“云时代大数据管理引擎HAWQ++”
在当今的云计算时代,大数据管理和分析是企业决策的关键因素。HAWQ(High-Performance Analytics Warehouse Query)作为一个强大的并行SQL引擎,旨在解决大规模数据集的高效处理问题。该技术最初源于Pivotal,现在作为Apache软件基金会的孵化项目,它在大数据领域扮演着重要的角色。偶数科技推出的HAWQ++是对HAWQ的进一步发展和优化,提供了更高效、更稳定的数据管理解决方案。
HAWQ的发展历程可以追溯到GoH,经过不断迭代,从HAWQ Alpha到HAWQ 1.0,再到1.x版本,最终演进到HAWQ 2.0,并成为Apache孵化器项目的一部分。偶数科技的HAWQ++在此基础上进行了增强,以满足企业对高性能、高可用性和扩展性的需求。
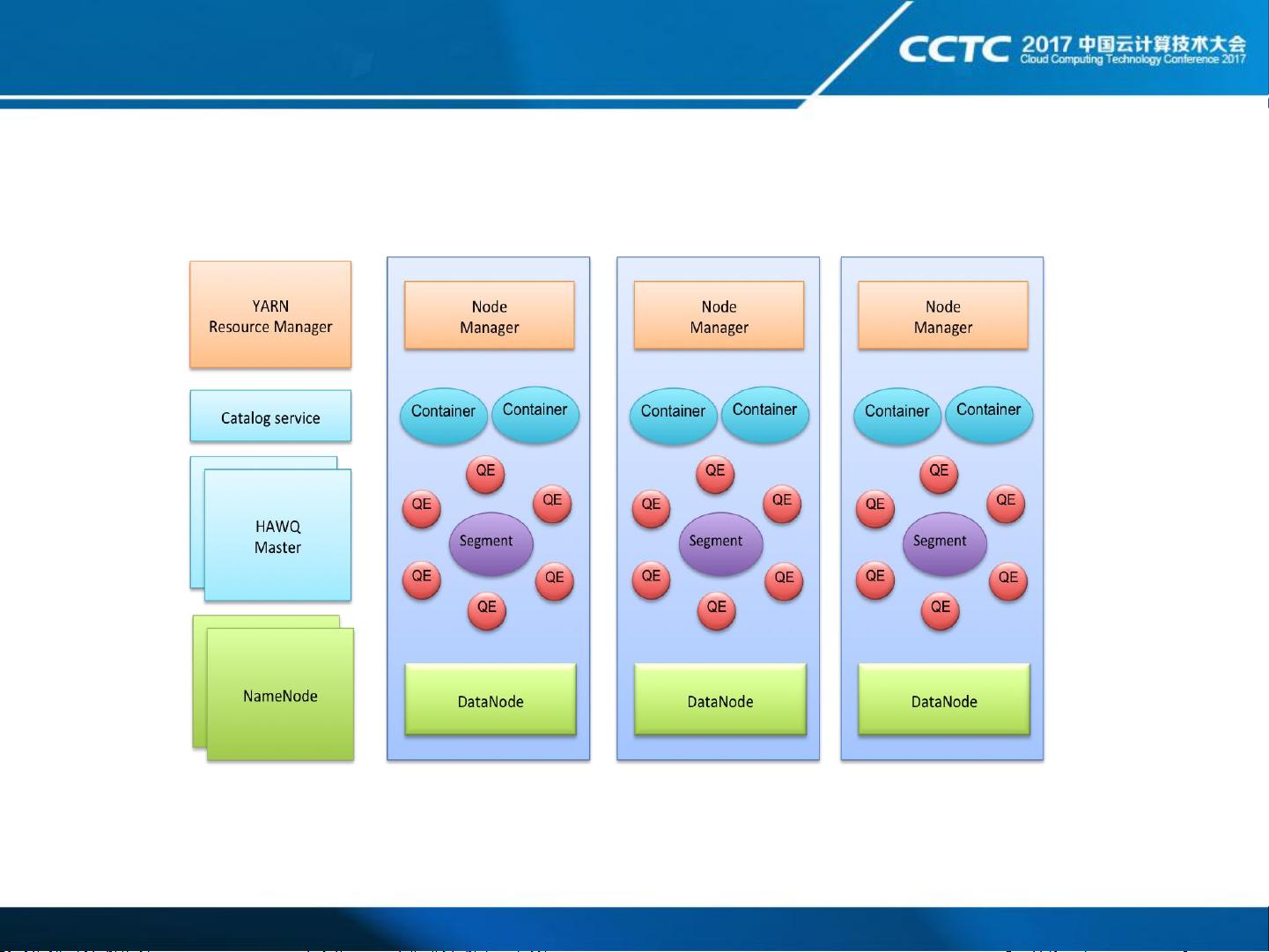
HAWQ的架构设计紧密集成于Hadoop生态系统,利用YARN(Yet Another Resource Negotiator)进行资源调度。其组件包括客户端、解析器/分析器、优化器、调度器、物理段、主节点、故障容忍服务、目录服务、虚拟段和资源经纪人等。通过这些组件,HAWQ能够高效地处理复杂的SQL查询。
HAWQ查询处理流程中,优化器起着至关重要的作用。例如,在处理SELECT语句时,HAWQ会根据查询条件应用不同类型的motion操作,如redistributemotion用于根据哈希值重新分布数据,broadcastmotion将数据广播到所有节点,而gathermotion则将数据从多个节点聚合到一个节点,以实现并行计算。
资源管理是HAWQ的另一大亮点。它采用三级资源管理模式,包括全局、内部和操作符级别的资源管理,以及多级资源队列。这使得HAWQ能够精细控制CPU和内存资源的分配,确保高效运行的同时,适应不同查询和操作的需求。
HAWQ在存储方面支持行式存储(Row-oriented)的Append-Only(AO)表格式,且支持快速压缩算法如Quicklz和zlib,以节省存储空间并提高读取速度。
HAWQ及HAWQ++是云时代大数据管理的重要工具,它们提供了一种强大的SQL接口,允许用户在Hadoop环境中进行复杂的数据分析,同时具备灵活的资源管理和高效的查询处理能力。这种技术对于那些需要在海量数据中快速获取洞察力的企业来说,具有极高的价值。


 我的内容管理
展开
我的内容管理
展开









