掌握机器学习:分类与回归算法详解
需积分: 9 33 浏览量
更新于2024-09-06
收藏 557KB DOCX 举报
机器学习概述与算法介绍文档深入探讨了机器学习的基本概念、主要类别和实际应用场景。首先,它定义了机器学习的本质,即通过计算机系统模拟人类的学习过程,使计算机能够从数据中自动学习并改进自身的性能,用于预测和决策任务。核心目标是让计算机在新数据上做出准确的判断,无论是分类(如垃圾邮件识别、文本情感分析和图像识别)还是回归预测(如电影票房预测、房价估价)。
文档接着介绍了两种主要的机器学习类型:有监督学习和无监督学习。有监督学习包括分类和回归问题,如垃圾邮件识别,其中模型通过已知的标记数据进行训练,像是解答选择题;回归问题则需要预测连续数值,比如预测演员的颜值分数。无监督学习主要包括聚类(如用户群体划分、新闻主题归类)和强化学习(如游戏策略优化、机器人任务执行),这类学习中没有预先提供的答案,需要算法自行探索数据内在结构。
区分这两种学习的关键在于数据类型:有监督学习依赖于带有标签的数据,而无监督学习则仅提供未标记的数据,需要算法自行发现模式。文档还强调了数据预处理在机器学习过程中的重要性,它占据了60%-70%的工作时间,涉及到数据清洗、特征工程和降维等步骤,直接影响模型的性能。模型学习阶段包括超参数调整、交叉验证、模型选择和训练,这一步骤旨在找到最接近数据潜力的最佳模型。
模型评估是检验机器学习模型性能的关键环节,通常使用各种评估标准,如准确性、精确度、召回率等,目标是确保模型具有良好的泛化能力,能在未见过的新数据上表现稳定。机器学习是一个迭代的过程,涉及到数据的获取、预处理、模型构建和优化,以及对模型效果的持续监控和改进。理解这些核心概念和技术对于任何希望在这个领域发展的人来说都是至关重要的。
机器学习概述与算法介绍
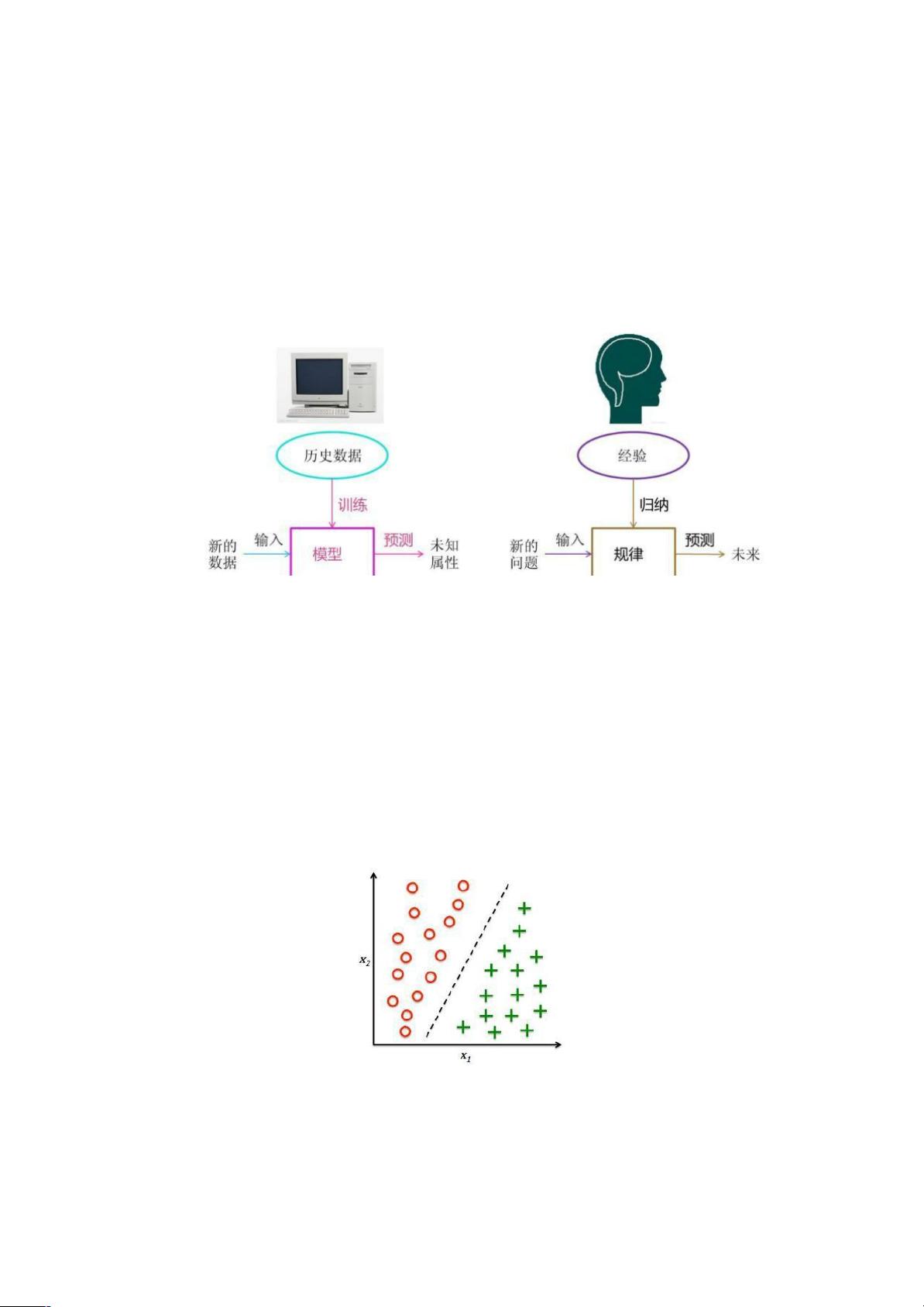
机器学习是什么?
• 研究的是计算机怎样模拟人类的学习行为,以获取新的知识或技能,
并重新组织已有的知识结构使之不断改善自身;计算机从数据中学
习出规律和模式,以应用在新数据上做预测的任务,如下图:
机器学习的分类
1、有监督学习算法:
• 分类问题
• 根据数据样本上抽取出的特征,判定其属于有限类别中的哪一
个;
• 垃圾邮件识别(结果类别:1、垃圾邮件 2、正常邮件)
• 文本情感褒贬分析(结果类别:1、褒 2、贬);
• 图像内容识别(结果类别: 1、猫 2、狗 3、人 4、羊驼);
下载后可阅读完整内容,剩余8页未读,立即下载
相关推荐




lry4000
- 粉丝: 1
 我的内容管理
展开
我的内容管理
展开








最新资源
- SEED-VPM6467高清视频采集参考原理图详解
- 孙钟秀主编操作系统课后答案解析(前五章)
- C#开发的C/S架构聊天系统功能详解
- MFC下简易计算器源码实现与编译指南
- 掌握Heroku与Node.js:快速启动指南
- Java处理Excel与PDF的poi-3.9jar包功能及下载指南
- Struts2与Ext框架整合实现动态树形结构的生成
- 465个小图标助力编程,展现可爱实用特色
- C#实现的分布式RMI远程方法调用技术
- THREE.js扩展集实验与技术研究
- 解决WINDOWS系统放大镜问题的下载工具
- FPGA/CPLD平台I2C从设备实现与测试案例
- TI DM6467 TSIF接口在Linux下的程序开发
- 大连现代人事管理系统ASP代码功能解读
- Android条码扫描器应用:快速识别各种码
- 点阵字库生成器V4.0:支持多语言编码及图片生成
