VLLM推理框架:内存优化与高效解码技术
 已收录资源合集
已收录资源合集
需积分: 0 137 浏览量
更新于2024-08-03
收藏 1.29MB PDF 举报
VLLM(Very Large Language Model)是一个专门针对大规模语言模型推理设计的框架,旨在解决现有语言模型如自回归模型在处理大规模输入时面临的显存瓶颈问题。VLLM的核心创新之一是采用了PagedAttention技术,这是一种受操作系统虚拟内存和分页概念启发的方法。传统的自回归模型(如Transformer)会将所有keys和values(KVcache)存储在连续的显存中,这导致了显存浪费。PagedAttention通过将KVcache划分为固定大小的块,实现了非连续内存空间中的连续数据管理,显著降低了显存浪费,将内存利用率提升到接近理论最优,从而支持更大的batch size,提高GPU的并行计算效率。
在VLLM中,LLMbatching是一种特别的技术,它允许在一次推理过程中处理多个连续或非连续的prompt输入,提高了吞吐量。然而,这种批量处理方法并非简单地堆叠请求,而是具有迭代性,因为部分请求可能会提前完成并释放资源,可能导致后续请求需要重新调整资源分配。因此,LLMbatching的实施需要考虑请求的顺序和依赖性,以确保高效利用硬件资源。
尽管VLLM在性能上表现出色,比HuggingFace的Transformers和Text Generation Inference(TGI)有显著优势,但在使用上存在一些限制。首先,它对某些预训练模型的适配器(如LoRA和QLoRA)支持不足,这意味着用户可能需要额外的工作来将现有的模型架构与VLLM兼容。其次,VLLM目前缺乏权重量化功能,这可能会影响模型在资源受限环境下的部署效率。
安装VLLM通常涉及到下载GitHub仓库的代码,遵循官方文档中的指南进行配置和编译。离线推理是在本地环境中预先计算模型输出,适用于资源充足的环境。而在线服务的启动则涉及到部署模型到服务器,以供实时请求处理,同时需要考虑如何高效地启动和管理服务,包括内存管理和请求调度。
VLLM是为大规模语言模型推理优化的框架,通过PagedAttention和LLMbatching技术提供高效的内存管理和并行计算,但在使用时需注意其对特定模型适配和权重量化的局限。为了充分利用VLLM的优势,开发者需要根据具体需求和场景选择合适的配置和策略。
3
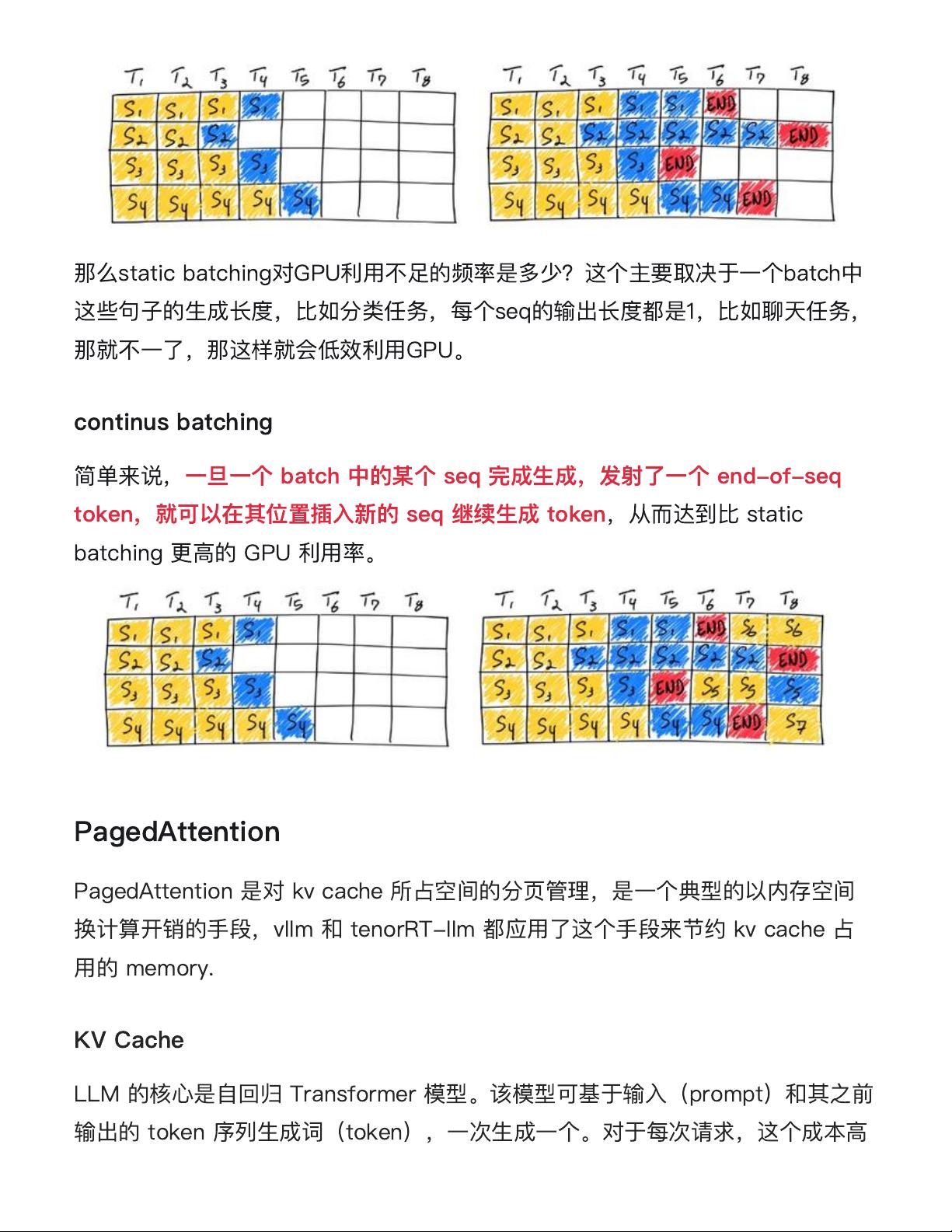
那
么
static batching
对
GPU
利
⽤
不
⾜
的
频
率
是
多
少
?
这
个
主
要
取
决
于
⼀个
batch
中
这
些
句
⼦
的
⽣
成
⻓
度
,
⽐
如
分
类
任
务
,
每
个
seq
的
输
出
⻓
度
都
是
1
,
⽐
如
聊
天
任
务
,
那
就
不⼀
了
,
那这
样
就
会低
效
利
⽤
GPU
。
简
单
来
说
,
⼀
旦
⼀个
batch
中
的
某
个
seq
完
成
⽣
成
,
发
射
了
⼀个
end-of-seq
token
,
就
可
以
在
其
位
置
插
⼊
新
的
seq
继续
⽣
成
token
,
从
⽽
达
到
⽐
static
batching
更
⾼
的
GPU
利
⽤率
。
PagedAttention
是
对
kv cache
所
占
空
间
的
分
⻚
管
理
,
是
⼀个
典
型
的
以
内
存
空
间
换
计
算
开
销
的
⼿
段
,
vllm
和
tenorRT-llm
都
应
⽤
了
这
个
⼿
段
来
节
约
kv cache
占
⽤
的
memory.
LLM
的
核
⼼
是
⾃
回
归
Transformer
模
型
。
该
模
型
可
基
于
输
⼊
(
prompt
)
和
其
之
前
输
出
的
token
序
列
⽣
成
词
(
token
),⼀
次
⽣
成
⼀个
。
对
于
每次
请
求
,
这
个
成
本
⾼
continus batching
PagedAttention
KV Cache
剩余11页未读,继续阅读
2018-07-31 上传
2024-04-22 上传
2024-03-07 上传
2023-08-05 上传
2024-05-17 上传
2024-05-23 上传
2024-06-29 上传
点击了解资源详情
2024-05-08 上传

dreampai
- 粉丝: 4
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新代数控API接口实现CNC数据采集技术解析
- Java版Window任务管理器的设计与实现
- 响应式网页模板及前端源码合集:HTML、CSS、JS与H5
- 可爱贪吃蛇动画特效的Canvas实现教程
- 微信小程序婚礼邀请函教程
- SOCR UCLA WebGis修改:整合世界银行数据
- BUPT计网课程设计:实现具有中继转发功能的DNS服务器
- C# Winform记事本工具开发教程与功能介绍
- 移动端自适应H5网页模板与前端源码包
- Logadm日志管理工具:创建与删除日志条目的详细指南
- 双日记微信小程序开源项目-百度地图集成
- ThreeJS天空盒素材集锦 35+ 优质效果
- 百度地图Java源码深度解析:GoogleDapper中文翻译与应用
- Linux系统调查工具:BashScripts脚本集合
- Kubernetes v1.20 完整二进制安装指南与脚本
- 百度地图开发java源码-KSYMediaPlayerKit_Android库更新与使用说明
