编辑器魔法令牌:多模态对象再识别中的多样化特征选择
需积分: 0 158 浏览量
更新于2024-08-03
1
收藏 11.05MB PDF 举报
【标题】"CVPR论文:EDITORMagic Tokens:多模态对象再识别中的多样化特征选择"
【描述提炼】:该论文《EDITORMagic Tokens Select Diverse Tokens for Multi-modal Object Re-Identification》关注于解决单模态对象再识别(ReID)在复杂视觉场景中保持稳健性的挑战。与之相比,多模态对象ReID利用不同模态之间的互补信息,显示出在实际应用中巨大的潜力。然而,现有的方法往往容易受到无关背景的影响,并且通常忽视了模态间的差距。
【关键知识点】:
1. **问题背景**:论文研究的问题焦点在于如何在多模态(如视觉、语音或深度信息)融合的背景下提升对象识别的鲁棒性,特别是在处理复杂视觉环境时。
2. **编辑器(EDITOR)框架**:作者提出了一种新颖的学习框架,名为EDITORMagic Tokens,其目标是通过视觉Transformer来提取并选择多样化的特征。这表明该方法着重于特征选择策略,以减少无关背景干扰。
3. **Token选择**:Editor框架的核心在于如何有效地从视觉Transformer中挑选出能反映对象关键特性的“魔法”(Magic)令牌,这些令牌具有较高的模态间一致性,能够跨越模态差异进行有效的跨模态匹配。
4. **克服挑战**:论文强调了前人方法的局限,即对背景噪音的敏感性和模态转换的不充分处理。Editor通过设计适应性强的模型,旨在增强对多模态数据的有效处理,提高识别准确性和鲁棒性。
5. **研究贡献**:主要贡献包括开发了一种创新的模型架构,以及一种有效的特征选择机制,这可能有助于提升多模态对象再识别系统的性能,使其在实际应用中更加实用。
6. **作者与联系信息**:研究团队来自大连理工大学和安徽大学,作者们提供了各自的电子邮件地址,表明该研究得到了跨学科合作的支持。
该论文主要围绕多模态对象再识别中的特征选择和模态融合进行深入探讨,提出了一种创新的编辑器框架,旨在提升系统的鲁棒性和性能。这对于当前的计算机视觉和跨模态学习领域具有重要意义。
Transformer Encoder
Linear Projection
ViT-B/16
Spatial-Frequency Token SelectionShared Feature Extraction Hierarchical Masked Aggregation
Masked
Encoder
Masked Encoder
Triplet Loss
CE Loss
BN Neck
Spatial-based
Token Selection
Frequency-based
Token Selection
Union
Background Consistency Constraint
RGB
NIR
TIR
Masked
Encoder
Masked
Encoder
Object-Centric Feature Refinement
Concatenation
C [cls] Token Patch Token Reserved Token
Dropped Token
C
C
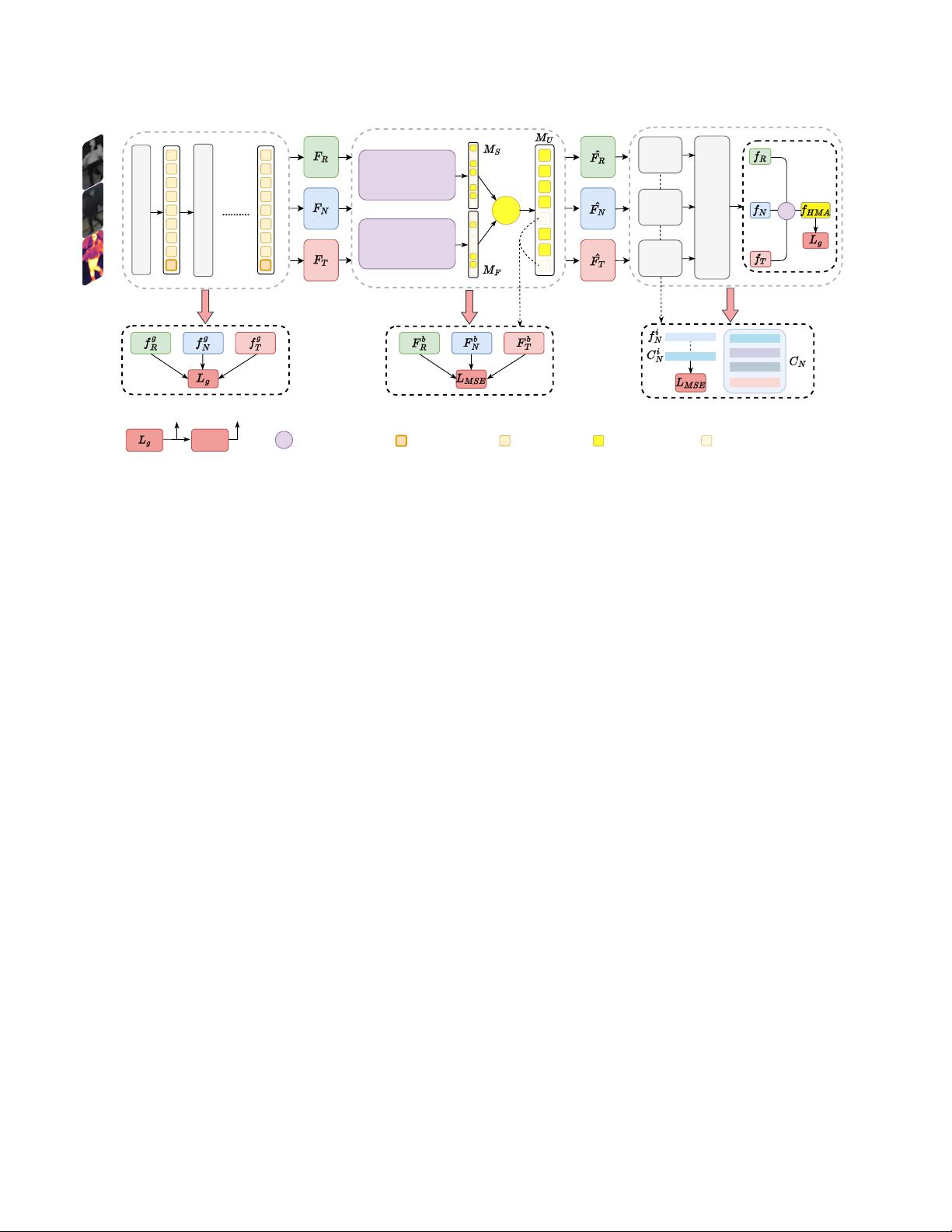
Figure 2. An illustration of our proposed EDITOR. First, features from different input modalities are extracted by using the shared ViT-B/16
backbone. Then, a Spatial-Frequency Token Selection (SFTS) is utilized to select diverse tokens with object-centric features. Meanwhile,
the Background Consistency Constraint (BCC) loss is designed for stabilizing the selection process. After that, a Hierarchical Masked
Aggregation (HMA) is grafted to aggregate the selected tokens. Finally, combined with the Object-Centric Feature Refinement (OCFR)
loss, the whole framework can obtain more discriminative features for multi-modal object ReID.
ferent modal features with a heterogeneous score coher-
ence loss. Then, Zheng et al. [54] reduce the discrep-
ancies from sample and modality aspects. From the per-
spective of generating modalities, Guo et al. [9] propose a
GAFNet to fuse the multiple data sources. He et al. [12]
propose a GPFNet to adaptively fuse multi-modal features
with graph learning. With Transformers, Pan et al. [29] in-
troduce a PHT, employing a feature hybrid mechanism to
balance modal-specific and modal-shared information. Jen-
nifer et al. [4] provide a UniCat by analyzing the issue of
modality laziness. Very recently, Wang et al. [43] propose a
novel token permutation mechanism for robust multi-modal
object ReID. While contributing to the multi-modal object
ReID, they commonly overlook the influence of irrelevant
backgrounds on the aggregation of features across different
modalities. In contrast, our proposed EDITOR explicitly
addresses the influence of irrelevant backgrounds on multi-
modal feature aggregation. Our approach effectively iden-
tifies critical regions within each modality while fostering
inter-modal collaboration. Furthermore, the incorporation
of BCC and OCRF losses, along with the innovative SFTS
and HMA modules, distinguishes our work as a promising
avenue for improved performance in complex scenarios.
2.3. Token Selection in Transformer
With the increasing adoption of Transformers [16, 24, 31],
token selection has gained significant attention [1, 8, 10, 11,
23, 28, 33, 46], due to its ability to focus on essential objects
and reduce computational overhead. In vision tasks, such as
ReID, where fine-grained features are crucial, the extraction
of key regions becomes particularly important. For exam-
ple, TransFG [11] utilizes the multi-head self-attention of
ViT to select representative local patches, achieving out-
standing performance in fine-grained classification tasks.
DynamicViT [33] employs gating mechanisms to dynam-
ically accelerate both training and inference. TVTR [46]
extends token selection to cross-modal ReID, aligning fea-
tures by selecting the top-K salient tokens. However, our
method differs from them in the following ways: (1) Our se-
lection is instance-level, where for different input images,
the model dynamically selects different numbers of object-
centirc tokens. Unlike previous methods, which specify the
fixed top-K local regions for feature aggregation, our ap-
proach allows the model to adapt more flexibly to various
inputs. (2) Previous methods do not consider the impact of
distracted backgrounds during the early selection process.
With our proposed losses, we effectively stabilize the se-
lection process, achieving dynamic distribution alignments.
Thus, we provide a more flexible framework, ultimately en-
hancing ReID performance in complex scenarios.
3. Proposed Method
As illustrated in Fig. 2, our proposed EDITOR com-
prises three key components: Shared Feature Extraction,
Spatial-Frequency Token Selection (SFTS) and Hierarchi-
cal Masked Aggregation (HMA). In addition, we incor-
porate the Background Consistency Constraint (BCC) and
剩余13页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-08-08 上传
2021-05-28 上传
2021-04-30 上传
2022-03-17 上传
2021-03-03 上传

深研AILab
- 粉丝: 351
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- Cognos8安装及配置
- Packt.Publishing.Blender.3D.Architecture.Buildings.and.Scenery
- Quartz Job Scheduling Framework
- C#完全手册PDF(清晰版)
- 典型的ALV-GRID report .doc
- Windows2008基本配置技巧
- Oracle表分区 建表空间 创建用户
- 教研室公告项目需求书
- oracle常用经典sql查询.doc
- CLR via C# (pdf)
- 个人整理的ARM指令集(doc)
- C51行列键盘扫描程序
- 超声气体浓度传感器的无线节点设计
- 图书销售管理系统毕业论文
- 面向无线传感器网络的操作系统组件化设计
- javaee快捷键 小常识
