新手实战:零基础爬取香港律师信息
版权申诉
109 浏览量
更新于2024-06-19
收藏 2.39MB PDF 举报
"本篇文章标题为「爬虫入门实战(标价400的单子」,作者DaveCui在掘金平台的「爬虫方法论」专栏中分享了他如何通过实战案例帮助初学者理解和入门爬虫技术。文章的初衷是将他在工作中遇到的复杂问题和解决方案记录下来,并提供一个易于上手的实践环境,例如爬取一个缺乏反爬手段的网站——香港法律协会的律师信息,以此作为教学素材。
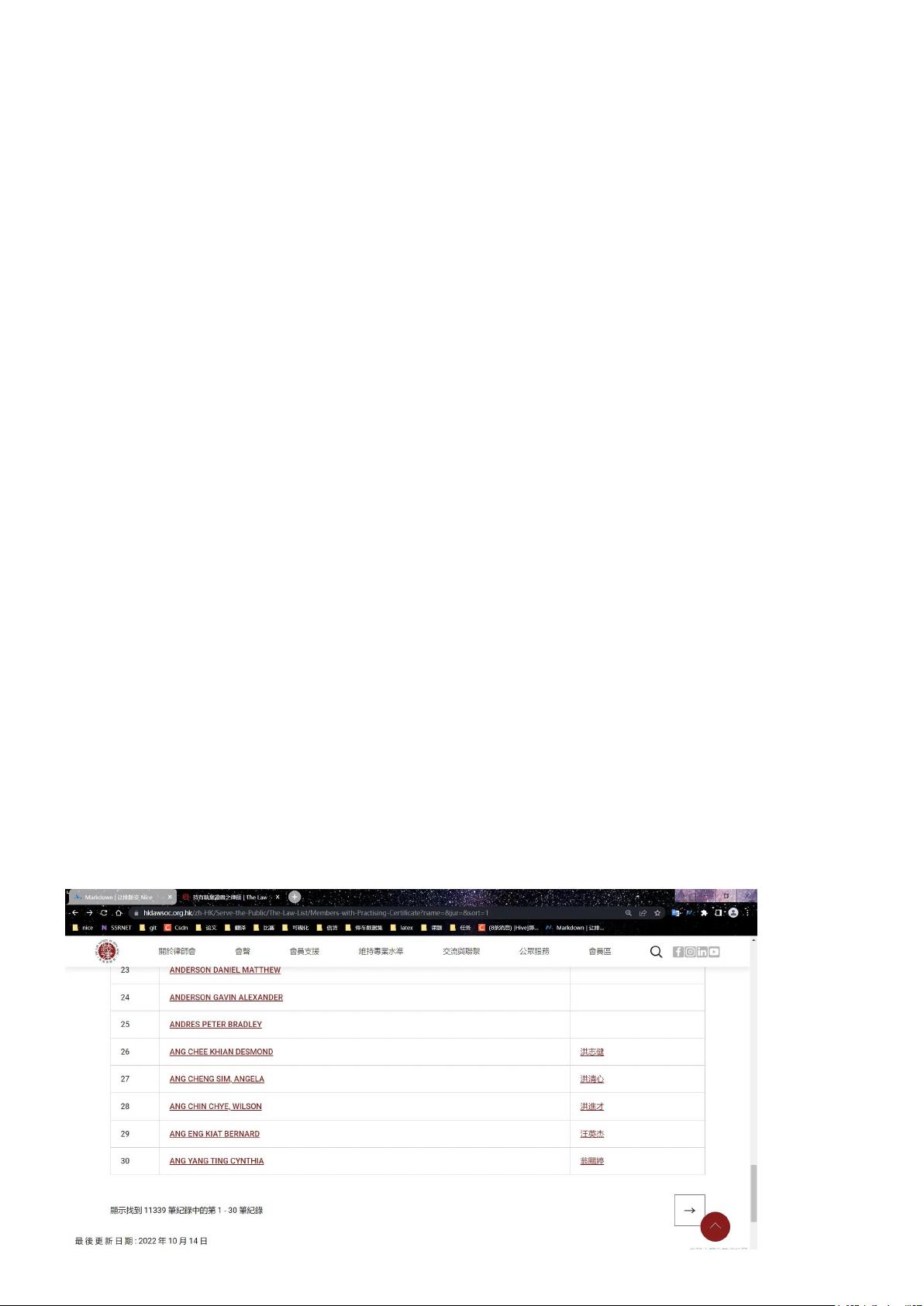
首先,作者计划分步进行:第一步是抓取所有律师的个人介绍链接,通过分析网页结构发现,每个页面有30条律师信息,且每页间通过`&pageIndex=`参数区分。他展示了前两页的链接结构,可以看出,页码的变化体现在`&pageIndex=`后面的数字。对于这样的网站,由于缺乏反爬措施,爬虫编写相对简单。
第二步是访问抓取到的链接,对每个律师的个人介绍进行进一步的数据抓取。这个过程包括解析HTML内容,找到包含关键信息的部分,比如商品名称、价格等。文章提到,虽然作者的爬虫技术并非专业出身,但足以处理这类初级项目,不过对于更高层次的职业发展,如使用Selenium进行自动化测试或者模拟器进行App爬虫,还有待提升。
此外,作者强调了Python在爬虫开发中的重要性,因为其丰富的第三方库和易用性。在实际操作中,他可能会介绍如何利用Python库如BeautifulSoup或Scrapy来处理网页解析和数据提取。他还承诺会分享自己的爬虫技巧,即使是“大巧不工”的方法,也能帮助读者建立扎实的基础。
这篇文章将引导读者经历一个从需求分析、网页结构解析、编码实现到最后分享经验的过程,旨在帮助新手快速入门爬虫技术,并为后续深入学习打下基础。"

这个是第一页。
剩余25页未读,继续阅读
2021-02-19 上传
2015-05-15 上传
2021-03-19 上传
275 浏览量
2022-01-09 上传

北极象
- 粉丝: 1w+
 我的内容管理
展开
我的内容管理
展开







最新资源
- AVR单片机C语言编程实战教程
- MATLAB实现π/4-QDPSK调制解调技术解析
- Rust开发微控制器USB设备端实验性框架介绍
- Report Builder 12.03汉化文件使用指南
- RG100E-AA U盘启动配置文件设置指南
- ASP客户关系管理系统的联系人报表功能解析
- DSPACK2.34:Delphi7控件的测试与应用
- Maven Web工程模板 nb-parent 评测
- ld-navigation:革新Web路由的数据驱动导航组件
- Helvetica Neue字体全系列免费下载指南
- stylelint插件:强化CSS属性值规则,提升代码规范性
- 掌握HTML5 & CSS3设计与开发的关键英文指南
- 开发仿Siri中文语音助理的Android源码解析
- Excel期末考试复习与习题集
- React自定义元素工具支持增强:react-ce-ubigeo示例
- MATLAB实现FIR数字滤波器程序及MFC界面应用
