SQL2005分区表技术详解与优势
下载需积分: 9 | DOC格式 | 518KB |
更新于2024-09-21
| 200 浏览量 | 举报
"这篇文档详细介绍了SQL Server 2005中的分区表功能,包括分区表的优势、如何创建分区函数和分区方案,以及创建分区表和聚集分区索引的步骤。"
在SQL Server 2005中,分区表是一个重要的数据库管理工具,尤其对于处理大量数据的企业级应用而言,它提供了高效的数据管理和查询性能。分区表通过将一个大表分成多个逻辑部分,每个部分称为分区,基于分区键的值进行划分。这使得管理大规模数据变得更为便捷,同时也提高了查询效率。
分区表的主要优点如下:
1. 提高数据可用性:由于每个分区是独立的,查询优化器可以仅访问与查询相关的分区,从而减少了不必要的数据访问,提升了响应速度。
2. 减轻管理员的维护负担:大型表的备份、恢复和数据清理可以通过分区进行,避免了对整个表的操作,降低了复杂性和时间成本。
3. 改善查询性能:分区消除策略允许查询优化器忽略与查询无关的分区,提高查询速度。同时,支持并行操作,如并行全表扫描和并行索引区间扫描,进一步提升了性能。
4. 减少资源竞争:在多用户环境中,分区可以分散I/O负载,降低不同操作间的资源竞争,从而提升系统整体性能。
创建分区表的过程通常包括以下步骤:
1. 创建文件组和物理文件:文件组是存储分区数据的容器,物理文件则实际保存数据。文件组和文件的创建可以手动完成,也可以通过脚本自动化。
2. 定义分区函数:分区函数定义了如何根据特定列的值(如日期范围、值列表或散列函数)来分配数据到不同的分区。例如,`MineDateRange`函数可能将订单日期按年份划分。
3. 创建分区方案:分区方案定义了分区函数如何映射到文件组。在示例中,`Mine_Orders`方案将不同年份的订单数据分配到对应的文件组。
4. 创建分区表:在创建表时指定分区方案,例如,`OrdersTest`表通过`OrderDate`列使用`Mine_Orders`方案进行分区。
5. 创建聚集分区索引:为了进一步优化查询性能,可以在分区列上创建聚集索引,如`IXC_OrdersTest`,这样可以加速按`OrderDate`排序的查询。
最后,可以通过插入数据到分区表,测试并验证分区功能是否正常工作。在给出的示例中,数据被插入到`OrdersTest`表中,包含了`OrderID`、`CustomerID`、`EmployeeID`和`OrderDate`等字段。
总结来说,SQL Server 2005的分区表功能是应对大数据场景的有效手段,通过合理设计和利用分区,可以显著提高数据管理的效率和查询性能。
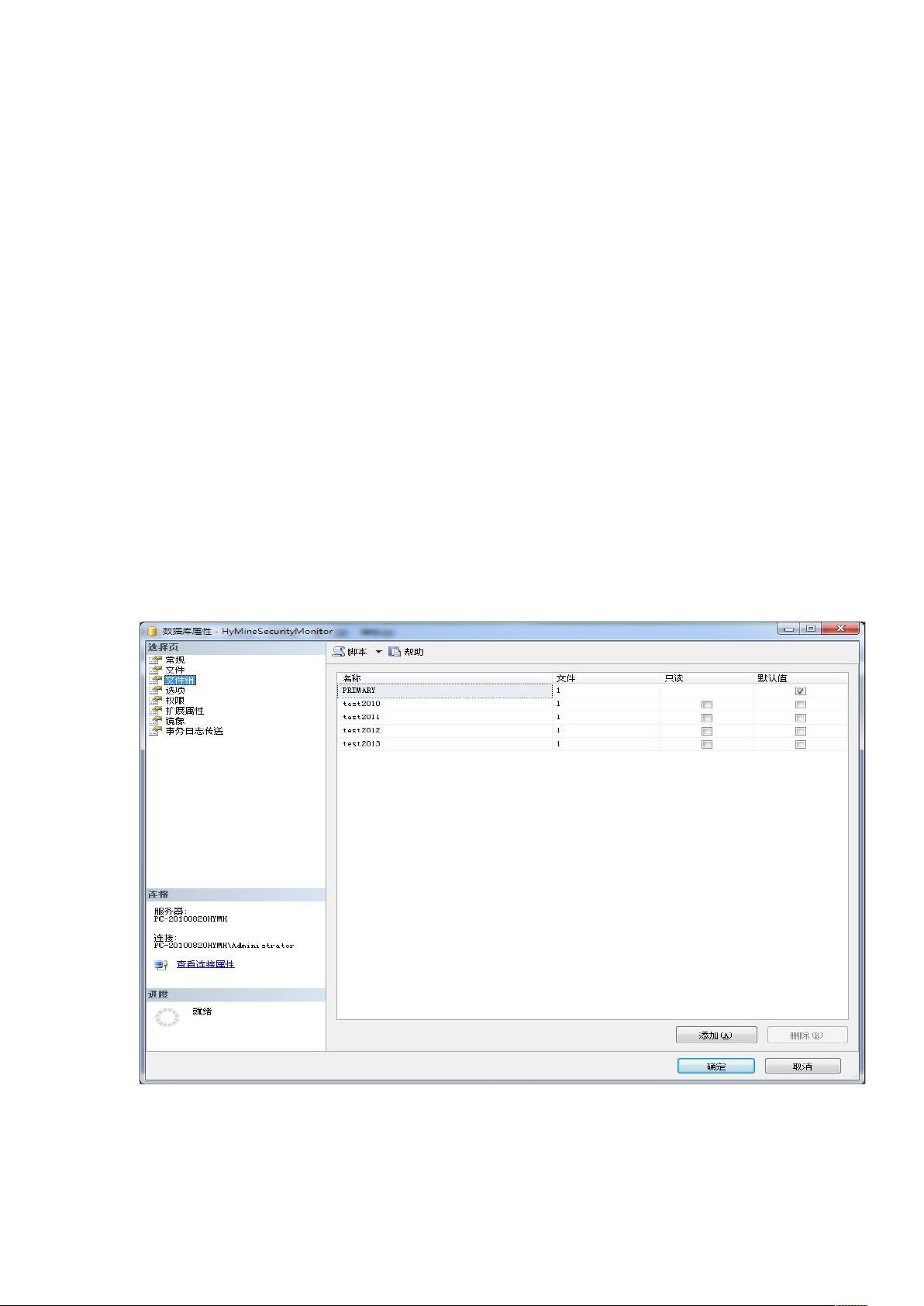
SQL2005 分区表
分区表有利于管理海量数据的表和索引,在分区中引入了一个分区键的概念,分区键用
于根据某个区间值,特定值列表或散列函数执行数据的聚集.
使用分区表有如下好处:
1. 提高数据的高用性:可用性的提高源自每个分区的独立性.优化器知道这种分区机
制,会相应的从查询计划中除去未引用的分区.
2. 减轻管理员负担.
3. 改善某些查询性能,在只读查询的性能方面,分区对两类操作起作用.
分区消除:处理查询时,不考虑某些分区.
并行操作:并行全表扫描和并行索引区间扫描.
4. 减少资源竞争.
脚本:
--首先手工创建文件分组、物理文件;脚本方式创建后边介绍
下载后可阅读完整内容,剩余5页未读,立即下载
相关推荐





奋斗中23132142314243
- 粉丝: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- C#实现自定义尺寸条形码和二维码生成工具
- Bootthink多系统引导程序成功安装经验分享
- 朗读女中文朗读器,智能语音朗读体验
- Jupyter Notebook项目培训教程
- JDK8无限强度权限策略文件8下载指南
- Navicat for MySQL工具压缩包介绍
- Spring和Quartz集成教程:定时任务解决方案
- 2013百度百科史记全屏效果的fullPage实现
- MATLAB开发电磁转矩电机瞬态响应研究
- 安卓系统短信问题解决方案:使用BlurEmailEngine修复
- 不同版本Android系统的Xposed框架安装指南
- JavaScript项目实验:模拟骰子与颜色转换器
- 封装高效滑动Tab动画技术解析
- 粒子群优化算法在Matlab中的开发与应用
- 网页图书翻页效果实现与turnjs4插件应用
- JSW: 一种新型的JavaScript语法,支持Coffeescript风格
