CDH大数据平台与Impala交互式查询解析
155 浏览量
更新于2024-08-28
收藏 678KB PDF 举报
"大数据平台CDH和Impala的使用"
Cloudera的DistributionIncludingApacheHadoop(CDH)是一个集成的大数据处理平台,旨在简化Hadoop生态系统的部署和管理。CDH包含了多个关键的Hadoop组件,如HDFS(Hadoop分布式文件系统)、MapReduce(分布式计算框架)、Hive(数据仓库工具)、Pig(数据分析工具)、HBase(NoSQL数据库)、Zookeeper(协调服务)以及Sqoop(数据导入导出工具)。通过Web界面,CDH提供了一种集中式的管理方式,使得安装、配置和维护大数据环境变得更加容易。
ClouderaManager作为CDH的核心组件,具有以下关键功能:
1. **管理**:允许管理员进行集群级别的操作,例如添加或删除节点,调整集群配置,以及进行服务升级。
2. **监控**:实时监控集群的健康状况,包括硬件资源使用、服务状态和性能指标,确保系统的稳定运行。
3. **诊断**:当出现问题时,ClouderaManager能够进行故障排查,提供可能的解决方案,帮助快速定位和修复问题。
4. **集成**:整合不同组件,实现数据流动和任务协调,促进跨服务的数据处理流程。
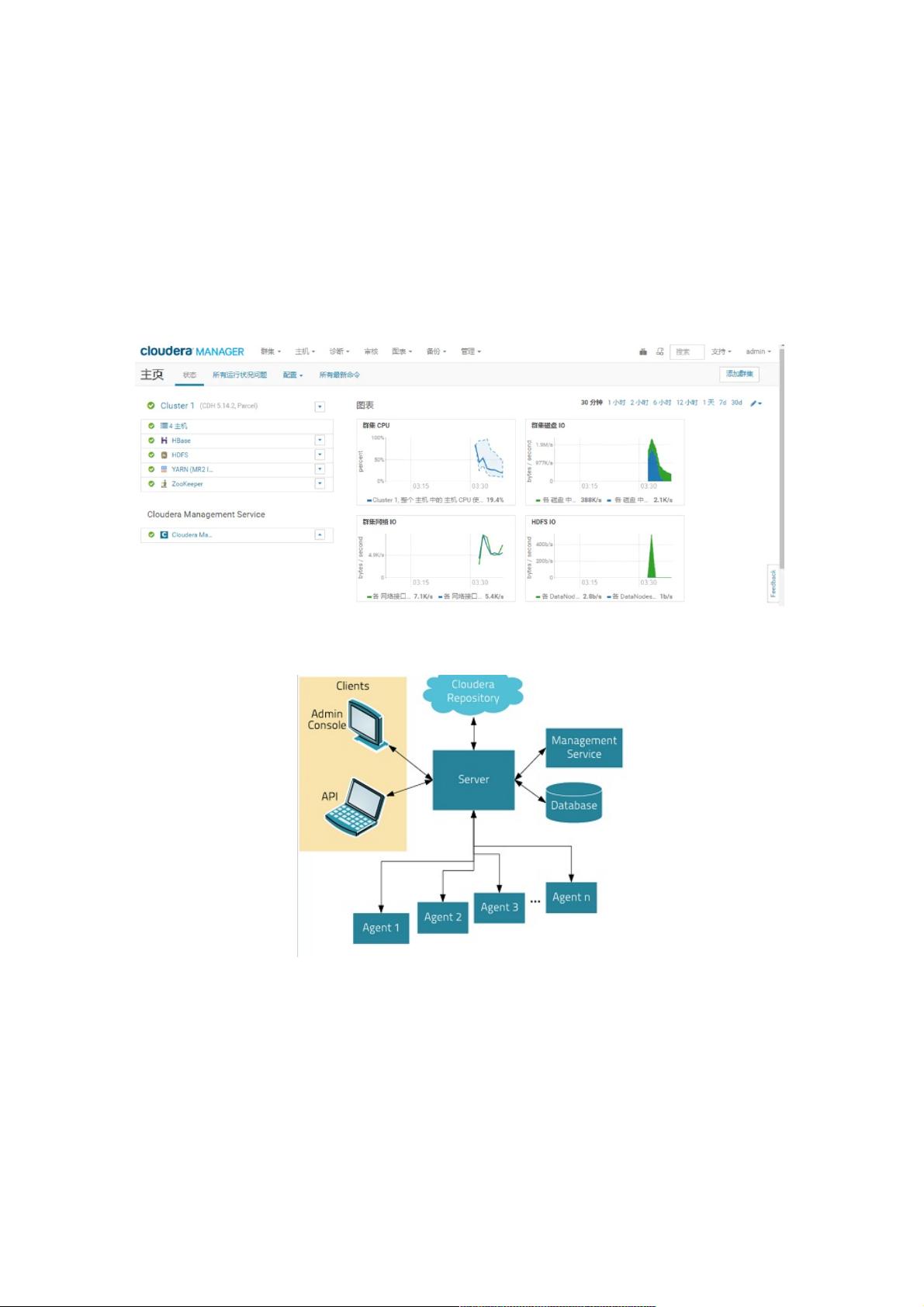
ClouderaManager的架构由Server、Agent、ManagementService、Database、ClouderaRepository和Clients组成,共同确保高效、安全地管理和操作整个大数据环境。
在CDH中,Impala是一个重要的组件,它是一个用于快速查询大规模数据的SQL引擎。Impala的设计目标是提供低延迟的交互式查询,同时兼容Hadoop生态系统。它与Hive共享元数据,但与Hive的MapReduce执行模型不同,Impala直接在内存中处理查询,避免了磁盘I/O,从而显著提高了查询速度。
**Impala的优缺点**:
优点:
- 内存计算:Impala在内存中进行计算,减少了I/O操作,提高了查询效率。
- 直接访问数据:不需要通过MapReduce,能直接处理HDFS和HBase中的数据,减少了中间步骤。
- 数据局部性:利用数据局部性策略,减少网络传输,提高性能。
- 支持多种文件格式:适应不同的数据存储需求。
- 兼容Hive metastore:可以直接查询和分析存储在Hive中的数据。
缺点:
- 内存依赖:Impala对内存资源的需求较大,可能导致资源瓶颈。
- 依赖Hive:Impala的元数据管理依赖于Hive,如果Hive出现问题,可能影响Impala的正常工作。
- 在实践中,对于大规模分区的数据,查询优化可能会变得复杂,需要精心设计和调优。
CDH和Impala的结合为企业提供了强大的大数据处理和分析能力,尤其适合需要快速响应的实时查询场景。然而,为了充分发挥其潜力,需要合理规划硬件资源,优化数据布局,并对Impala进行适当的性能调优。
大数据平台大数据平台CDH和和Impala的使用的使用
一、CDH的介绍
Cloudera版本(Cloudera’s Distribution Including Apache Hadoop,简称CDH),基于Web的用户界面,支持大多数Hadoop组
件,包括HDFS、MapReduce、Hive、Pig、 HBase、Zookeeper、Sqoop,简化了大数据平台的安装、使用难度。
Cloudera Manager的功能:
管理:对集群进行管理,如添加、删除节点等操作。
监控:监控集群的健康情况,对设置的各种指标和系统运行情况进行全面监控。
诊断:对集群出现的问题进行诊断,对出现的问题给出建议解决方案。
集成:多组件进行整合。
Cloudera Manager的架构:
Server:负责软件安装、配置,启动和停止服务,管理服务运行的群集。
Agent:安装在每台主机上。负责启动和停止的过程,配置,监控主机。
Management Service:由一组执行各种监控,警报和报告功能角色的服务。
Database:存储配置和监视信息。
Cloudera Repository:软件由Cloudera管理分布存储库。(类似Maven的中心仓库)
Clients:是用于与服务器进行交互的接口(API和Admin Console)
集群添加服务:
下载后可阅读完整内容,剩余5页未读,立即下载
217 浏览量
552 浏览量
120 浏览量
466 浏览量
352 浏览量
129 浏览量
313 浏览量
1548 浏览量
145 浏览量

weixin_38743372
- 粉丝: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- Cairngorm中文版:Flex应用设计指南
- ThinkPHP 1.0.0RC1 开发者手册:框架详解与应用构建
- ZendFramework中文手册:访问控制与认证
- 深入理解C++指针:从基础到复杂类型
- Java设计模式详解:从基础到高级
- JavaScript高级教程:深入解析基础与对象
- Qt教程:从Hello World到GUI游戏开发
- RealView编译工具链2.0:链接程序与实用程序深度解析
- Unicode编码与.NET Framework中的实现
- Linux内核0.11完全注释 - 赵炯
- C++ 程序设计员面试试题深入分析与解答
- Tomcat深度解析:配置、应用与优势
- 车辆管理系统:全面解决方案与功能设计
- 使用JXplorer连接Apache DS LDAP服务器指南
- 电子商务环境下的企业价值链分析及增值策略
- SAP仓库管理系统详解:灵活高效的库存控制
