Curve-GCN:快速交互式图形卷积标注技术
下载需积分: 0 | PDF格式 | 3.79MB |
更新于2024-08-05
| 3 浏览量 | 举报
"快速图卷积交互式标注1"
这篇摘要介绍了一种名为"Curve-GCN"的新框架,用于快速的交互式对象标注。在计算机视觉领域,手动标注物体边界是一项耗时的工作。传统的解决方案如Polygon-RNN通过循环神经网络(CNN-RNN)架构生成多边形标注,允许用户进行交互式修正。然而,Polygon-RNN存在顺序预测的局限性,即每次只能预测一个顶点,这使得标注过程效率不高。
Curve-GCN的创新之处在于它利用图卷积网络(GCN)同时预测所有顶点,从而消除了顺序预测的限制。这种方法提高了标注效率,不仅适用于直线型物体,也适用于曲线型物体,支持以多边形或样条曲线的形式进行标注。此外,Curve-GCN模型是端到端训练的,这意味着它可以整合整个标注过程,从输入图像到输出标注,无需额外的后处理步骤。
实验结果表明,Curve-GCN在自动模式下优于现有的所有方法,包括强大的PSP-DeepLab等。在交互式模式下,其效率比优化过的Polygon-RNN++显著提高。具体性能上,Curve-GCN的自动模式运行时间为29.3毫秒,而交互式模式仅为2.6毫秒,分别比Polygon-RNN++快约10倍和10倍,极大地提升了标注速度和用户体验。
这一框架的提出对于提高计算机视觉应用中的图像标注效率具有重要意义,特别是对于需要大量手动标注的数据集,如自动驾驶、遥感图像分析等领域。通过引入图卷积网络,Curve-GCN不仅优化了标注速度,还增强了模型的泛化能力,有望推动图像分析和理解技术的进步。
Fast Interactive Object Annotation with Curve-GCN
Huan Ling
1,2∗
Jun Gao
1,2∗
Amlan Kar
1,2
Wenzheng Chen
1,2
Sanja Fidler
1,2,3
1
University of Toronto
2
Vector Institute
3
NVIDIA
{linghuan, jungao, amlan, wenzheng, fidler}@cs.toronto.edu
Abstract
Manually labeling objects by tracing their boundaries is
a laborious process. In [
7
,
2
], the authors proposed Polygon-
RNN that produces polygonal annotations in a recurrent
manner using a CNN-RNN architecture, allowing interac-
tive correction via humans-in-the-loop. We propose a new
framework that alleviates the sequential nature of Polygon-
RNN, by predicting all vertices simultaneously using a Graph
Convolutional Network (GCN). Our model is trained end-
to-end. It supports object annotation by either polygons or
splines, facilitating labeling efficiency for both line-based
and curved objects. We show that Curve-GCN outperforms
all existing approaches in automatic mode, including the
powerful PSP-DeepLab [
8
,
23
] and is significantly more effi-
cient in interactive mode than Polygon-RNN++. Our model
runs at 29.3ms in automatic, and 2.6ms in interactive mode,
making it 10x and 100x faster than Polygon-RNN++.
1. Introduction
Object instance segmentation is the problem of outlining
all objects of a given class in an image, a task that has been
receiving increased attention in the past few years [
15
,
36
,
20
,
3
,
21
]. Current approaches are all data hungry, and
benefit from large annotated datasets for training. However,
manually tracing object boundaries is a laborious process,
taking up to 40sec per object [
2
,
9
]. To alleviate this problem,
a number of interactive image segmentation techniques have
been proposed [
28
,
23
,
7
,
2
], speeding up annotation by a
significant factor. We follow this line of work.
In DEXTR [
23
], the authors build upon the Deeplab ar-
chitecture [
8
] by incorporating a simple encoding of human
clicks in the form of heat maps. This is a pixel-wise ap-
proach, i.e. it predicts a foreground-background label for
each pixel. DEXTR showed that by incorporating user clicks
as a soft constraint, the model learns to interactively improve
its prediction. Yet, since the approach is pixel-wise, the
worst case scenario still requires many clicks.
Polygon-RNN [
7
,
2
] frames human-in-the-loop annota-
tion as a recurrent process, during which the model sequen-
∗
authors contributed equally
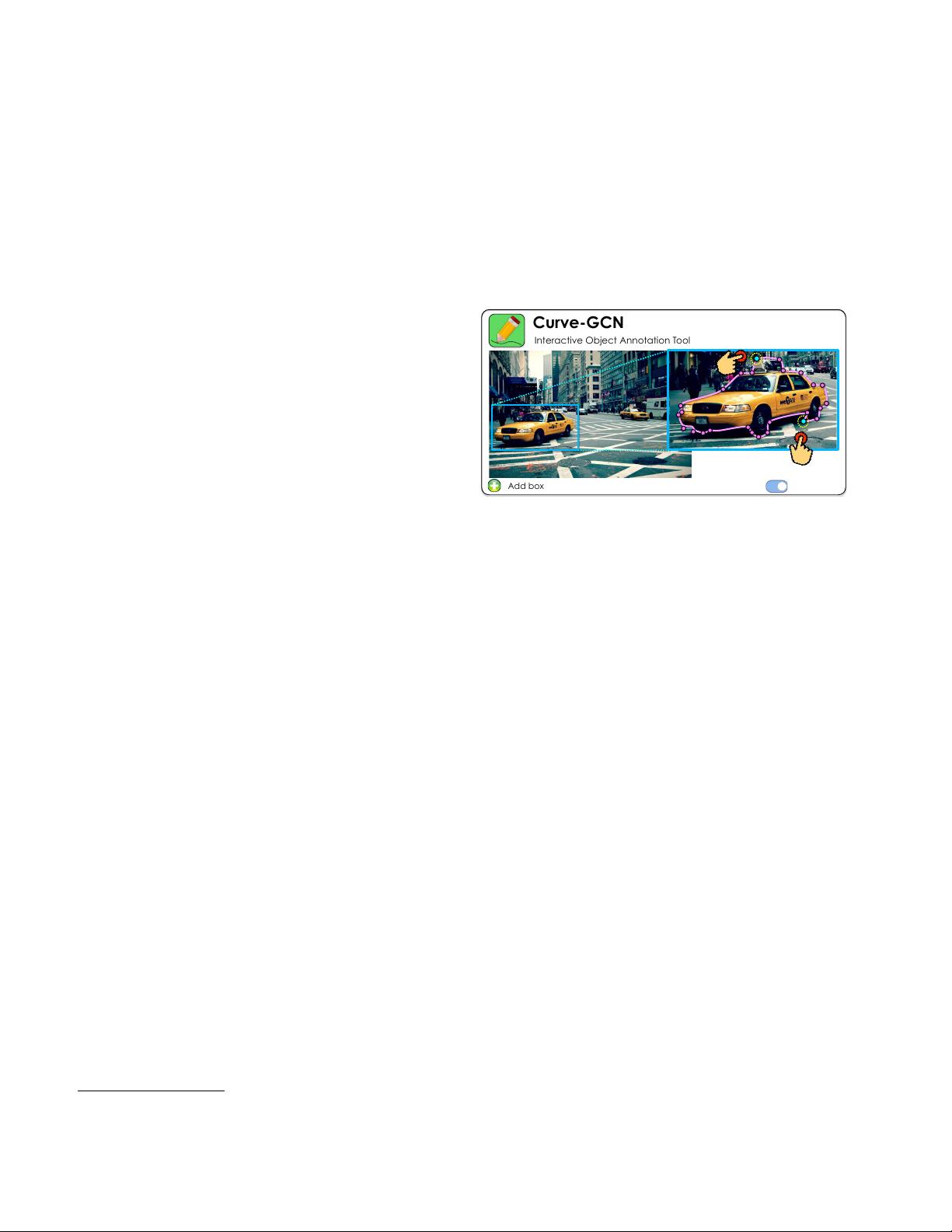
Interactive Object Annotation Tool
Curve-GCN
Add box
Spline
Polygon
https://richardkleincpa.com/new-york-city-street-wallpaper/
Figure 1: We propose Curve-GCN for interactive object annota-
tion. In contrast to Polygon-RNN [
7
,
2
], our model parametrizes
objects with either polygons or splines and is trained end-to-end at
a high output resolution.
tially predicts vertices of a polygon. The annotator can
intervene whenever an error occurs, by correcting the wrong
vertex. The model continues its prediction by conditioning
on the correction. Polygon-RNN was shown to produce an-
notations at human level of agreement with only a few clicks
per object instance. The worst case scenario here is bounded
by the number of polygon vertices, which for most objects
ranges up to 30-40 points. However, the recurrent nature
of the model limits scalability to more complex shapes, re-
sulting in harder training and longer inference. Furthermore,
the annotator is expected to correct mistakes in a sequential
order, which is often challenging in practice.
In this paper, we frame object annotation as a regres-
sion problem, where the locations of all vertices are pre-
dicted simultaneously. We represent the object as a graph
with a fixed topology, and perform prediction using a Graph
Convolutional Network. We show how the model can be
used and optimized for interactive annotation. Our frame-
work further allows us to parametrize objects with either
polygons or splines, adding additional flexibility and effi-
ciency to the interactive annotation process. The proposed
approach, which we refer to as Curve-GCN, is end-to-end
differentiable, and runs in real time. We evaluate our Curve-
GCN on the challenging Cityscapes dataset [
10
], where we
outperform Polygon-RNN++ and PSP-Deeplab/DEXTR in
both automatic and interactive settings. We also show that
our model outperforms the baselines in cross-domain an-
notation, that is, a model trained on Cityscapes is used to
1
arXiv:1903.06874v1 [cs.CV] 16 Mar 2019
下载后可阅读完整内容,剩余9页未读,立即下载
相关推荐





光与火花
- 粉丝: 27
 我的内容管理
展开
我的内容管理
展开







最新资源
- VB通过Modbus协议控制三菱PLC通讯实操指南
- simfinapi:R语言中简化SimFin数据获取与分析的包
- LabVIEW温度控制上位机程序开发指南
- 西门子工业网络通信实例解析与CP243-1应用
- 清华紫光全能王V9.1软件深度体验与功能解析
- VB实现Access数据库数据同步操作指南
- VB实现MSChart绘制实时监控曲线
- VC6.0通过实例深入访问Excel文件技巧
- 自动机可视化工具:编程语言与正则表达式的图形化解释
- 赛义德·莫比尼:揭秘其开创性技术成果
- 微信小程序开发教程:如何实现模仿ofo共享单车应用
- TrueTable在Windows10 64位及CAD2007中的完美适配
- 图解Win7搭建IIS7+PHP+MySQL+phpMyAdmin教程
- C#与LabVIEW联合采集NI设备的电压电流信号并创建Excel文件
- LP1800-3最小系统官方资料压缩包
- Linksys WUSB54GG无线网卡驱动程序下载指南
