Spark入门与进阶:从RDD到SparkSQL
下载需积分: 0 | DOCX格式 | 4.67MB |
更新于2024-06-30
| 74 浏览量 | 举报
"本章深入探讨了Apache Spark的相关知识,包括Spark的特点、高可用部署、核心组件、编程模型以及调优策略。Spark以其高效的并行计算能力,对比MapReduce展现了诸多优势,如内存计算和快速迭代。Spark的角色包括Driver、Executor和Worker,任务提交有本地模式、集群模式等。Spark-Shell提供了交互式测试环境,而Spark Streaming则用于实时流处理,具有可伸缩性和高吞吐量,可与Flume、Kafka等集成。在算子操作中,Transformations和OutputOperations是核心,例如map、filter和reduceByKey。SparkSQL支持结构化查询,能与JDBC数据源交互。Spark的核心数据抽象是Resilient Distributed Dataset (RDD),它是不可变的、分区的数据集。RDD的创建、API使用和算子操作是编程的基础,如parallelize和cache。RDD的依赖关系决定了DAG(有向无环图)的生成,进而影响任务调度。RDD通过checkpoint实现容错,保存中间结果到可靠的存储。Spark运行架构包括Master、Worker节点,以及Stage和Task的调度。最后,提到了Spark开发中的性能调优,避免重复创建和复用RDD是关键优化原则。"
这段摘要详细介绍了Apache Spark的关键概念和技术,从Spark的基本特性到其组件和运行机制,再到编程模型和调优策略,为理解Spark的工作原理和应用提供了全面的指导。Spark的核心组件如Spark-Shell、Spark Streaming和SparkSQL,以及RDD的概念和操作,都是Spark开发者必备的知识。此外,对Spark的运行架构和调度机制的介绍,有助于理解Spark如何高效地处理大规模数据。调优部分则强调了减少RDD重复创建和复用的重要性,对于提升Spark应用的性能具有实践指导价值。
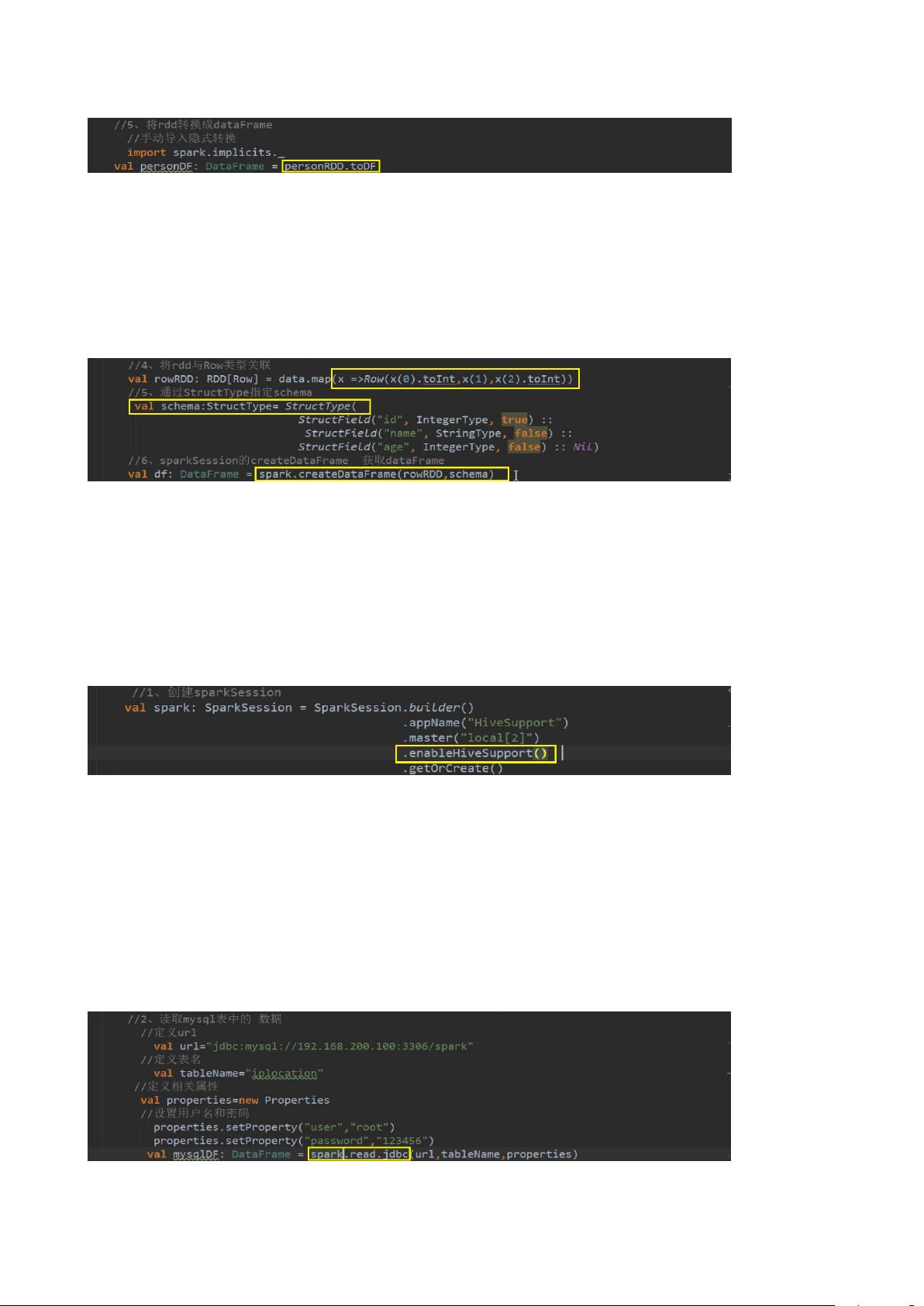
// 这种方式首先是定义样例类 Person, 然后通过将 rdd 与该样例类关联(通过样例类创建 schema,
case class 的参数名称会被利用反射机制作为列名) 生成最终的 RDD, 最后该 RDD 调用 toDF 方法
转换为 DataFrame. 有了 DataFrame 之后就可以调用各种方法来执行 spark sql 查询了
9 ② 通过 StructType 直接指定 Schema
// 这种方式首先是将 rdd 与 row 类型关联得到 rowRDD, 然后定义 structType 类型数据用来指定
schema. 最后通过 sparkSession 调用 createDataFrame 方法(含 rowRDD 以及 schema 两个参数)来
得到 DataFrame. 有了 DataFrame 之后就可以调用各种方法来执行 spark sql 查询了
2) 编写 Spark SQL 程序操作 HiveContext
// 设置为 enableHiveSupport 的 sparkSession 可以直接操作 hql (即 sparkSession 调用 sql 方
法, 里面可以直接写 hql 语句来操作)
6.1.17 JDBC 数据源
1) SparkSql 从 MySQL 中加载数据




剩余102页未读,继续阅读
相关推荐





7323
- 粉丝: 29
 我的内容管理
展开
我的内容管理
展开







最新资源
- 基于Win10和VS2017使用C++跨平台开发的技巧
- RTGraph:实时数据绘图与存储的Python应用
- Ruby-Scrolls简易日志记录工具解析
- 基于汇编语言的算术练习软件开发
- ABCnotation在Haskell中的实现解析及限制
- IncreSync:强大增量文件同步备份解决方案
- 掌握Microsoft Robotics Developer Studio中文教程
- JeeCMS-v2.0:Java版开源内容管理系统发布
- 提升效率:vim-dispatch实现异步构建与测试
- ECShop多支付插件轻松整合支付宝、微信、财付通
- GOOGLE MAPS API在WEBGIS课程作业中的应用
- C语言盒子接球游戏完整源码及运行指导
- DSA善领2011黄金版:一键配置根目录便捷使用
- 掌握IpHelper:必备头文件与lib文件教程
- QLogger:Qt多线程记录器应用详解
- 实现类似圆角ListView的textView点击效果
