Flink与Spark:数据处理引擎对比分析
需积分: 5 130 浏览量
更新于2024-06-16
收藏 1.48MB DOCX 举报
"这篇文章主要介绍了Apache Flink,一个用于处理有界和无界数据流的分布式计算引擎,以及它与Spark的区别。Flink的核心理念在于流处理,它将批处理视为特殊的流处理情况,提供了对无界和有界数据流的高效处理能力。"
Apache Flink是一个强大的大数据处理工具,其设计目标是在各种集群环境中运行,支持大规模内存级计算。Flink的核心特性之一是它的数据处理模型,它可以处理两种类型的数据流:有界数据流和无界数据流。
有界数据流(Bounded DataStream)是有限的数据集合,有明确的起点和终点,通常对应于传统的批处理任务。Flink处理有界数据流时,可以获取所有数据并进行完整的处理,这使得批处理任务在Flink中得以实现。
相比之下,无界数据流(Unbounded DataStream)是持续不断的数据流,没有明显的结束点。无界数据流的例子包括实时事件流或传感器数据流。由于数据的持续性,Flink必须对这些数据进行连续处理,即时处理新到达的数据,以确保结果的及时性。在处理无界数据流时,Flink提供了处理顺序和容错机制,保证了数据处理的正确性。
Flink与Spark在数据处理架构上有显著差异。Spark最初是为批处理设计,然后扩展到流处理,其Spark Streaming采用微批次处理方式,实际上是一种近实时处理。这种方式在处理延迟敏感的流任务时可能不如Flink。而Flink则是以流处理为中心,其流处理能力更强大,尤其在低延迟场景下表现出色。
另一方面,Spark的微批次处理方式在处理大量数据时表现出高吞吐量,且其丰富的生态和易用的API使其在批处理领域占有优势。然而,Flink在流处理的低延迟性能和对状态管理的支持上更胜一筹,适合实时分析和复杂事件处理等场景。
Flink和Spark各有特色,适用于不同的大数据处理需求。Flink的流处理设计理念使其在实时计算领域具有竞争力,而Spark则在批处理和综合生态系统方面展现出强大的能力。选择哪种工具取决于具体的应用场景和业务需求。

38
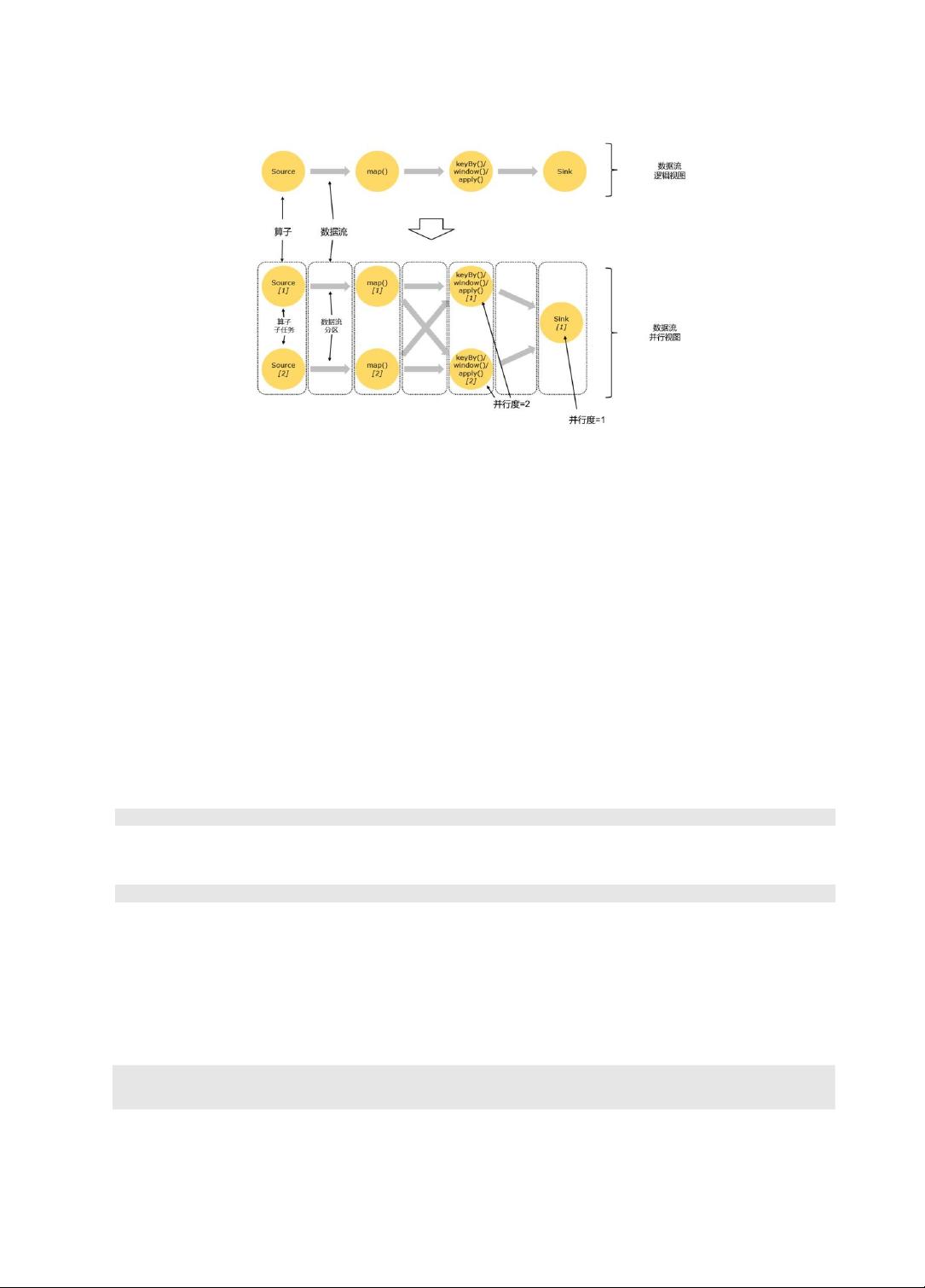
4.1.3
并行度(Parallelism)
1. 并行子任务和并行度
把一个算子操作,“复制”多份到多个节点,数据来了之后就可以到其中任意一个执行。这样一来,
一个算子操作就被拆分成了多个并行的“子任务”( subtasks),再将它们分发到不同节点,就真正
实现了并行计算。
在Flink 执行过程中,每一个算子(operator)可以包含一个或多个子任务(operator subtask),这些子
任务在不同的线程、不同的物理机或不同的容器中完全独立地执行。
剩余40页未读,继续阅读
1107 浏览量
184 浏览量
2021-03-25 上传
2025-03-12 上传
2025-03-12 上传

龙骨
- 粉丝: 161
 我的内容管理
展开
我的内容管理
展开







最新资源
- AVR单片机C语言编程实战教程
- MATLAB实现π/4-QDPSK调制解调技术解析
- Rust开发微控制器USB设备端实验性框架介绍
- Report Builder 12.03汉化文件使用指南
- RG100E-AA U盘启动配置文件设置指南
- ASP客户关系管理系统的联系人报表功能解析
- DSPACK2.34:Delphi7控件的测试与应用
- Maven Web工程模板 nb-parent 评测
- ld-navigation:革新Web路由的数据驱动导航组件
- Helvetica Neue字体全系列免费下载指南
- stylelint插件:强化CSS属性值规则,提升代码规范性
- 掌握HTML5 & CSS3设计与开发的关键英文指南
- 开发仿Siri中文语音助理的Android源码解析
- Excel期末考试复习与习题集
- React自定义元素工具支持增强:react-ce-ubigeo示例
- MATLAB实现FIR数字滤波器程序及MFC界面应用
