Python爬虫:微信扫码登录页面的抓取技巧
PDF格式 | 601KB |
更新于2024-09-02
| 136 浏览量 | 举报
"Python抓取需要扫微信登陆页面的教程"
在Python网络爬虫领域,有时候我们需要抓取的网页需要经过身份验证,例如通过微信扫码登陆。本教程将介绍如何使用Python来抓取一个需要微信扫码登录的网页。首先,我们要明确目标——获取特定的页面信息,包括工单编号、发起时间、工单标题和正文内容。
一、抓取情况描述
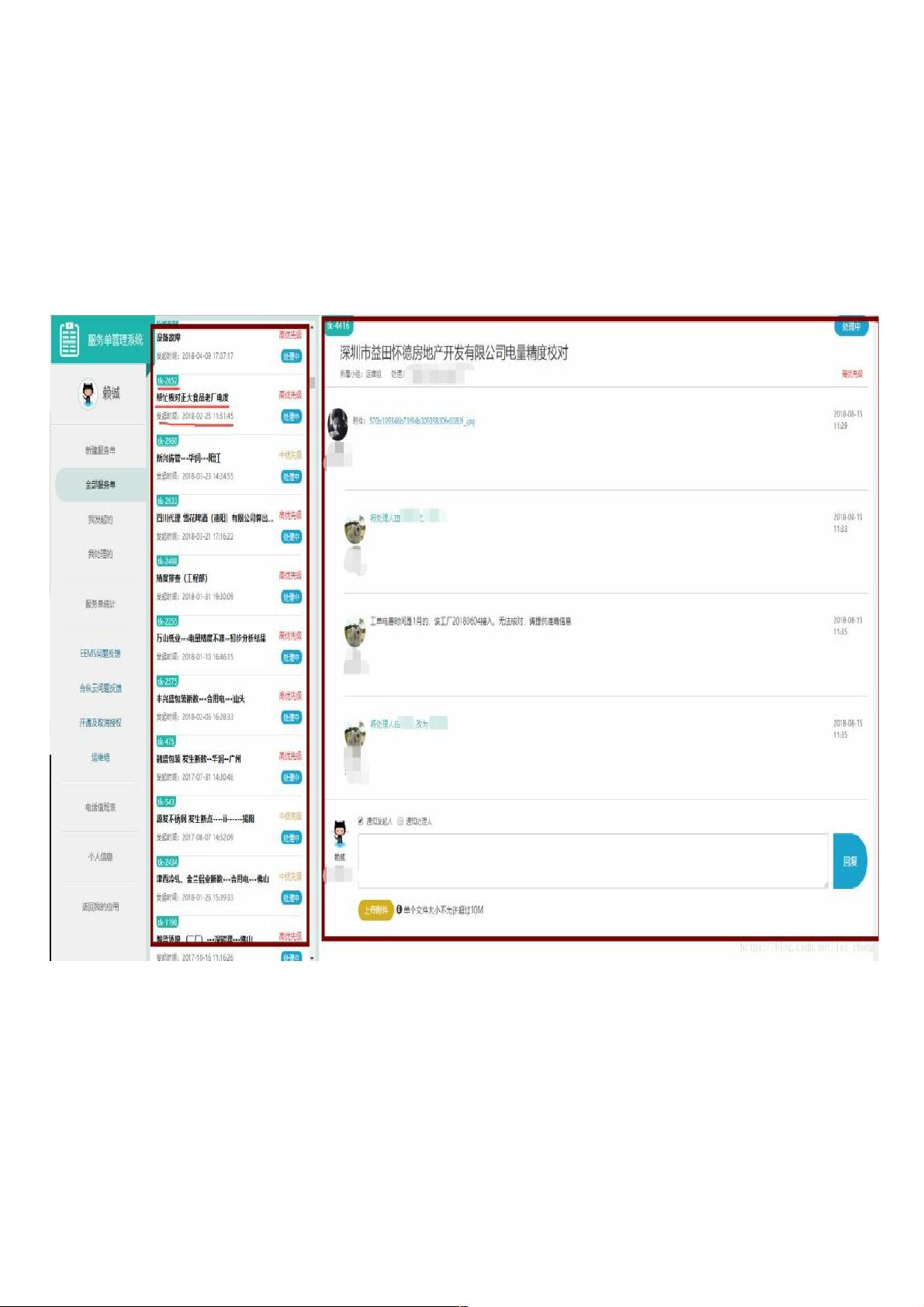
针对这个特定的案例,我们关注的网页是一个公司的工单系统,其登录方式是通过微信扫码。登录网址为https://app-ticketsys.hezongyun.com/index.php。在成功登录并进入页面后,我们可以看到需要抓取的数据,主要包括:
1. 工单编号(如:TK-2960)
2. 工单发起时间(如:2018-08-17 11:12:13)
3. 工单标题
4. 工单正文内容
二、网页分析
为了成功抓取这些信息,我们需要对网页进行深入分析。在浏览器中,我们可以使用开发者工具(通常是通过Ctrl+Shift+I快捷键或右键点击检查)来查看网页的结构和请求信息。关键要点如下:
1. 请求URL:https://app-ticketsys.hezongyun.com/index.php/ticket/ticket_list/init,这是我们需要爬取页面的实际数据来源。
2. 请求方法:GET,意味着我们需要使用GET请求来获取页面内容。
3. 饼干(Cookie):用于保持登录状态,爬虫需要模拟发送这个Cookie以确保访问权限。
4. User-Agent:浏览器标识,用于模拟用户访问,避免被服务器识别为爬虫。
了解了这些基本信息后,我们可以使用Python的BeautifulSoup库解析HTML,并通过选择器(Selector)来定位我们需要的内容。例如,如果HTML结构如下:
```html
<html>
<head><title>...</title></head>
<body>
<p class="title" name="dromouse">...</p>
<p class="story">...</p>
<!-- ... -->
```
我们可以使用BeautifulSoup的CSS选择器语法来获取特定元素:
```python
from bs4 import BeautifulSoup
import requests
response = requests.get(url, headers={'User-Agent': 'Mozilla/5.0...'}, cookies=cookies)
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.select_one('.title')['name'] # 获取title的name属性
story = soup.select_one('.story').text # 获取story的文本内容
```
然而,对于微信扫码登录的页面,通常会涉及更复杂的处理,如模拟登录流程、处理JavaScript生成的内容(如果页面使用了AJAX技术)以及处理验证码等。可能需要用到如Selenium、Scrapy等更强大的工具,它们能够模拟浏览器行为,包括加载JavaScript和处理交互式元素。
在实际操作中,你需要根据网站的具体实现来调整策略。例如,可能需要先发送POST请求模拟登录过程,然后获取并保存Session ID或Cookie,以便在后续的GET请求中保持登录状态。对于微信扫码登录,可能还需要调用微信提供的API来获取扫码后的授权信息。
Python抓取需要微信扫码登录的页面是一个挑战,涉及到模拟登录、处理Cookies、理解和解析复杂的网页结构等多个步骤。在遵循合法、道德的爬虫实践原则下,理解并运用这些技术可以帮助我们有效地获取所需信息。
python抓取需要扫微信登陆页面抓取需要扫微信登陆页面
主要介绍了python抓取需要扫微信登陆页面的相关知识,非常不错,具有一定的参考借鉴价值,需要的朋友可以参考下
一,抓取情况描述一,抓取情况描述
1.抓取的页面需要登陆,以公司网页为例,登陆网址https://app-ticketsys.hezongyun.com/index.php ,(该网页登陆方式微信扫码登陆)
2.需要抓取的内容如下图所示:
需要提取
工单对应编号,如TK-2960
工单发起时间,如2018-08-17 11:12:13
工单标题内容,如设备故障
工单正文内容,如最红框所示
二,网页分析二,网页分析
1.按按Ctrl + Shift + I或者鼠标右键点击检查进入开发人员工具。
可以看到页面显示如下:
下载后可阅读完整内容,剩余3页未读,立即下载
相关推荐




weixin_38725086
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- InfoQ中文站:Struts2入门指南
- 探索函数式编程:Haskell语言实践
- 在Linux AS4上安装MySQL 5.0.27的详细步骤
- Linux环境下安装配置JDK1.5、Tomcat5.5、Eclipse3.2及MyEclipse5.1指南
- MapGIS 7.0:嵌入式GIS开发平台详解与关键技术
- MATLAB编程风格与最佳实践
- 自顶向下语法分析方法:LL(1)文法与确定性分析
- Tapestry实战指南:探索动态Web应用开发
- MyEclipse安装指南:JDK与Tomcat设置详解
- Adobe Flash Video Encoder 中文指南
- 测试环境搭建与管理:要求、备份与恢复
- C语言经典编程习题解析:从100例中学习
- 高质量C/C++编程规范与指南
- JSP驱动的个性化网上书店系统开发与实现
- MediaTek MTK入门教程:软件架构与开发流程解析
- 学习Python:第二版详细指南
