迈向大数据时代:告别传统ETL,探索Spark开发
版权申诉
126 浏览量
更新于2024-06-21
收藏 1.13MB PDF 举报
在IT领域不断发展的今天,"藏经阁-Get rid of traditional ETL, Mo" 这篇文章探讨了传统ETL(Extract, Transform, Load)方法在大数据时代所面临的转型挑战。ETL曾经是企业数据管理的核心环节,用于从源系统提取数据,进行转换处理,然后将其加载到数据仓库或数据集市中,以支持业务智能分析。然而,随着业务需求的增长,特别是大数据、云计算和微服务的兴起,传统的ETL模型正面临着革新。
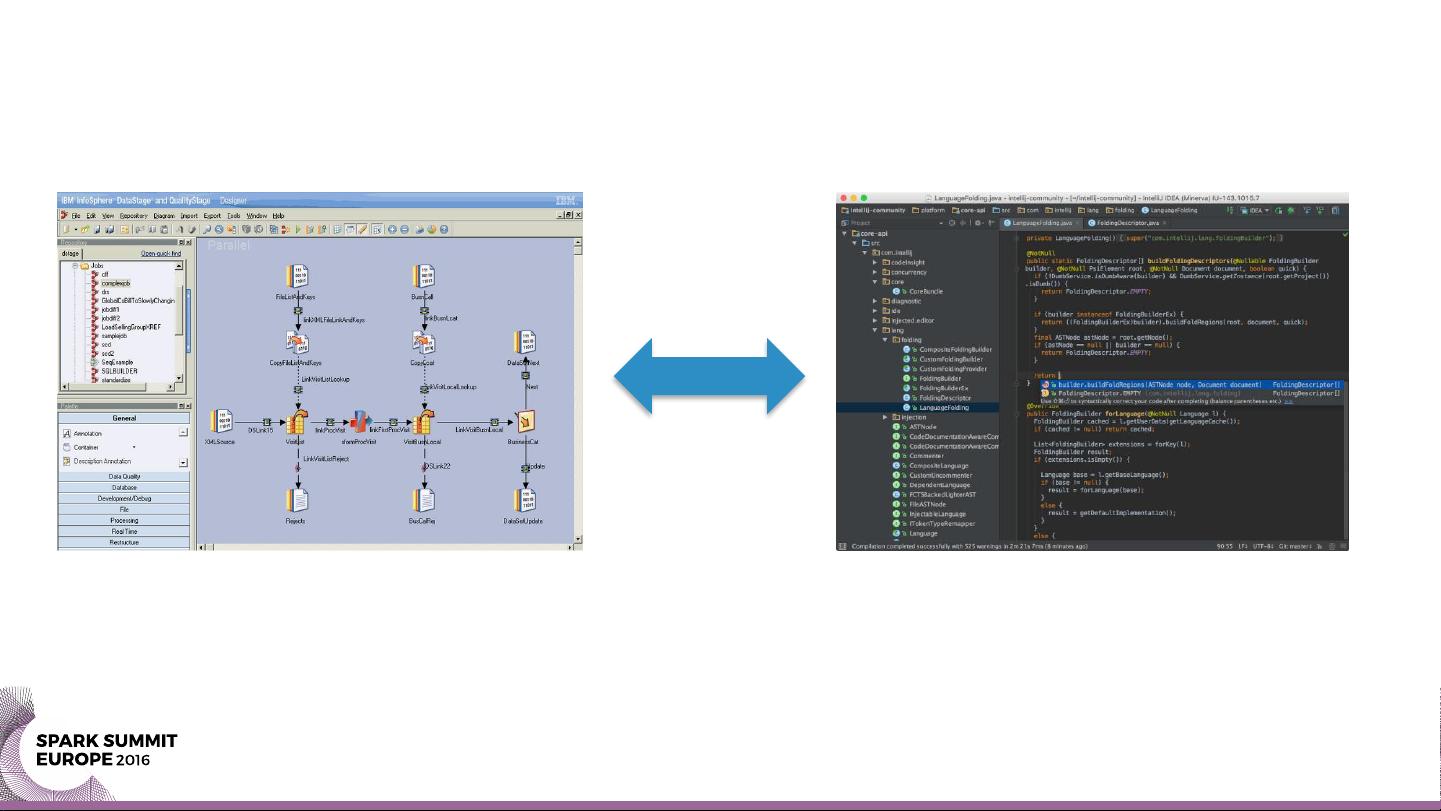
首先,文章定义了ETL,它是一个可重复执行的程序,用于数据的迁移,包括从源系统获取数据(Extract)、对数据进行过滤、映射、增强、验证、排序等操作(Transform),并将处理后的数据加载到目标存储(Load)。应用场景广泛,涵盖数据加载、数据迁移、数据摄入等多个方面。过去的ETL工具如IBM InfoSphere DataStage、Oracle Warehouse Builder等,已经不再能满足现代数据处理的需求。
随着大数据时代的到来,传统的数据仓库逐渐被数据湖(Data Lake)所取代,这使得数据不再预先结构化,而是以原始形式存储,提高了灵活性。同时,随着应用程序架构转向微服务模式,数据处理的需求不再是单一的批量处理,而是需要实时性和异步性。这导致了ETL角色的演变,不再局限于数据集成,而是可能需要开发针对Hadoop、Spark或Flink等分布式计算框架的连接器,或者提供图形用户界面(GUI)以简化代码生成。
文章提出了几个未来ETL工具可能的发展方向:一是仅专注于提供更高级别的接口进行集成;二是重构后端架构,使其与大数据平台无缝集成;三是发展具有代码生成能力的可视化工具,降低开发者的编程负担。最后,作者通过一个问答形式强调了开发者在新时代ETL中的挑战:如何在快速变化的技术环境中找到最有效的方法来处理复杂的数据流和实时处理需求。
"藏经阁-Get rid of traditional ETL, Mo" 文章深入探讨了在大数据和云计算驱动的变革下,IT行业如何摆脱传统ETL的束缚,转向更为灵活、高效的数据处理方式,并为开发者们提出了适应新环境的关键思考点。随着技术的演进,未来的ETL工具将更加注重易用性、扩展性和适应性,以满足不断增长的业务需求。
剩余19页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-10-06 上传
2022-10-17 上传
2019-07-17 上传
2021-10-07 上传
2023-10-21 上传
2021-05-14 上传

weixin_40191861_zj
- 粉丝: 86
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- windbg实验 1
- 网络认识实验 计算机网络
- 单片机C语言的使用技巧
- MATLAB 环境下的串行数据通信系统设计
- Visual C++开发工具与调试技巧整理
- 基于温度传感器的采样
- StrutsCatalogLazyList
- 卫星通信论文(数字电视系统信源信道编码技术)
- 高质量C++/C编程指南
- shell经典的面试题目
- Regsvr32命令修复系统故障实例
- The Direct3D® 10 System
- 网管常用的网络命令.doc
- 企业内部通信系统源码
- iphone application progamming guide
- 全国计算机水平与软件专业技术资格(水平)考试2008年下半年程序员下午试卷B
