深入理解分布式缓存:从原理到实践
需积分: 13 122 浏览量
更新于2024-07-15
收藏 6.76MB DOCX 举报
"该文档是作者的学习笔记,专注于讲解分布式缓存,主要涉及Redis等内容,旨在帮助读者在300分钟内深入理解分布式缓存的原理、应用和设计。"
在分布式缓存的世界中,Redis是一个重要的角色,它是一种开源的、基于键值对的数据结构服务器,广泛应用于缓存解决方案。分布式缓存是为了解决大数据量和高并发场景下,传统数据库访问性能低下和响应时间较长的问题。通过将常用数据存储在内存中,分布式缓存能够显著提高数据访问速度。
缓存的引入源于时间局部性原理,即近期访问过的数据在未来更有可能再次被访问。基于这个原理,缓存设计的核心是将高频访问的数据存储在快速但昂贵的存储介质中,如内存,以减少对慢速但成本更低的存储(如硬盘)的依赖。这通常被称为“以空间换时间”的策略。然而,实际设计中需要权衡性能和成本,例如,内存的读写速度远超硬盘,但其容量和成本相对较高。
缓存的优势显而易见:首先,它可以显著提升系统性能,减少用户等待时间;其次,缓存减少了对网络的依赖,降低了网络拥堵;再者,它能减轻后端服务的处理压力,提高系统稳定性;最后,缓存具有良好的可扩展性,能够应对流量波动,确保服务的连续性。
然而,缓存并非没有代价。它可能导致数据一致性问题,如缓存穿透、缓存雪崩和缓存击穿,需要通过合理的缓存更新策略(如LRU、LFU等)和失效策略(如TTL)来避免。此外,缓存管理也需要额外的维护成本,包括数据同步、容量规划和监控等。
Redis提供了多种数据结构,如字符串、哈希、列表、集合和有序集合,这些数据结构使得Redis适用于多种场景,如计数、发布订阅、消息队列等。分布式缓存的实现还涉及到缓存淘汰策略、缓存更新策略以及缓存与数据库的一致性保证等问题,例如Redis支持的主从复制、哨兵系统和Cluster集群模式,这些都是为了保证数据的安全性和高可用性。
在实际应用中,选择合适的缓存策略至关重要。例如,采用预加载或者懒加载策略可以平衡启动时的性能和内存占用。同时,为了防止缓存失效时所有请求都落到数据库上,可以设置适当的缓存过期时间,并配合批量更新策略,以缓解数据库的压力。
分布式缓存是现代高并发、大数据量应用场景下的关键技术,通过深入理解其原理和实践,能够有效地优化系统性能,提升用户体验。而Redis作为分布式缓存的典型代表,其丰富的数据结构和灵活的配置选项,使其成为开发者手中的利器。
第二章:7 大缓存经典问题
第 04 讲:缓存失效、穿透和雪崩问题怎么处理?
你好,我是你的缓存老师陈波,欢迎进入第 =课时“缓存访问相关的经典问题”。
前面讲解了缓存的原理、引入,以及设计架构,总结了缓存在使用及设计架构过程中的很
多套路和关键考量点。实际上,在缓存系统的设计架构中,还有很多坑,很多的明枪暗箭
如果设计不当会导致很多严重的后果。设计不当,轻则请求变慢、性能降低,重则会数据
不一致、系统可用性降低,甚至会导致缓存雪崩,整个系统无法对外提供服务。
接下来将对缓存设计中的 >大经典问题,如下图,进行问题描述、原因分析,并给出日常
研发中,可能会出现该问题的业务场景,最后给出这些经典问题的解决方案。本课时首先
学习缓存失效、缓存穿透与缓存雪崩。
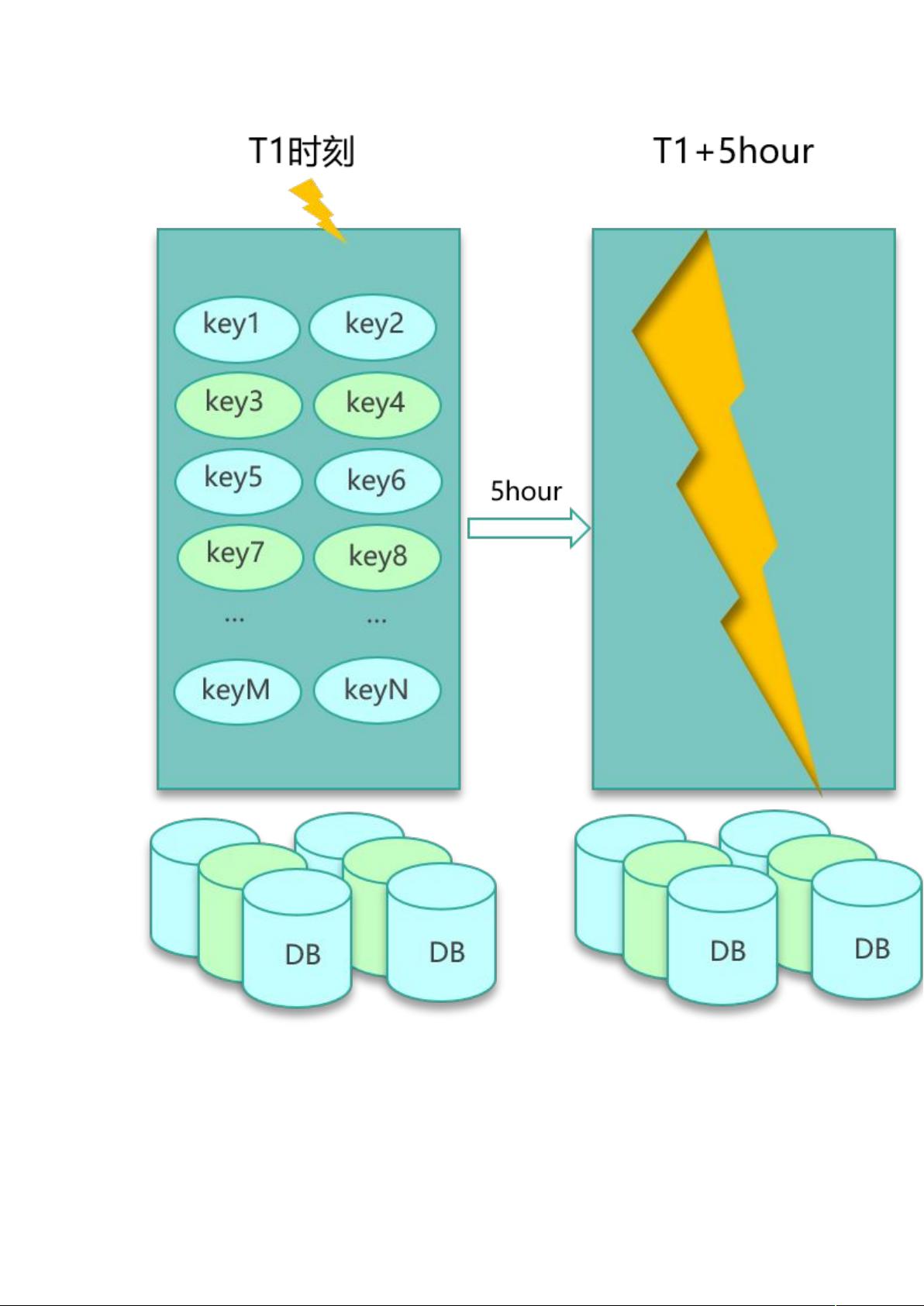
缓存失效
问题描述
缓存第一个经典问题是缓存失效。上一课时讲到,服务系统查数据,首先会查缓存,如果

剩余63页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-12-23 上传
2021-02-03 上传
2023-08-11 上传

少儿学编程
- 粉丝: 13
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







