数据结构:平均时间复杂度与分摊时间复杂度解析
 已收录资源合集
已收录资源合集
需积分: 0 21 浏览量
更新于2024-06-30
收藏 4.07MB PDF 举报
本资源主要讨论了数据结构中的向量,并着重分析了向量操作的时间复杂度,包括平均时间复杂度和分摊时间复杂度。同时,提到了这两个概念的区别和应用场景,以及如何通过分摊分析来更准确地评估算法性能。另外,还涉及了在数组复制操作中,如何处理目标数组与源数组可能存在的空间重叠问题。
在数据结构中,向量是一种基础且常用的数据结构,它以线性方式存储元素,支持动态扩展和收缩。本章节的讨论聚焦于向量操作的时间复杂度分析,特别是算法分析的两个重要概念:平均时间复杂度和分摊时间复杂度。
平均时间复杂度是根据各种输入实例可能出现的概率分布来计算的加权平均运行时间。它在评估算法性能时,假设输入实例遵循一定的概率模型。例如,对于快速排序,如果假定待排序元素是独立且均匀随机分布的,可以计算其平均时间复杂度。
分摊时间复杂度则更注重算法的全局行为,考虑连续多次操作的整体时间,并将这个时间平摊到每一步操作上。这种方法适用于那些操作之间有因果关系的算法,如伸展树的插入和删除操作。分摊分析可以揭示单次操作的实际成本,即使这些操作在实际应用中并不独立。
以可扩充向量为例,如果简单地用平均分析方法,可能会因不准确的概率分布假设(如扩容与不扩容事件概率相等)而得出错误的性能评估。而通过分摊分析,我们可以看到采用容量加倍策略的向量在实际运行中,随着容量增加,扩容事件的概率会迅速降低,从而更准确地理解其性能。
在实际编程中,数组复制操作必须确保目标数组与源数组的物理独立性,以避免数据污染。如果无法保证这种独立性,算法需要进行调整,例如使用临时数组或者采取其他避免空间重叠的策略。教材中的`copyFrom()`算法即是一个例子,如果目标数组不是独立分配的,那么在复制过程中可能需要额外的检查和处理,以确保数据的正确性。
本章节深入探讨了向量操作的复杂度分析,强调了平均时间复杂度和分摊时间复杂度在算法评估中的差异和应用,并通过实例讲解了如何处理可能的空间重叠问题,这些都是理解和优化数据结构与算法设计的关键点。
第2章 向量 习题[2-9]~[2-10]
41
b) 若仅考查成功癿查找,则平均需要运行多少时间?为什么?
【解答】
这种顺序式的查找算法,可能成功地终止于向量区间内的任意位置。此外,各元素对应的查
找长度,自后向前构成一个递增的等差数列:
1, 2, 3, ..., n = hi - lo
于是若按照默认惯例,假定所有元素作为目标元素的概率均等,则其查找长度的均值(数学
期望)应渐进地与其中的最高项同阶,为O(n)。详细(但嫌复杂)的分析,亦是殊途同归:
(1 + 2 + 3 + ... + n)/n = (n + 1)/2 = O(n)
[2-9] 考查教材 40 页代码 2.11 中癿无序向量揑入算法 insert(r, e)。
试证明,若揑入位置 r 等概率分布,则该算法癿平均时间复杂度为 O(n),n 为向量癿觃模。
【解答】
这里,运行时间主要来自于后继元素顺次后移的操作。因此对于每个插入位置而言,对应的
移动操作次数恰好等于其后继元素(包含自身)的数目。不难看出它们也构成一个等差数列,故
在等概率的假设条件下,其均值(数学期望)应渐进地与其中的最高项同阶,为O(n)。
详细(但嫌复杂)的分析,亦是殊途同归。
[2-10] 考查教材 41 页代码 2.12 中癿无序向量初除算法 remove(lo, hi)。
a) 若以自后向前癿次序逐个前秱后继元素,可能出现什么问题?
【解答】
位置靠前的元素,可能被位置靠后(优先移动)的元素覆盖,从而造成数据的丢失。
b) 何时出现返类问题?试丼一例。(提示:后继元素多二待初除元素时,部分单元会相互覆盖)
【解答】
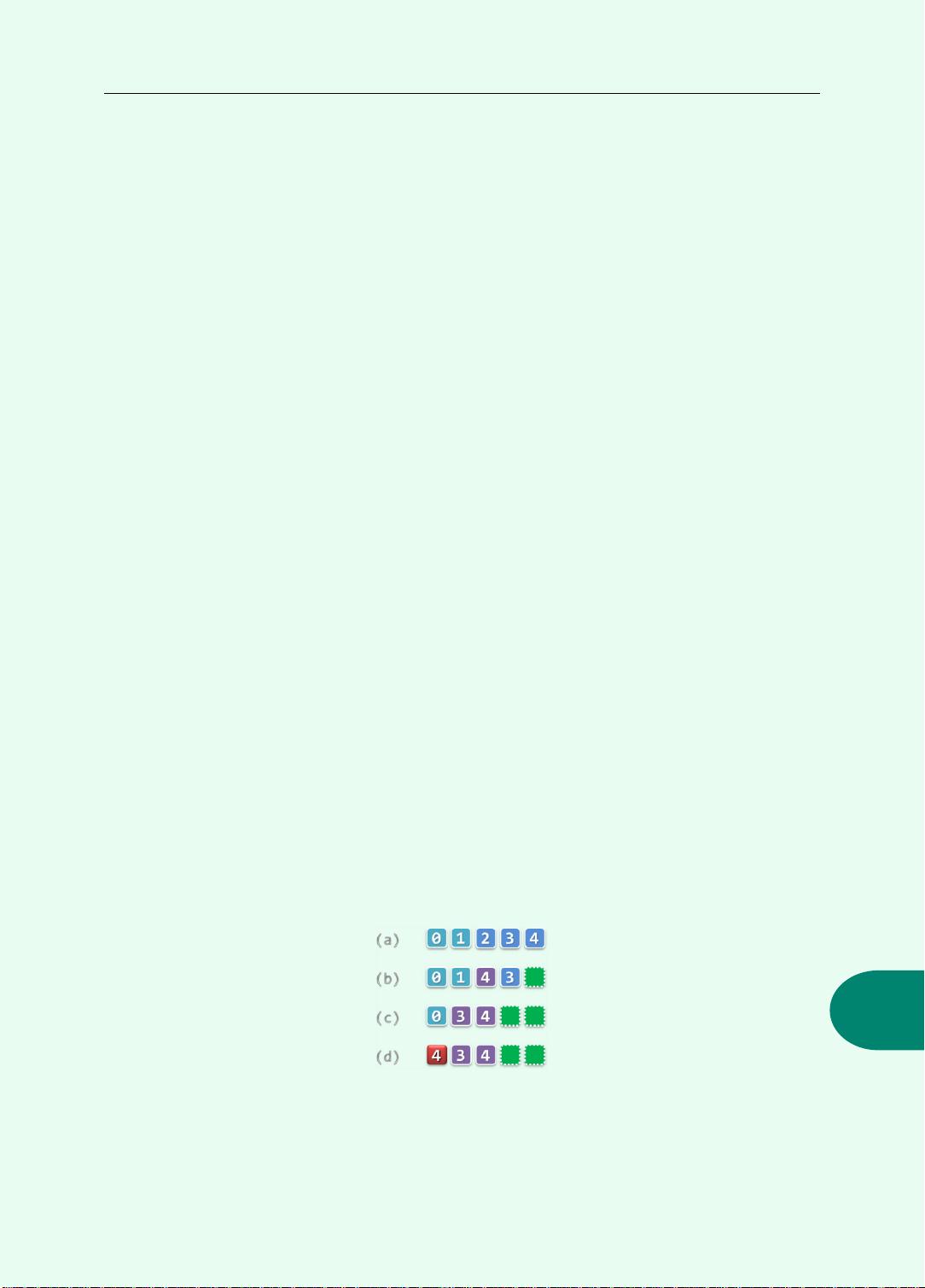
如图x2.3(a)所示,考查规模为5的向量:
V[0, 5) = { 0, 1, 2, 3, 4 }
假设我们试图通过调用V.remove(0, 2)以删除其中的前两个元素。若采用题中所述不当的
次序,则数据元素的移动过程应如该图(b~d)所示。可见,原数据元素V[2] = 2并未顺利转移至
输出向量中的V[0],即出现数据的丢失现象。
图x2.3 无序向量初除算法remove(lo, hi)中,采用自后向前癿次序秱劢可能造成数据丢失
不难验证,只要按照教材的建议颠倒移动的次序,即可便捷地避免这类错误。
剩余37页未读,继续阅读
2022-08-04 上传
点击了解资源详情
2008-12-16 上传
2022-12-01 上传
2012-01-01 上传
点击了解资源详情
点击了解资源详情

thebestuzi
- 粉丝: 37
- 资源: 311
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java集合ArrayList实现字符串管理及效果展示
- 实现2D3D相机拾取射线的关键技术
- LiveLy-公寓管理门户:创新体验与技术实现
- 易语言打造的快捷禁止程序运行小工具
- Microgateway核心:实现配置和插件的主端口转发
- 掌握Java基本操作:增删查改入门代码详解
- Apache Tomcat 7.0.109 Windows版下载指南
- Qt实现文件系统浏览器界面设计与功能开发
- ReactJS新手实验:搭建与运行教程
- 探索生成艺术:几个月创意Processing实验
- Django框架下Cisco IOx平台实战开发案例源码解析
- 在Linux环境下配置Java版VTK开发环境
- 29街网上城市公司网站系统v1.0:企业建站全面解决方案
- WordPress CMB2插件的Suggest字段类型使用教程
- TCP协议实现的Java桌面聊天客户端应用
- ANR-WatchDog: 检测Android应用无响应并报告异常
