

4 Introduction
1.2 An Illustrative Example
Before formal considerations in subsequent chapters, we show a simple illustra-
tive example in order to show a basic idea of how an agglomerative method and
c-means clustering algorithm work. Readers who already have basic knowledge
of cluster analysis may skip this section.
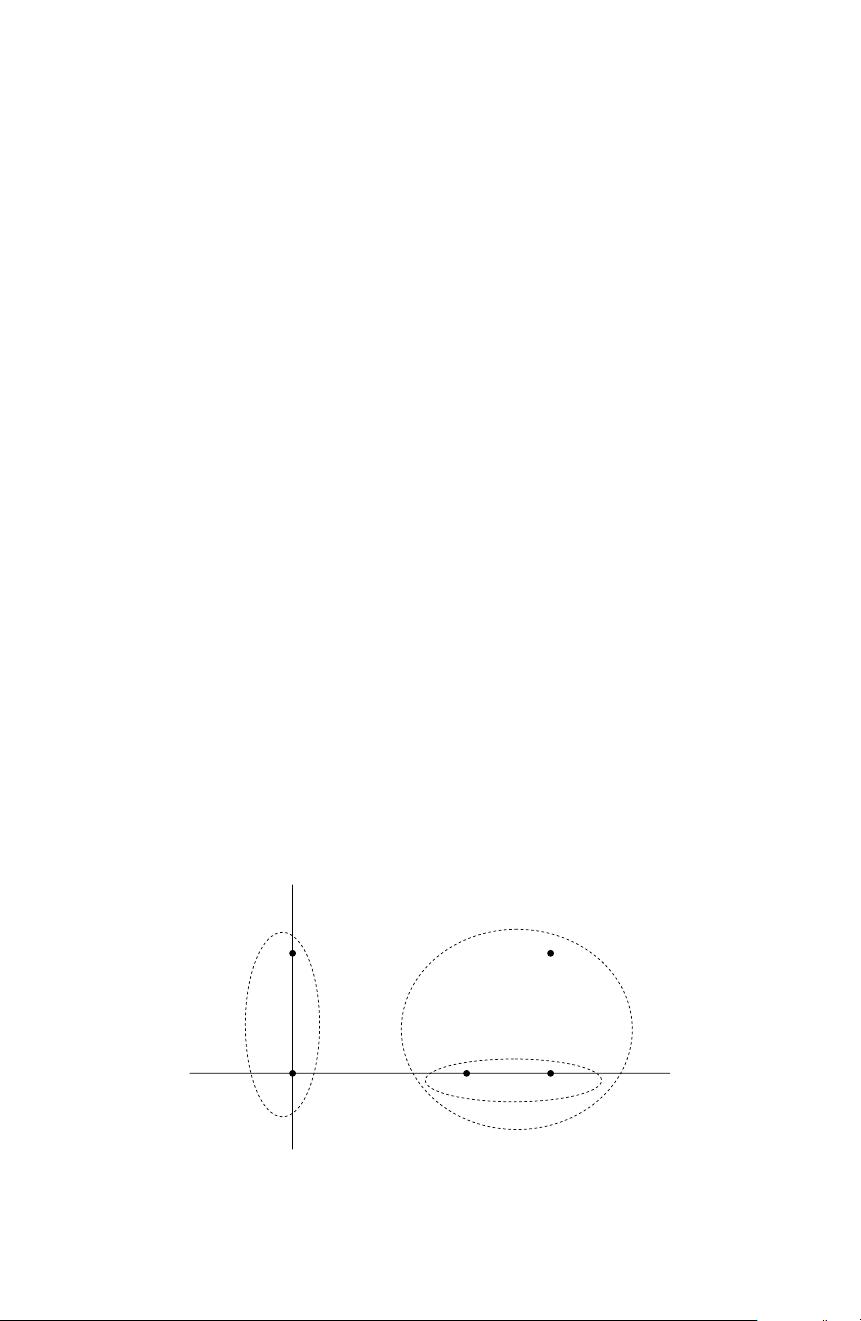
Example 1.1. Let us observe Figure 1.1 where five points are shown on a plane.
The coordinates are
x
1
=(0, 1.5), x
2
=(0, 0), x
3
=(2, 0), x
4
=(3, 0), x
5
=(3, 1.5).
We classify these five points using two best known methods: the single link [35]
in agglomerative hierarchical clustering, and the crisp c-means in the class of
nonhierarchical algorithms.
The Single Link
We describe the clustering process informally here; the formal definition is given
in Section 5.3.
An algorithm of agglomerative clustering starts from regarding each point as
a cluster. That is, G
i
= {x
i
}, i =1, 2,...,5. Then two clusters (points) of the
closest distance are merged into one cluster. Since x
3
and x
4
has the minimum
distance 1.0 among all distances for every pair of points, they are merged into
G
3
= {x
3
,x
4
}. After the merge, a distance between two clusters should be
defined. For clusters of single points like G
j
= {x
j
}, j =1, 2, the definition is
trivial:
d(G
1
,G
2
)=x
1
− x
2
,
where d(G
1
,G
2
) is the distance between the clusters and x
1
− x
2
is the Eu-
clidean distance between the two points. In contrast, the definition of d(G
3
,G
k
),
k =1, 2, 5 is nontrivial. Among possible choices of d(G
3
,G
k
)inSection5.3,the
x1 (0,1.5)
x2 (0,0)
x3 (2,0)
x4 (3,0)
x5 (3,1.5)
Fig. 1.1. An illustrative example of five points on the plane



剩余252页未读,继续阅读

wintau
- 粉丝: 0
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- zlib-1.2.12压缩包解析与技术要点
- 微信小程序滑动选项卡源码模版发布
- Unity虚拟人物唇同步插件Oculus Lipsync介绍
- Nginx 1.18.0版本WinSW自动安装与管理指南
- Java Swing和JDBC实现的ATM系统源码解析
- 掌握Spark Streaming与Maven集成的分布式大数据处理
- 深入学习推荐系统:教程、案例与项目实践
- Web开发者必备的取色工具软件介绍
- C语言实现李春葆数据结构实验程序
- 超市管理系统开发:asp+SQL Server 2005实战
- Redis伪集群搭建教程与实践
- 掌握网络活动细节:Wireshark v3.6.3网络嗅探工具详解
- 全面掌握美赛:建模、分析与编程实现教程
- Java图书馆系统完整项目源码及SQL文件解析
- PCtoLCD2002软件:高效图片和字符取模转换
- Java开发的体育赛事在线购票系统源码分析
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


