SDTMIG学习:数据集结构与标准解析
版权申诉
93 浏览量
更新于2024-07-12
1
收藏 1.03MB DOC 举报
"SDTMIG学习总结,主要涵盖了SDTM数据集的特点、结构以及CDISC标准的重要性和应用。"
SDTM(Standard for the Exchange of Non-clinical Data,非临床数据交换标准)是一种由CDISC( Clinical Data Interchange Standards Consortium,临床数据交换标准联盟)提出的临床试验数据标准,用于标准化临床试验数据的结构和内容,以便于数据的交换和审查。SDTMIG(SDTM Implementation Guide)是SDTM标准的具体实施指南,它提供了如何将原始临床试验数据转化为SDTM格式的详细说明。
在学习SDTMIG的过程中,我们注意到SDTM数据集与传统数据集的主要区别在于以下几个方面:
1. 数据集的组织方式:SDTM数据集将数据根据变量的来源和主题划分到不同的域中,每个域都有特定的两字符代码标识,如AE(Adverse Event)代表不良事件。这与一般数据集中可能只有一个或少数几个数据集的情况不同。
2. 记录结构:SDTM采用个人记录与事件记录的方式,对于每个受试者,每个事件、每次用药或每次不良反应都单独记录,导致记录条数增多,但变量数量减少。这种设计便于追踪和分析每个受试者的详细事件历史。
3. 关联数据集:由于变量之间的关联性,SDTM还包括了关联数据集,以处理复杂的变量关系,如时间序列数据。
4. 记录唯一性的确定:CDISC强调如何确保记录的唯一性,特别是在多阶段、多时间点、多剂量的试验中,通常需要通过三个变量来区分不同的记录。
5. 元数据的应用:元数据是描述数据的数据,包括数据项集合、语义定义、规则和语法定义。元数据标准的使用有助于提高数据质量,促进数据的规范化和标准化,增强数据交流的效率。
6. 变量标准化:SDTMIG规定了变量名称和取值的标准化,这使得数据更具可读性和可比性,便于监管机构如FDA进行清晰、一致的审查。
7. 域和变量的选择:并非所有的SDTM域和变量都必须在每个研究中使用,实际应用时需根据研究的具体内容和需求来选择适用的领域和变量。
例如,CM域(Concomitant and Prior Medication)用于记录受试者的伴随用药和既往用药信息,这是理解试验期间患者状况和药物相互作用的关键部分。每个域都有其特定的变量和结构,如CM域可能包含药物名称、剂量、给药途径等信息。
SDTMIG的学习不仅涉及到数据组织和结构化,还包括了数据标准化和元数据管理,这些对于临床试验数据的处理和分析至关重要。理解和应用SDTMIG能够提升数据的质量,确保临床试验数据的一致性和可比性,从而支持更有效的监管决策。
【精品文档】
缺失值:单个数据项缺失以空来表示,如果有—STAT 变量和—REASND 变量
则还需在—STAT 中录入 NOT DONE,在—REASND 中录入原因。
——分类变量: CAT ——、 SCAT ——、 GRPID ——、 SPID ——、 REFID
——CAT ——与 SCAT 在采集之前就已知,是固有属性,用于受试者之间分组
——GRPID 通常在数据采集之后由申办者指定,受试者之内分组数据
——对各受试者之间具有相同值的数据用 CAT ——与 SCAT,而对受试者之间
——具有不同值时用 GRPID
自由文本:其他,请说明。P36 页
一个变量的多个取值
受控术语:一个星号*或两个星号**代表相应的变量应该被填入意义明确的一组
数值(受控术语)。一个星号表示受控术语来自申办者自定义的值,两个星号
表示来自外部已出版的数据源。
建议受控术语应大写,除了本来就是小写的或计量单位
放入
不能用数字代码
每个通用观察域必须要有一个主题变量,一个时间变量
——主题变量:事件类 TERM ——,干预类 TRT ——,发现类 TEST;必须有受
控术语
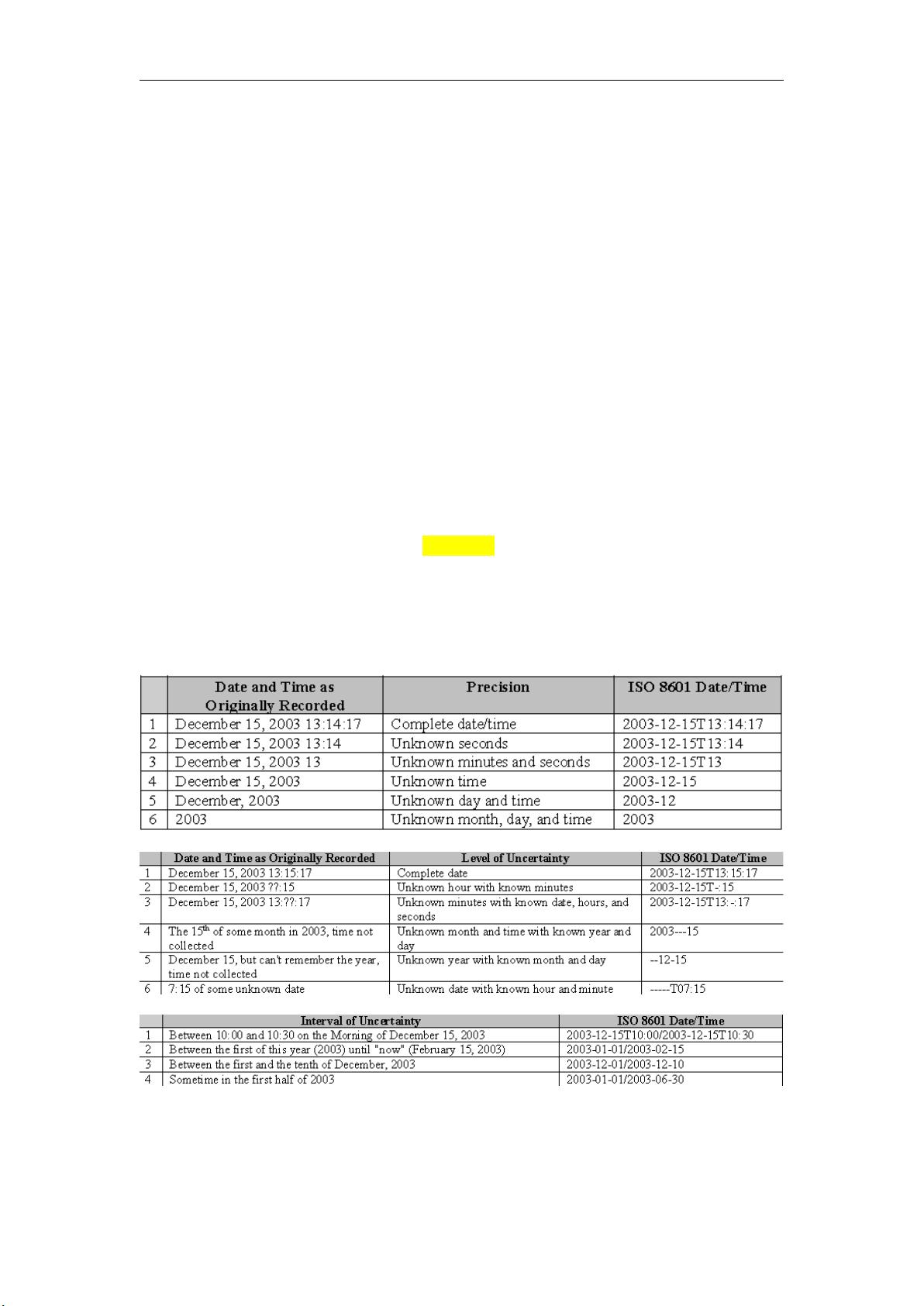
时间变量:国际标准日期时间格式 ISO 8601
YYYY—MM—DDThh:mm:ss
— —年 月 日 T 小时:分钟:秒
0 不能省略,不能有空格。
——时间变量的片段名为 DTC。
时间成分缺失:恰当右缺失
中间缺失补充单个连字符。
不确定时间的表示
——时间间隔变量 DUR
YYYY—MM—DDThh:mm:ss/ YYYY—MM—DDThh:mm:ss
或者 PnYnMnDTnHnMnS 或 PnW
确定开始时间和间隔
【精品文档】
剩余28页未读,继续阅读

goodbyeone12
- 粉丝: 0
- 资源: 6万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- CrystalDiskMark8
- 十九种不良生活习惯PPT
- Android-SecretCodes:Secret Codes是一个开源应用程序,可让您浏览Android手机的隐藏代码-Android application source code
- data-utils:围绕数据解析和转换的辅助函数集合
- bric_sheets_react
- yeelight:用于通过局域网控制yeeelight的nodeJS客户端库
- leetcode答案-daily_coding_problems:存储库包含我对DailyCodingProblem和InterviewCak
- 登录
- WechatApp-cinema:基于云开发的电影院订票微信小程序
- 资产负债管理
- STBlueMS_Android:“ ST BLE传感器” Android应用程序源代码-Android application source code
- crack:从Merb和Rails中复制的真正简单的JSON和XML解析
- cloud-dapr-demo:Dapr运行时演示和云提供商的无缝集成
- sherlock:夏洛克
- 熵权法 MATLAB实现,熵权法matlab实现+层次分析法,matlab源码.zip
- 组织设计与权力配置
