深度学习模型压缩、加速及移动端部署探究
需积分: 0 180 浏览量
更新于2023-11-28
收藏 3.51MB PDF 举报
第十七章 "模型压缩、加速及移动端部署"主要介绍了深度学习模型在移动端部署时所面临的挑战和解决方法。在该章节中,首先对模型压缩进行了理解,包括为什么需要模型压缩和加速,以及模型压缩的必要性及可行性。接着详细讨论了当前深度学习模型压缩方法,包括前端压缩和后端压缩的对比、网络剪枝、网络蒸馏、以及几种轻量化网络结构对比等。同时也介绍了深度学习模型优化加速方法,如TensorRT的加速原理、优化重构模型的方法、以及加速效果等。此外,还分析了影响神经网络速度的四个因素,并提出了如何选择压缩和加速方法以及改变网络结构设计实现模型压缩和加速的建议。
在探讨模型压缩的理论和方法时,本章指出了模型压缩在移动端部署中的重要性。由于移动设备的资源有限,包括计算能力、内存和功耗等方面的限制,因此需要对深度学习模型进行压缩和加速,以便在移动设备上高效地运行。模型压缩的目的是在尽可能少的信息损失的情况下减小模型的体积,增加运行速度并降低功耗。模型压缩的方法主要包括前端压缩和后端压缩,其中前端压缩是指在训练前对模型进行压缩,而后端压缩是指在训练后对模型进行压缩。常见的模型压缩方法包括网络剪枝和网络蒸馏等,这些方法通过减少模型参数和降低模型复杂度来达到模型压缩的效果。
对于深度学习模型的优化加速方法,本章重点介绍了TensorRT的加速原理和加速效果。TensorRT是英伟达推出的用于深度学习模型优化和部署的库,可以有效地减少模型的推理时间和内存占用。通过对模型进行优化重构,并利用GPU的并行计算能力,TensorRT可以显著提高模型的推理速度,特别适用于移动端部署。此外,本章还分析了影响神经网络速度的四个因素,包括模型的结构、硬件设备、数据输入和并行计算方式等。
在选择压缩和加速方法以及改变网络结构设计实现模型压缩和加速时,本章给出了一些建议。例如可以通过改变网络结构设计来实现模型压缩和加速,包括使用Group convolution、Depthwise separable convolution等轻量化网络结构,以减少模型参数和计算量。同时,还可以通过减少网络碎片化程度、减少组卷积的数量等方法来改变网络结构,实现模型的压缩和加速。因此,选择合适的压缩和加速方法以及改变网络结构设计是实现模型在移动端部署中高效运行的关键。
总体来说,第十七章 "模型压缩、加速及移动端部署"全面地介绍了深度学习模型在移动端部署中所面临的挑战和解决方法,对模型压缩、加速和优化的理论和方法进行了详细的阐述,并给出了一些建议,对读者在移动端部署深度学习模型时具有一定的指导意义。

Network Precision Framework/GPU:TitanXP Avg.Time(Batch=8,unit:ms) Top1 Val.Acc.(ImageNet-1k)
Resnet50 fp32 TensorFlow 24.1 0.7374
Resnet50 fp32 MXnet 15.7 0.7374
Resnet50 fp32 TRT4.0.1 12.1 0.7374
Resnet50 int8 TRT4.0.1 6 0.7226
Resnet101 fp32 TensorFlow 36.7 0.7612
Resnet101 fp32 MXnet 25.8 0.7612
Resnet101 fp32 TRT4.0.1 19.3 0.7612
Resnet101 int8 TRT4.0.1 9 0.7574
17.6 影响神经网络速度的4个因素(再稍微详细一点)
1. FLOPs(FLOPs就是网络执行了多少multiply-adds操作);
2. MAC(内存访问成本);
3. 并行度(如果网络并行度高,速度明显提升);
4. 计算平台(GPU,ARM)
17.7 压缩和加速方法如何选择?
1)对于在线计算内存存储有限的应用场景或设备,可以选择参数共享和参数剪枝方法,特别是二值量化权值和激
活、结构化剪枝.其他方法虽然能够有效的压缩模型中的权值参数,但无法减小计算中隐藏的内存大小(如特征
图). 2)如果在应用中用到的紧性模型需要利用预训练模型,那么参数剪枝、参数共享以及低秩分解将成为首要
考虑的方法.相反地,若不需要借助预训练模型,则可以考虑紧性滤波设计及知识蒸馏方法. 3)若需要一次性端
对端训练得到压缩与加速后模型,可以利用基于紧性滤波设计的深度神经网络压缩与加速方法. 4)一般情况下,
参数剪枝,特别是非结构化剪枝,能大大压缩模型大小,且不容易丢失分类精度.对于需要稳定的模型分类的应用,
非结构化剪枝成为首要选择. 5)若采用的数据集较小时,可以考虑知识蒸馏方法.对于小样本的数据集,学生网
络能够很好地迁移教师模型的知识,提高学生网络的判别性. 6)主流的5个深度神经网络压缩与加速算法相互之
间是正交的,可以结合不同技术进行进一步的压缩与加速.如:韩 松 等 人[30]结合了参数剪枝和参数共享;温
伟等人[64]以及 Alvarez等人[85]结合了参数剪枝和低秩分解.此外对于特定的应用场景,如目标
检测,可以对卷积层和全连接层使用不同的压缩与加速技术分别处理.
参考《深度神经网络压缩与加速综述》
17.8 改变网络结构设计为什么会实现模型压缩、加速?
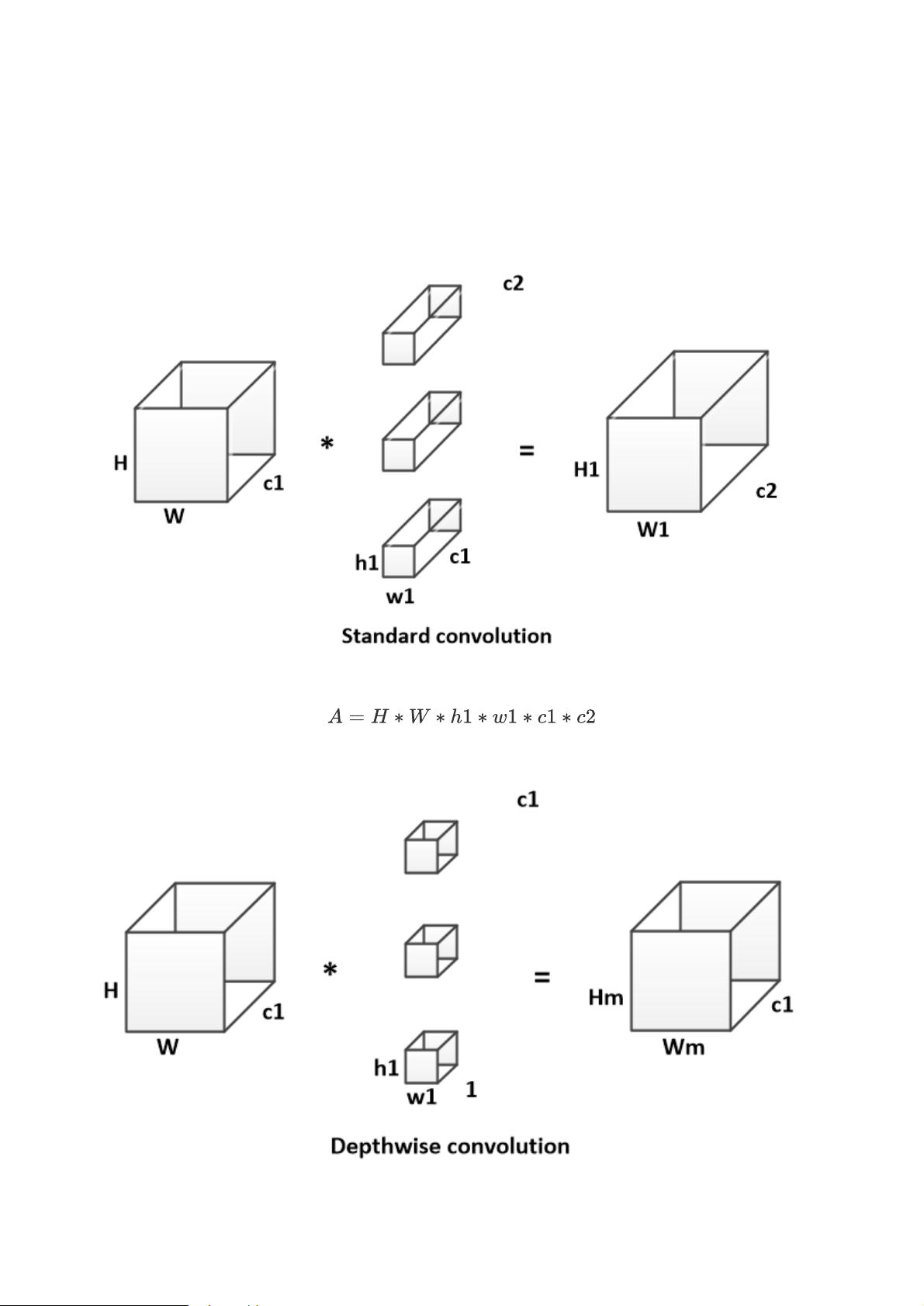
17.8.1 Group convolution
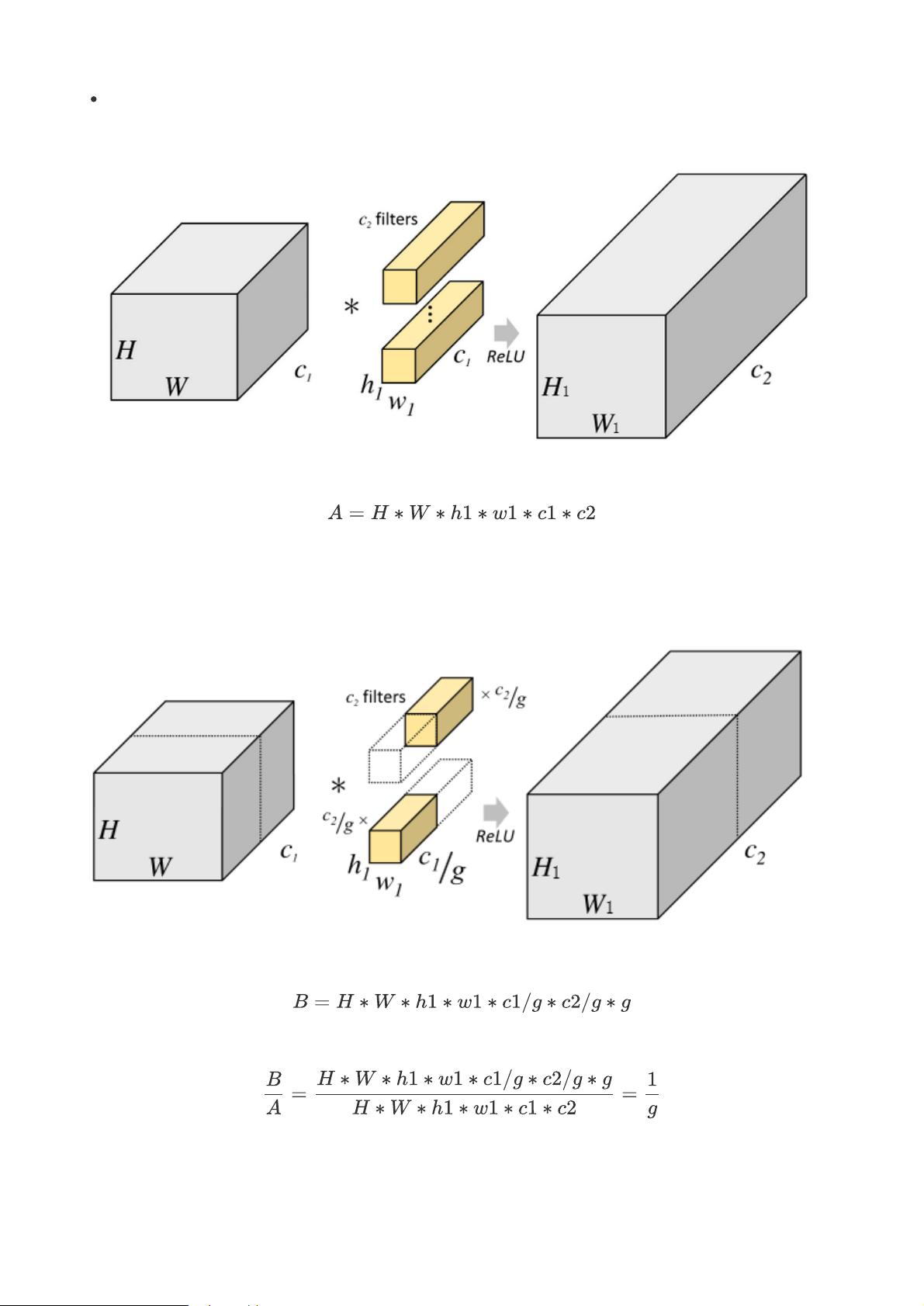
Group convolution最早出现在AlexNet中,是为了解决单卡显存不够,将网络部署到多卡上进行训练而提出。
Group convolution可以减少单个卷积1/g的参数量。如何计算的呢?
假设
输入特征的的维度为$HWC_1$;
卷积核的维度为$H_1W_1C_1$,共$C_2$个;
剩余61页未读,继续阅读
2022-08-03 上传
2020-07-27 上传
点击了解资源详情
点击了解资源详情
2023-08-23 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

黄浦江畔的夏先生
- 粉丝: 18
- 资源: 299
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
