深度学习分布式训练解析:TensorFlow与并行策略
版权申诉
67 浏览量
更新于2024-07-07
收藏 3.19MB PDF 举报
"该资源是关于人工智能专题的深度学习中分布式训练的教程,主要探讨了在AI系统背景下如何优化和实施分布式训练策略。"
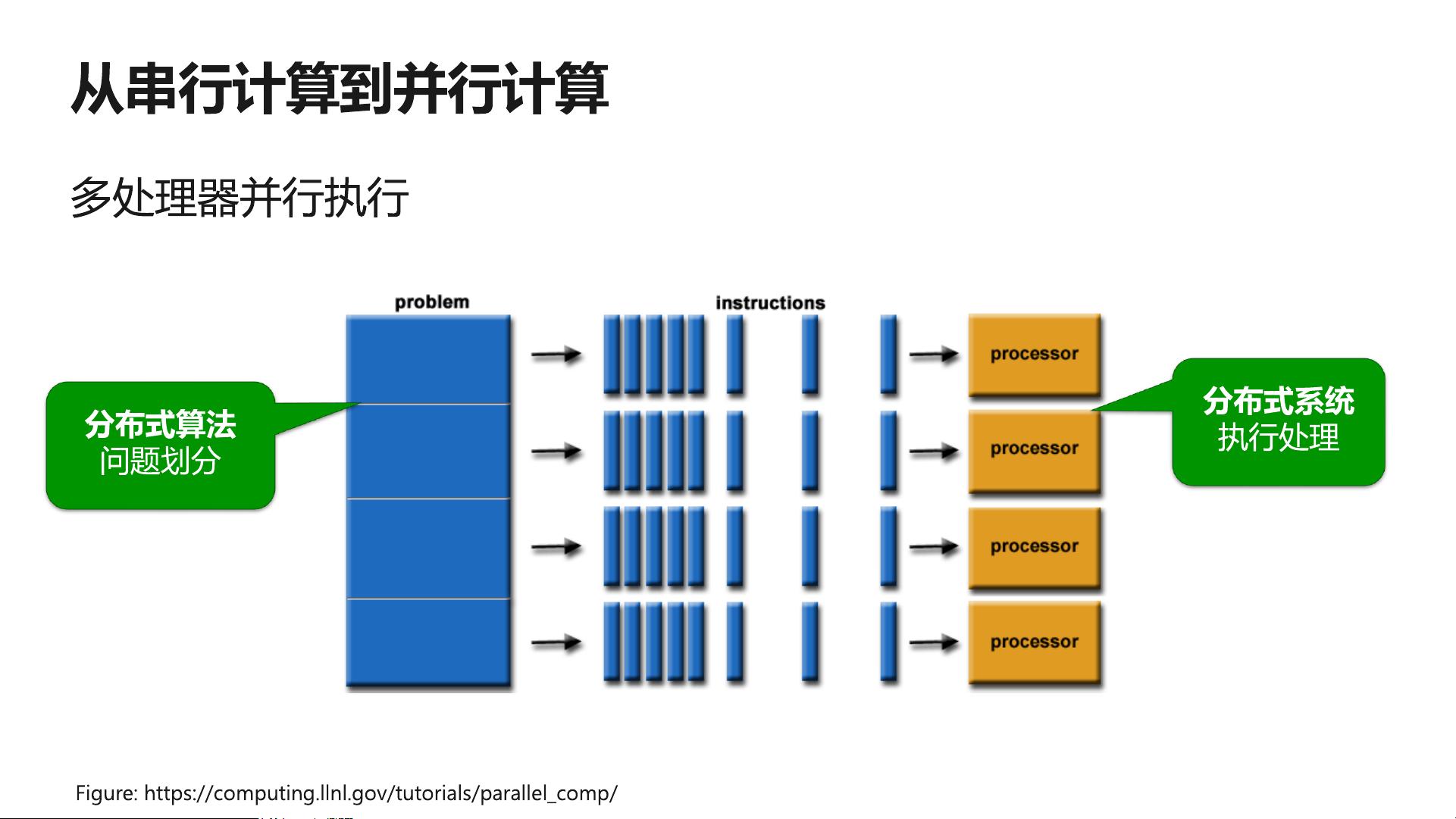
在深度学习领域,模型的复杂性和数据量的增大使得单个设备的计算能力往往不足以高效地进行训练。分布式训练成为了解决这一问题的关键技术。分布式训练允许我们在多台机器或多个处理器上同时进行模型训练,从而大幅提高训练速度和效率。本资料中提到了两种主要的并行策略:数据并行和模型并行。
1. 数据并行:数据并行策略是通过将大型数据集分割成多个小批次,然后在不同的计算节点上并行地执行这些批次的前向传播和反向传播过程。每个节点处理一部分数据,然后汇总梯度以更新模型参数。这种方式可以有效地利用多核CPU或GPU的计算能力,尤其在处理大量数据时效果显著。
2. 模型并行:对于非常大的模型,如含有大量参数的深度神经网络,模型并行策略则更为合适。在这种策略中,模型的不同部分被分配到不同的计算节点上,节点之间通过通信协调执行。这使得大型模型可以在分布式环境中被分解并行处理,避免了单个设备内存不足的问题。
除了上述两种并行策略,还有一种组合并行,它是数据并行和模型并行的混合,根据具体场景灵活组合,以达到最优的训练效果。例如,可以同时对模型的不同层进行数据并行,或者在不同设备间分割不同的模型块,实现计算资源的最大化利用。
文件中还提及了TensorFlow的Data-Flow Graph(数据流图)概念。在TensorFlow中,计算过程被表示为一个有向无环图(DAG),其中节点代表操作(operators),边代表数据流。这种表示方式使得TensorFlow能够有效地支持并行计算,因为图的不同部分可以独立执行,只要它们所需的输入数据可用。
此外,随着硬件的进步,如摩尔定律所示,计算能力的提升也对分布式训练产生了影响。尽管硬件性能不断提升,但在实际应用中,如何有效地分配和利用这些资源仍然是一个挑战。因此,理解并优化分布式训练的策略和技术,比如梯度同步、异步更新以及如何平衡计算负载,是提升深度学习效率的关键。
总结来说,本资料深入探讨了深度学习中的分布式训练方法,包括数据并行、模型并行和组合并行,以及如何在TensorFlow框架下实现这些策略。对于希望在人工智能领域,特别是深度学习方向进行分布式训练优化的开发者和研究人员来说,这是一份非常有价值的参考资料。
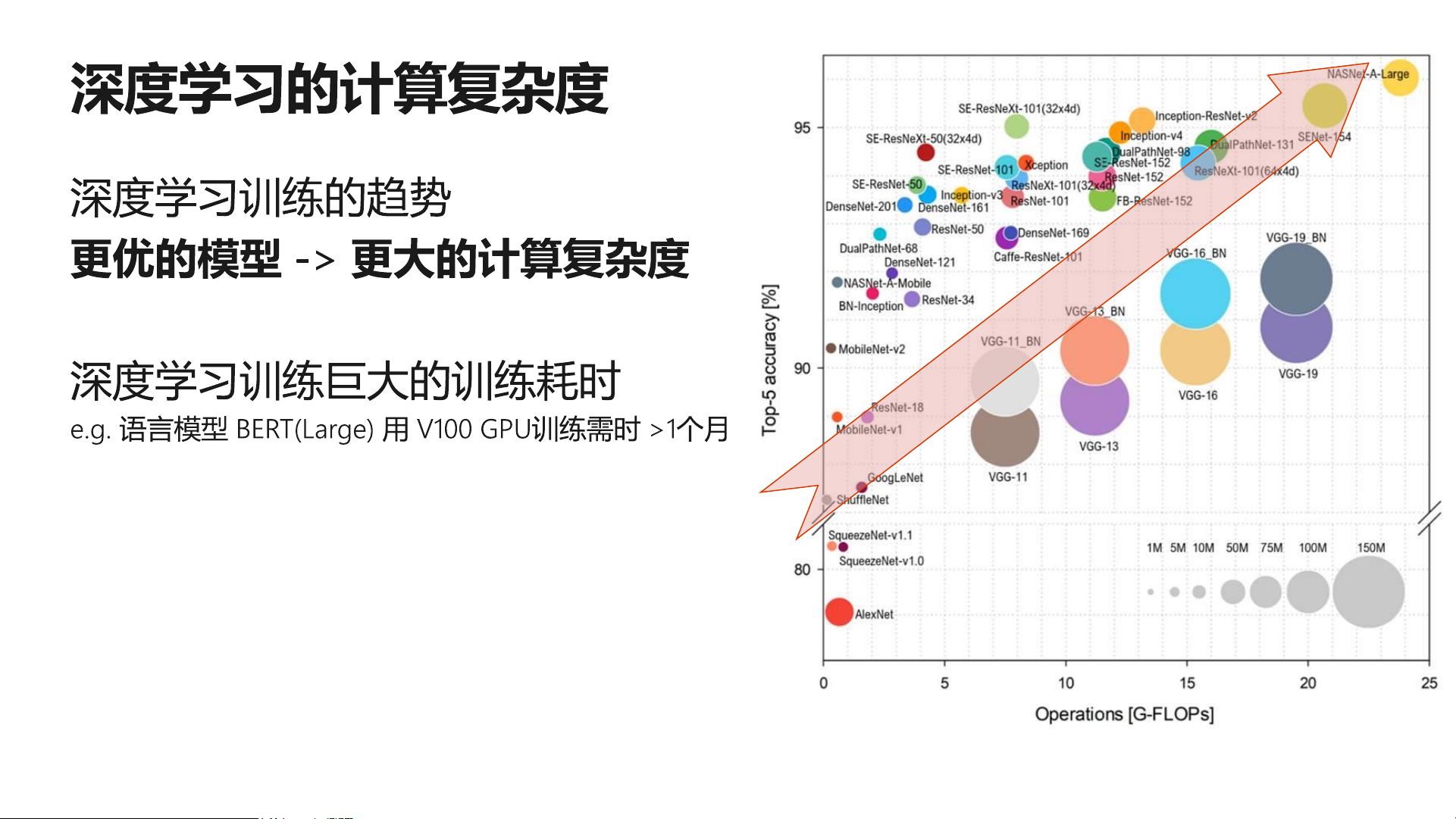
Benchmark Analysis of Representative Deep Neural Network Architectures
https://arxiv.org/pdf/1810.00736.pdf
Top-5 accuracy vs. computational complexity (single forward pass)
剩余31页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-12-14 上传
2021-08-30 上传
2021-08-08 上传
2021-04-07 上传
2019-09-07 上传
2024-04-14 上传

mugui3
- 粉丝: 0
- 资源: 811
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深井潜水泵电缆线接头的密封.rar
- 风险评估方案 和详细评估方法
- stevenjpr
- Accuinsight-1.0.17-py2.py3-none-any.whl.zip
- mipaka
- 网址模板
- WebAppDemo.zip
- Collumned NPR-crx插件
- Add to uStart (by uStart)-crx插件
- Gamers-Systems:所有游戏玩家的应用
- quickcheck:R 的随机测试
- 工作库:由学生完成的项目,为隆德大学LTH的ETSF20课程
- tour-mobile
- Feedly Subscriber-crx插件
- misc
- multiplayer_snake_game
