CUDA编程优化:加速计算与并行策略
需积分: 9 160 浏览量
更新于2024-07-19
收藏 2.12MB PPTX 举报
CUDA(Compute Unified Device Architecture)是一种由NVIDIA公司开发的并行计算平台和编程模型,专为在图形处理单元(GPU)上进行通用计算而设计。它极大地简化了在GPU上进行大规模并行计算的过程,使得原本需要在CPU上耗时的任务得以加速,尤其是在科学计算、机器学习和深度学习等领域。
在CUDA编程优化方面,关键在于理解GPU的特性以及如何有效地利用这些特性来提升代码性能。GPU的核心优势在于其拥有大量的并行核心,通常可达数百甚至数千个,这使得它非常适合处理大量并行任务,如矩阵运算、图像处理和大规模数据分析。然而,与CPU相比,GPU的优势并不体现在低延迟的缓存访问或高级指令执行策略,而是通过并行数据流来实现高吞吐量。
为了实现GPU加速,开发者通常需要对程序代码进行以下几个方面的优化:
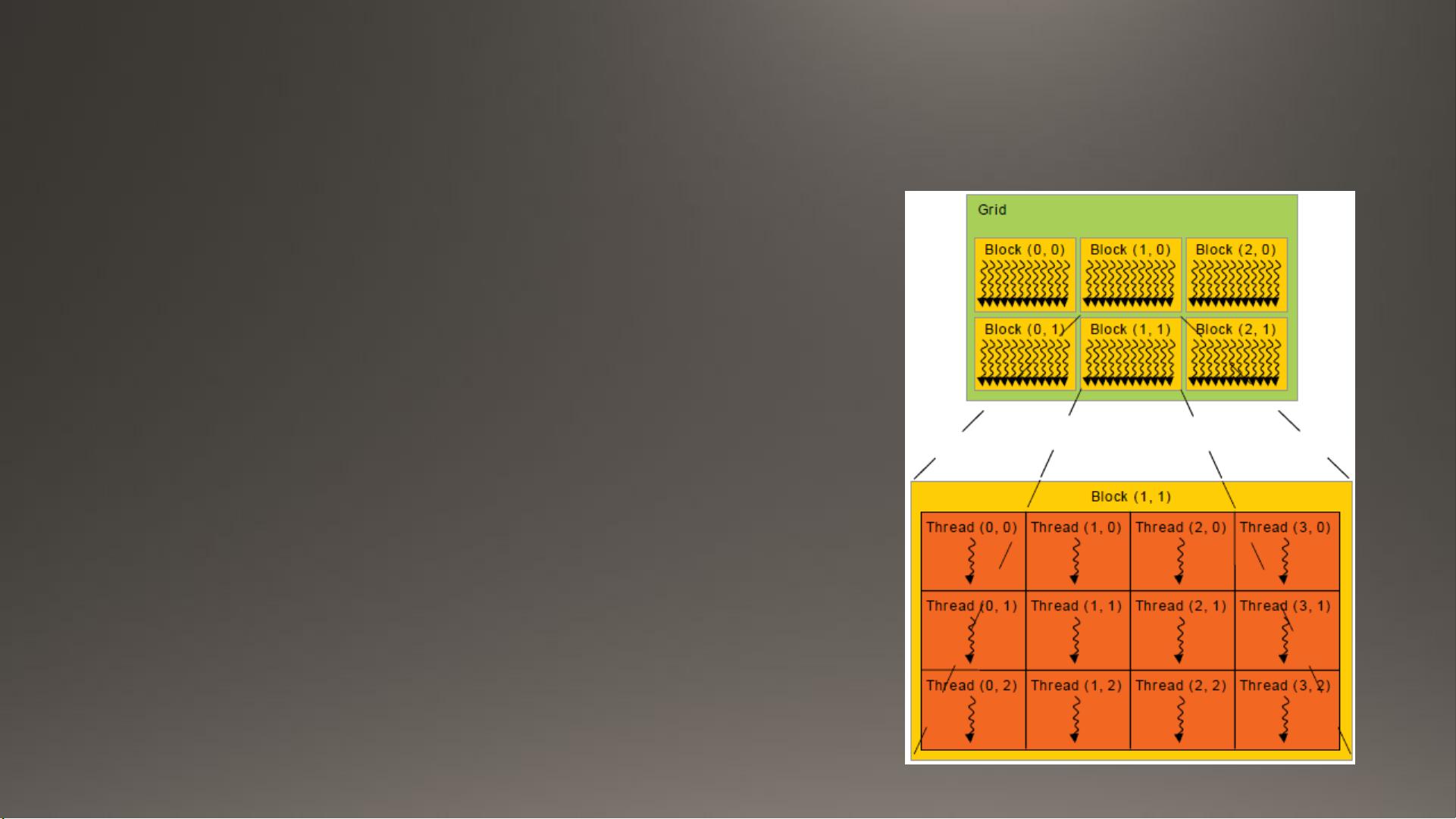
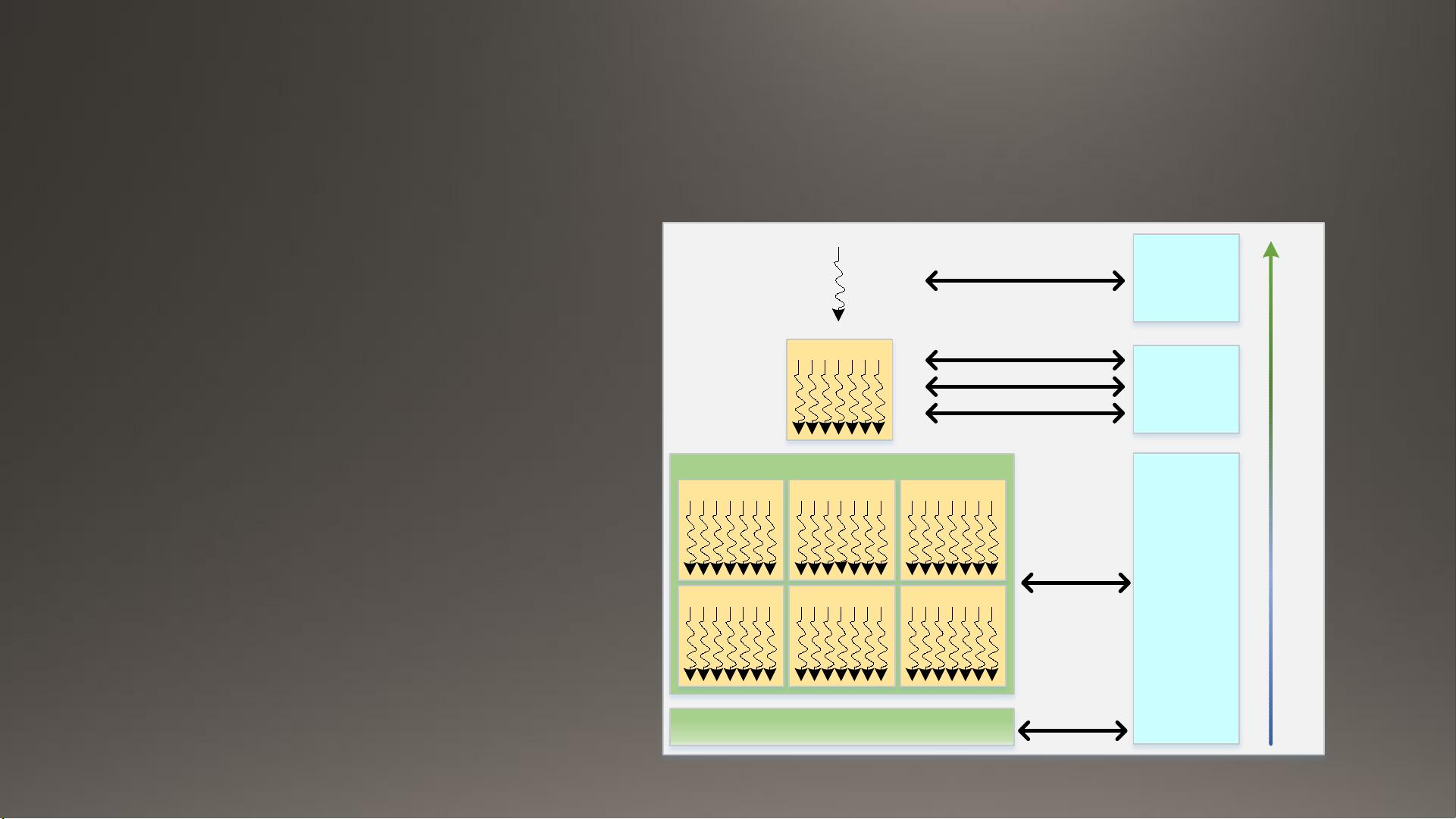
1. **利用GPU的并行性**:在编写CUDA代码时,要充分利用GPU的并行特性,将数据集划分为多个独立的块(blocks)和网格(grids),每个块可以被多个线程同时执行。通过定义适当的并行度(block size 和 grid size),可以最大化利用GPU资源。
2. **避免全局内存访问**:由于GPU的全局内存访问速度较慢,应尽可能减少对全局内存的依赖,改用更快的共享内存或局部存储来存储频繁访问的数据。
3. **减少同步开销**:通过使用CUDA的异步API,减少线程间的同步操作,避免阻塞其他线程的执行,从而提高整体效率。
4. **利用硬件流水线**:GPU内部有高度并行的流水线,开发者需要确保算法和数据布局能充分利用这一点,避免不必要的指令调度延迟。
5. **利用GPU特定优化库**:许多库如cuBLAS、cuDNN等已经针对CUDA进行了优化,直接调用这些库可以大幅提高性能。
6. **CPU与GPU协同工作**:对于那些计算强度适中的部分,可以考虑在CPU上执行,将主要的并行计算任务转移到GPU,其余部分保持在CPU上,实现CPU-GPU的异构计算。
7. **利用现代GPU架构的新特性**:随着GPU新版本的发布,如P100,了解其特性和改进,如更高的内存带宽和更低的延迟,可以帮助开发者针对特定硬件进行优化。
CUDA优化代码是通过对现有代码结构的调整和利用GPU的并行处理能力,以实现从CPU计算向GPU计算的迁移,从而在处理大规模并行任务时显著提高计算速度。但同时也需注意,过度优化可能导致代码复杂性增加,因此在追求性能的同时,代码的可读性和维护性也是必须考虑的因素。

#6+=.
•
./ 编译器驱动程序
•
3/%> 汇编工具
•
;?!/ 目标文件转储工具,检查 所生成
的二进制文件
•
.!5/ 英伟达系统管理接口,完全支持
% 、 @! ,部分支持 : 系列
剩余60页未读,继续阅读
点击了解资源详情
154 浏览量
点击了解资源详情
645 浏览量
240 浏览量
616 浏览量
485 浏览量

夏天不穿貂
- 粉丝: 4
- 资源: 16
 我的内容管理
展开
我的内容管理
展开







最新资源
- activerecord-postgis-adapter, 在PostgreSQL和rgeo上,基于PostGIS的ActiveRecord连接适配器,基于.zip
- 管理系统后台模板manage.zip
- data-scientist
- Ameme
- pretty-error, 查看 node.js 错误,减少了混乱.zip
- 行业文档-设计装置-安全胶带纸.zip
- 5G Massive MIMO的系统架构及测试技术的详细资料概述-综合文档
- CH341土豪金xtw.zip
- js-actions-azure
- SparkCore-Photon-Fritzing, Spark核心零件和示例的Fritzing库.zip
- 操作系统(学校).rar
- Adalight-FastLED:具有FastLED支持的Adalight
- profile-viewer-tutorial
- opencv-python3.4.1.15.zip
- 文卡特
- hmpo-laptops-public:公共回购以对开发人员笔记本电脑执行初始的引导
