TensorRT实战指南:图像识别与自定义网络层
需积分: 5 57 浏览量
更新于2024-08-03
收藏 708KB PDF 举报
“TensorRT 的编程方法——图像识别.pdf,技术文档分享”
TensorRT是NVIDIA开发的一款高性能深度学习推理(Inference)优化和部署工具,特别适用于实时服务,如图像识别。此文档主要涵盖了TensorRT的基础回顾、插件(Plugin)的使用、基于SSD(Single Shot MultiBox Detector)的编程模型以及具体的实例展示。
**TensorRT回顾**
TensorRT的主要功能是优化和执行深度学习模型,提高推理速度并降低内存消耗。它支持多种神经网络架构,包括卷积神经网络(CNN)、循环神经网络(RNN)等,并且兼容多种框架的模型,如TensorFlow、Caffe、Keras等。TensorRT提供了C++和Python两种API供开发者使用,同时也包含了一系列示例代码,帮助开发者快速上手。
**TensorRT支持的网络层**
TensorRT支持多种常见的深度学习操作,包括但不限于卷积、池化、全连接、激活函数(如ReLU、Sigmoid、 TanH)、归一化、softmax等。开发者可以通过这些基础层构建复杂的深度学习模型。
**自定义网络层**
对于TensorRT不直接支持的网络层,开发者可以通过实现自定义层来扩展其功能。自定义层的实现涉及四个关键阶段:
1. `configureWithFormat`:配置层的输入和输出数据格式。
2. `Initialize`:初始化层的资源,如分配内存。
3. `enqueue`:在GPU上执行计算任务。
4. `terminate`:释放资源,结束层的生命周期。
此外,自定义层还需要实现三个重要方法:
1. `getNbOutputs`:返回层的输出数量。
2. `getOutputDimensions`:返回每个输出的维度信息。
3. `supportsFormat`:判断层是否支持特定的数据格式。
**TensorRT编程模型—SSD**
SSD是一种用于目标检测的深度学习模型,它结合了多尺度预测和先验框(Anchor)的概念。在TensorRT中,SSD的实现涉及几个关键组件:
1. **Preprocessor**:处理输入图像,如调整大小、归一化等。
2. **FeatureExtractor**:使用预训练的CNN提取特征。
3. **BoxPredictor**:预测每个先验框的偏移量和类别概率。
4. **GridAnchorGenerator**:生成不同尺度和比例的先验框。
5. **PostProcessor**:将预测结果转换为检测框和类别标签。
**TensorRT实例展示**
在TensorRT提供的`SampleUffSSD`示例中,它演示了如何加载一个预先训练好的SSD模型,并在TensorRT中进行推理。这个示例涵盖了模型加载、预处理、执行推理和后处理的完整流程,是理解和应用TensorRT进行图像识别的良好起点。
通过学习和实践这份文档,开发者可以深入理解TensorRT的工作原理,掌握如何利用TensorRT进行模型优化和部署,特别是在图像识别领域的应用。同时,文档中提供的链接指向了详细的使用指南和API参考,对于进一步的学习和开发具有很高的价值。
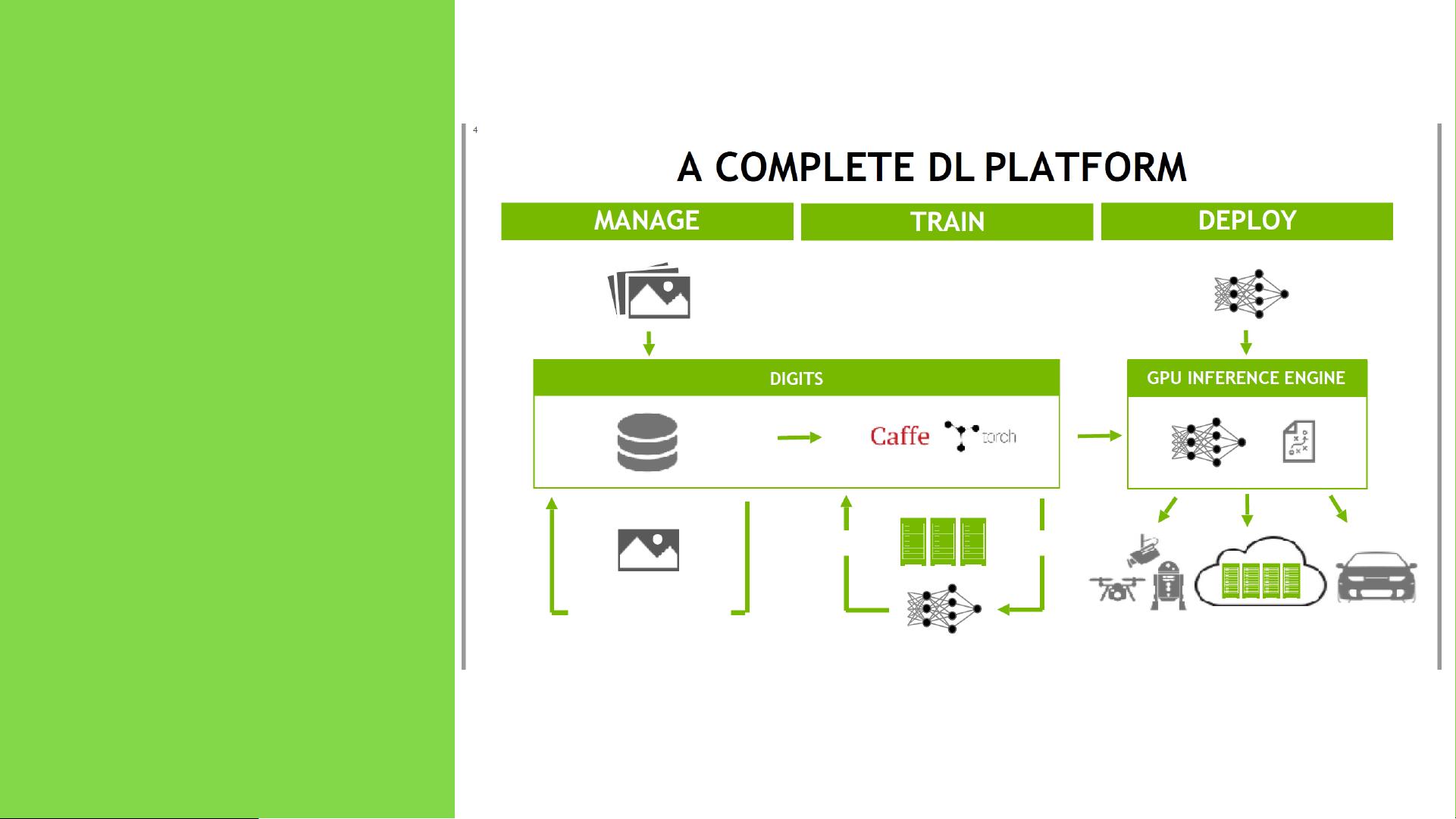
TensorRT 回顾
剩余13页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-07-21 上传
2023-07-21 上传
2023-06-04 上传
2024-08-24 上传
2023-03-16 上传
2024-04-13 上传
2023-06-07 上传

weixin_44079197
- 粉丝: 1677
- 资源: 598
 我的内容管理
展开
我的内容管理
展开







最新资源
- css背景颜色透明背景图片切换效果
- 百度知道批量回复链接-易语言.zip
- projetocaver
- :graduation_cap:FlutterTodoList教程-JavaScript开发
- jhipsterSampleApplication
- 创业计划书-2019年整理--电动车商业创业计划书
- weixin059在线投稿系统+ssm(源码+部署说明+演示视频+源码介绍+lw).rar
- matlab开发-WilcoxonRanksumtestatandboxplotsfornescompoundsetcinhea
- sinhalakavi:僧伽罗诗
- 基于HTML实现的时尚黑色透明手机响应式商业整站(含HTML源代码+使用说明+毕业设计).zip
- withExEditor:使用外部编辑器查看源代码,查看选择内容和编辑文本
- 创业计划书-某啤酒厂排污可研
- bootstrap-js-context-menu.zip
- 将您的REST API转换为GraphQL-代理服务器,可通过GraphQL DSL,高性能嵌套子代,变异,输入类型等将请求从GraphQL传递到REST。-JavaScript开发
- neo4jlog.zip
- smartappandroid:POC疲劳android应用
