OpenCV SVM教程:构建分类边界
需积分: 0 171 浏览量
更新于2024-08-05
收藏 464KB PDF 举报
"这篇教程介绍了如何使用OpenCV中的支持向量机(SVM)进行分类,主要涉及SVM的基本概念和在图像处理中的应用。"
在机器学习领域,支持向量机(Support Vector Machine,简称SVM)是一种有效的监督学习算法,广泛应用于二分类和多分类问题,以及回归分析。它通过构建一个能够最大化类别间隔的超平面来对数据进行划分,以降低误分类的风险。SVM的核心思想是找到一个能够使训练样本距离超平面最远的边界,这个边界被称为最大间隔。
在OpenCV中使用SVM进行分类通常包括以下步骤:
1. **准备数据**:首先,你需要在特征空间中选择一定数量的点作为输入数据。在这个例子中,选择了六个点。
2. **定义标签**:给每个输入点分配相应的标签,这一步是监督学习的关键,因为标签指示了数据的类别。例如,你可以用正负标签表示两类不同的对象。
3. **设置参数**:创建`CvSVMParams`对象,用于配置SVM的参数,如核函数类型、惩罚参数C等。这些参数会影响SVM的性能和拟合程度。
4. **训练模型**:将特征数据和对应的标签输入到`SVM::train()`函数中,这一步会执行SVM的学习过程,得到一个可以用于预测的模型。
5. **预测新样本**:训练完成后,可以使用`SVM::predict()`方法对新的未标记数据进行分类,它会返回预测的类别标签。
在OpenCV提供的示例代码中,虽然没有完整展示,但通常会涉及到加载数据、定义参数、训练SVM模型以及使用模型预测的过程。在实际应用中,数据可能来自图像像素值或其他特征提取方法,而标签则根据问题的具体需求进行设定。
SVM的一个显著优势是其能够处理高维数据,并且通过核函数技术,能够在非线性可分的数据集上实现良好的分类效果。在图像识别和计算机视觉任务中,SVM经常被用来进行物体识别、人脸识别等任务。
SVM是一种强大的工具,尤其在小样本和高维度数据的分类问题中表现突出。OpenCV提供了对SVM的接口支持,使得开发者能够方便地将其集成到各种计算机视觉应用中。理解SVM的工作原理和如何在OpenCV中使用它,对于提升机器学习项目的性能至关重要。
2016/5/22 OpenCV支撐向量機(SVM)|阿洲的程式教學
http://monkeycoding.com/?p=774 1/6
阿洲的程式教學
關於Qt、OpenCV、影像處理演算法
支撐向量機(SVM)
機器學習(Machine Learning)主要是設計算法,讓電腦能透過資料而有像人類的學習
行為,算法通常是自動分析數據,獲得規律,並利用規律對未知數據進行預測,進而
達到分類、回歸分析等目的,在影像處理上則可能是影像辨識。
依據輸入資料是否有標籤,我們分監督式學習和非監督式學習,資料有標籤的為監督
式學習,沒有標籤的為非監督式學習,舉例來說,假如輸入臉的輪廓,輪廓本身沒有
標籤,但加入每個輪廓年齡多少這個資料就是標籤。
這邊介紹支撐向量機SVM(Support Vector Machine),這是一種監督式的機器學習算
法,原先用於二元分類,比如說這封郵件是否為垃圾郵件,或是這個人是男是女,這
種二個類別的問題,但現在已擴展且廣泛應用於統計分類和回歸分析。
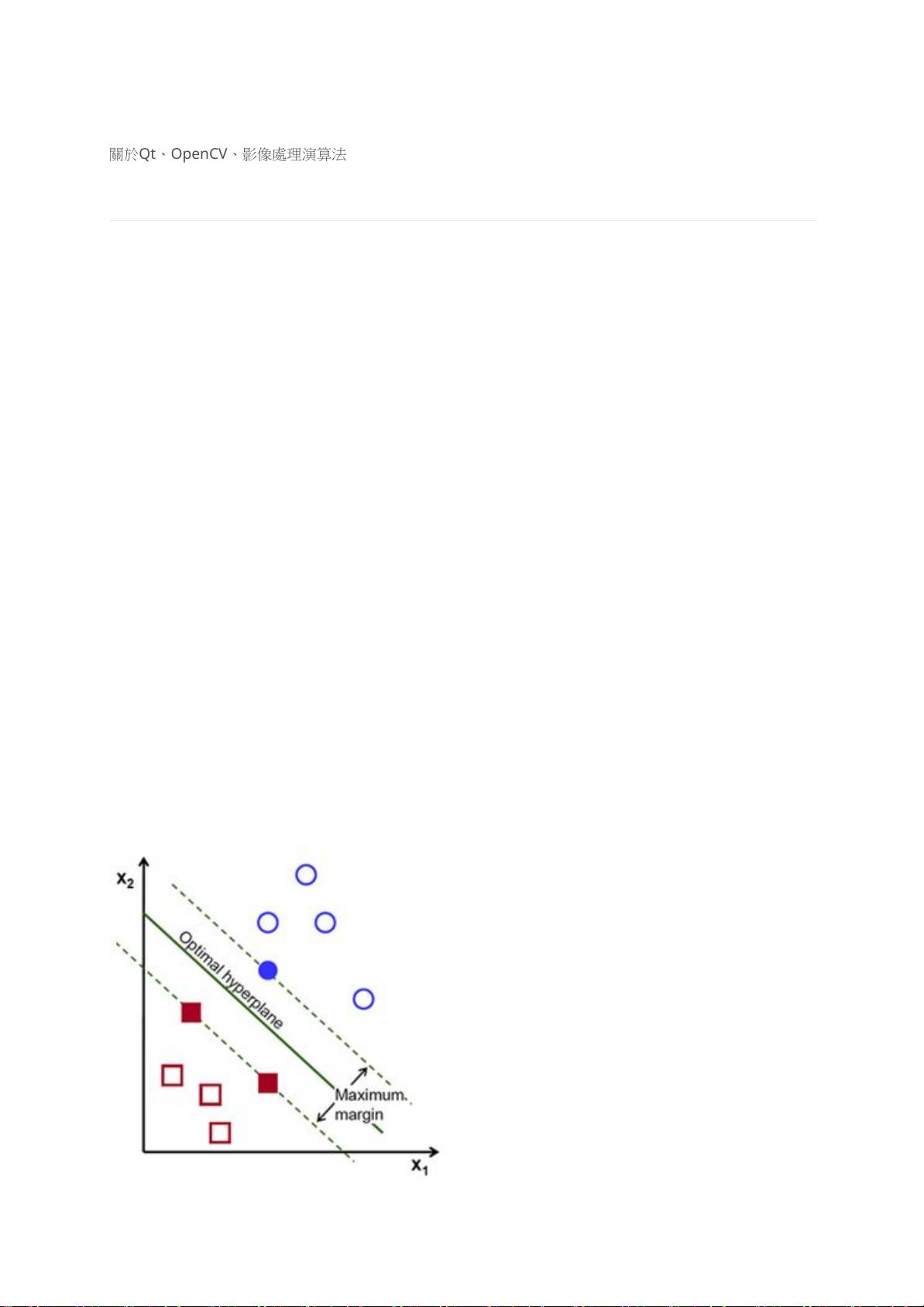
SVM建構多維的超平面來分類資料點,這個超平面即為分類邊界,直觀來說,好的分
類邊界要距離最近的訓練資料點越遠越好,因為這樣可以減低判斷錯誤的機率,而
SVM的目標即為找出間隔最大的超平面來作為分類邊界,下面為SVM的示意圖,綠線
為分類邊界,分類邊界與最近的訓練資料點之間的距離稱為間隔(margin)。
下载后可阅读完整内容,剩余5页未读,立即下载
2022-09-24 上传
2022-09-19 上传
2022-09-23 上传
2022-09-20 上传
2022-04-28 上传
2022-09-23 上传
2022-09-24 上传
2022-08-04 上传

洋葱庄
- 粉丝: 21
- 资源: 311
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握Jive for Android SDK:示例应用的使用指南
- Python中的贝叶斯建模与概率编程指南
- 自动化NBA球员统计分析与电子邮件报告工具
- 下载安卓购物经理带源代码完整项目
- 图片压缩包中的内容解密
- C++基础教程视频-数据类型与运算符详解
- 探索Java中的曼德布罗图形绘制
- VTK9.3.0 64位SDK包发布,图像处理开发利器
- 自导向运载平台的行业设计方案解读
- 自定义 Datadog 代理检查:Python 实现与应用
- 基于Python实现的商品推荐系统源码与项目说明
- PMing繁体版字体下载,设计师必备素材
- 软件工程餐厅项目存储库:Java语言实践
- 康佳LED55R6000U电视机固件升级指南
- Sublime Text状态栏插件:ShowOpenFiles功能详解
- 一站式部署thinksns社交系统,小白轻松上手
