基于贝叶斯的垃圾邮件4000词分类代码详解
需积分: 5 103 浏览量
更新于2024-08-04
收藏 231KB DOC 举报
本资源文档详细介绍了基于贝叶斯理论的简单垃圾邮件分类方法。主要内容分为以下几个部分:
1. 研究背景:
题目关注的是如何利用贝叶斯模型对电子邮件进行分类,区分正常邮件和垃圾邮件。工作主要通过编程实现这一目标,使用的编程语言是Python,版本为3.7,依赖的库包括scikit-learn、jieba、numpy等。
2. 实验环境:
开发环境是在Windows 10操作系统下进行的。数据集包括两个主要类别:spam文件夹中有7775封垃圾邮件,normal文件夹中有7063封正常邮件,以及392封用于测试的邮件,其中包含一部分正常邮件和垃圾邮件作为验证。
3. 特征提取:
特征提取的关键步骤是词频统计和词汇选择。首先,选取词频最高的4000个词作为关键词,形成词典。然后,将邮件内容转化为词向量,每个维度对应一个词的频率,构建特征向量矩阵,以便后续的机器学习处理。
4. 分类过程:
分类过程涉及文本预处理,如使用jieba分词、停用词过滤和非中文字符移除。计算P(s|w),即在已知词w的情况下邮件为垃圾邮件的概率。对于仅出现在垃圾邮件词典中的词,赋予较低的P(w|s')值,反之亦然。最后,通过计算每封邮件中15个最重要的词的贝叶斯概率,根据设定的阈值α来判断邮件类型。
5. 核心代码:
提供了一个名为`spamEmailBayes`的类,其中包含两个关键函数:`getStopWords`用于加载中文停用词表,另一个未给出名称的功能函数负责实际的邮件分类逻辑,它会统计词频,执行特征提取,然后依据贝叶斯公式进行分类决策。
这份文档提供了使用贝叶斯分类器对中文邮件进行垃圾邮件检测的完整过程,包括数据预处理、特征工程和模型训练的详细步骤。这对于希望了解和实践贝叶斯文本分类算法的人来说是一份宝贵的资源。
基于贝叶斯的简单垃圾邮件分类
1.1 题目的主要研究内容
(1)工作的主要描述
利用贝叶斯模型实现简单的垃圾邮件分类,将正常邮件和垃圾邮件分别识
别出来并分类。
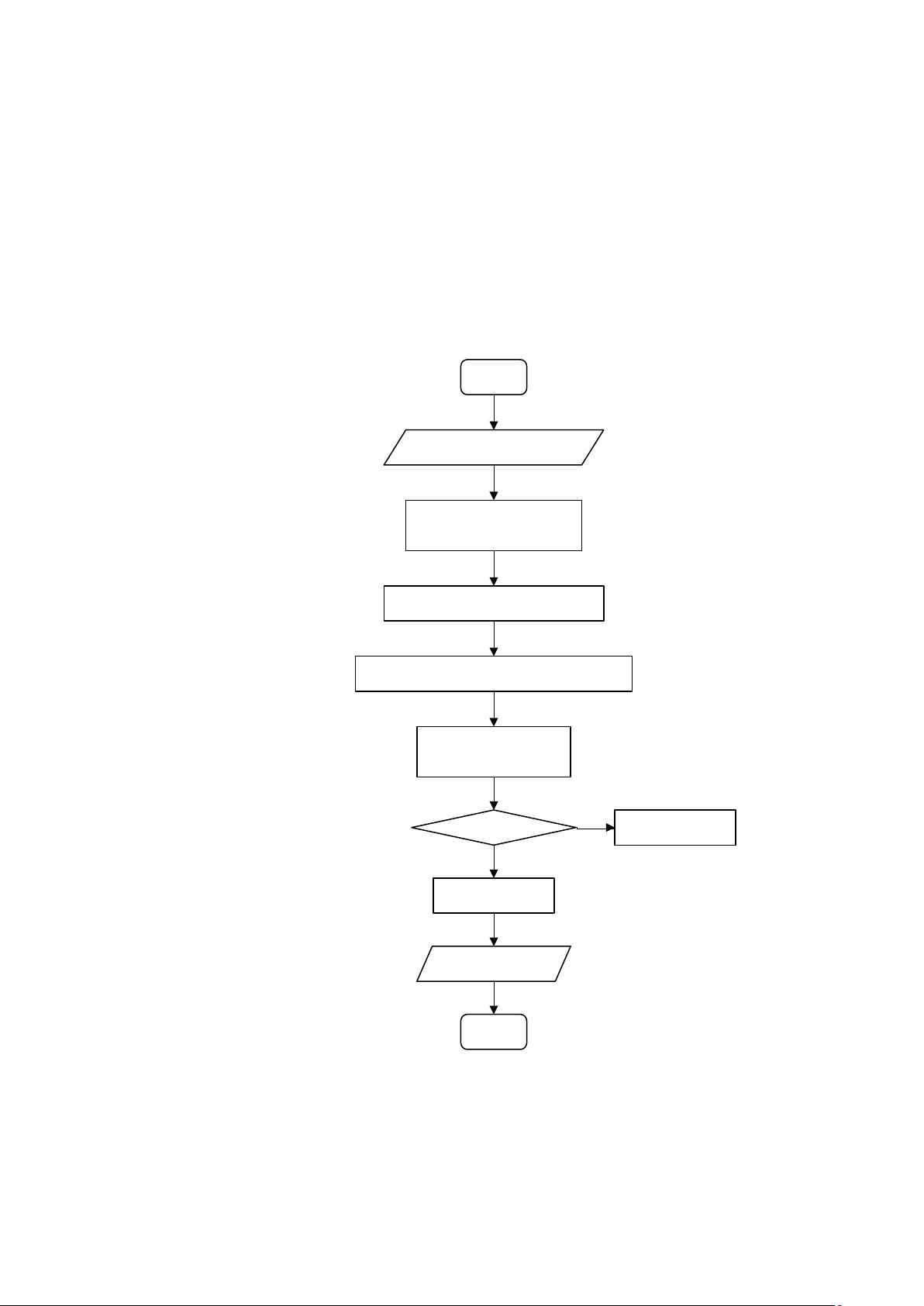
(2)系统流程图
获取中文停用词表及邮件内容
过滤非中文、剔除停用
词,获得邮件分词结果
保存正常、垃圾邮件两个词典
计算每封邮件中重要
的15个词的P(s|w)
计算得到测试集中P(s|w)最高的15个词
开始
判为垃圾邮件1
P(s|w)>阈值?
判为正常邮件0
否
是
计算分类准确率
结束
1.2 题目研究的工作基础或实验条件
软件环境:Windows10
Python 版本:3.7
下载后可阅读完整内容,剩余7页未读,立即下载
2022-10-19 上传
2022-10-19 上传
2024-06-30 上传
2024-06-30 上传
2022-05-30 上传
2023-03-21 上传
2023-03-23 上传
2022-10-18 上传
2022-10-18 上传

李逍遥敲代码
- 粉丝: 2996
- 资源: 277
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android圆角进度条控件的设计与应用
- mui框架实现带侧边栏的响应式布局
- Android仿知乎横线直线进度条实现教程
- SSM选课系统实现:Spring+SpringMVC+MyBatis源码剖析
- 使用JavaScript开发的流星待办事项应用
- Google Code Jam 2015竞赛回顾与Java编程实践
- Angular 2与NW.js集成:通过Webpack和Gulp构建环境详解
- OneDayTripPlanner:数字化城市旅游活动规划助手
- TinySTM 轻量级原子操作库的详细介绍与安装指南
- 模拟PHP序列化:JavaScript实现序列化与反序列化技术
- ***进销存系统全面功能介绍与开发指南
- 掌握Clojure命名空间的正确重新加载技巧
- 免费获取VMD模态分解Matlab源代码与案例数据
- BuglyEasyToUnity最新更新优化:简化Unity开发者接入流程
- Android学生俱乐部项目任务2解析与实践
- 掌握Elixir语言构建高效分布式网络爬虫
