
2024-06-21 上传
2023-12-18 上传

GIS之家
- 粉丝: 1383
- 资源: 51
 我的内容管理
展开
我的内容管理
展开







最新资源
- 《JAVA面试题》--轻醒Java面试题.zip
- Estudy-Front
- 基于uniapp的sticky吸顶示例
- darkUni_FDFD_
- tmuxinator:轻松管理复杂的 tmux 会话-开源
- Google Drive 网页ui redesign .xd素材下载
- vfp控制TSC标签打印.zip
- MonoTail:Windows的类似尾巴的应用程序-开源
- matlab_matlab_
- javaee登陆页面源码-ceylon-dddsample:dddsample项目的Java+JEE移植的Ceylon+JEE移植
- Python库 | tqsdk-2.5.1-cp38-cp38-win32.whl
- dwsurvey一款简单、高效、成熟、稳定、专业的开源问卷系统vue前端代码
- 行业文档-设计装置-一种用于汽车仪表系统电路教学示教箱.zip
- platform-pharmacy
- 日历时间线、任务列表应用网页UI .sketch素材下载
- 《JAVA面试题》--高频算法、计算机网络、操作系统、C++、Java、golang、K8s、消息队列等常见面试题.zip
